
Welcome back to my series on ebpf. In the last post, we learned how to use global variables to communicate easily between user and kernel land. In this post, you’ll learn about the BPF Type Format (BTF) and how and why we generate Java code from it.
We start with the simple question of what is BTF:
VMLinux Header
In all BPF programs that we’ve written in this blog series, we included a specific header:
#include "vmlinux.h"
This header contains all of the fundamental types and definitions we need when writing our BPF programs. It contains simple definitions like the integer types used in many of the examples:
typedef unsigned int __u32; // ... typedef __u32 u32; // ...
As well as more complex types like the ethhdr struct that we used in a previous article:
struct ethhdr {
unsigned char h_dest[6];
unsigned char h_source[6];
__be16 h_proto;
};
But where does this header originate? It isn’t part of some Linux header or library, instead is the result of converting the /sys/kernel/btf/vmlinux BTF file of the current kernel into a C header using the bpftool:
bpftool btf dump file /sys/kernel/btf/vmlinux format c
This is actually the command that the build system of hello-ebpf uses to generate the file when it is not present.
The vmlinux file contains all the definitions in the BTF format and is generated when building the kernel. This format is
[…] a minimalistic, compact format, inspired by Sun’s CTF (Compact C Type Format), which is used for representing kernel debug information since Solaris 9. BTF was created for similar purposes, with a focus on simplicity and compactness to allow its usage in the Linux kernel.
Enhancing the Linux kernel with BTF type information by Andrii Nakryiko who is the leading force behind BTF
But BTF contains more than just data types, despite its name:
The name BTF was used initially to describe data types. The BTF was later extended to include function info for defined subroutines, and line info for source/line information.
The debug info is used for map pretty print, function signature, etc. The function signature enables better bpf program/function kernel symbol. The line info helps generate source annotated translated byte code, jited code and verifier log.
BPF Type Format (BTF) from Kernel.ORG
Types are represented as a tree of type nodes that each link to other types. BTF is a binary format, but we can use bpftool to not only generate matching C code, but also to emit a raw tree structure in a JSON or a slightly terser augmented format which we’ll use in the following examples.
BTF Type Tree Samples
On 6.5.0-41 kernel, vmlinux contains around 145 thousand different type nodes, plus the type node for void with id 0. Let’s pick our first example which defines the type u32 to see how a sample type tree looks like:

This is based on the raw text version:
[6] INT 'unsigned int' size=4 bits_offset=0 nr_bits=32 encoding=(none) [16] TYPEDEF '__u32' type_id=6 [24] TYPEDEF 'u32' type_id=16
TYPEDEF nodes put a name to another type, just like the typedef statement does in a C program. The INT node specifies an integer data type with size and signedness information.
Let’s look at the slightly more complex ethhdr definition:
struct ethhdr {
unsigned char h_dest[6];
unsigned char h_source[6];
__be16 h_proto;
};
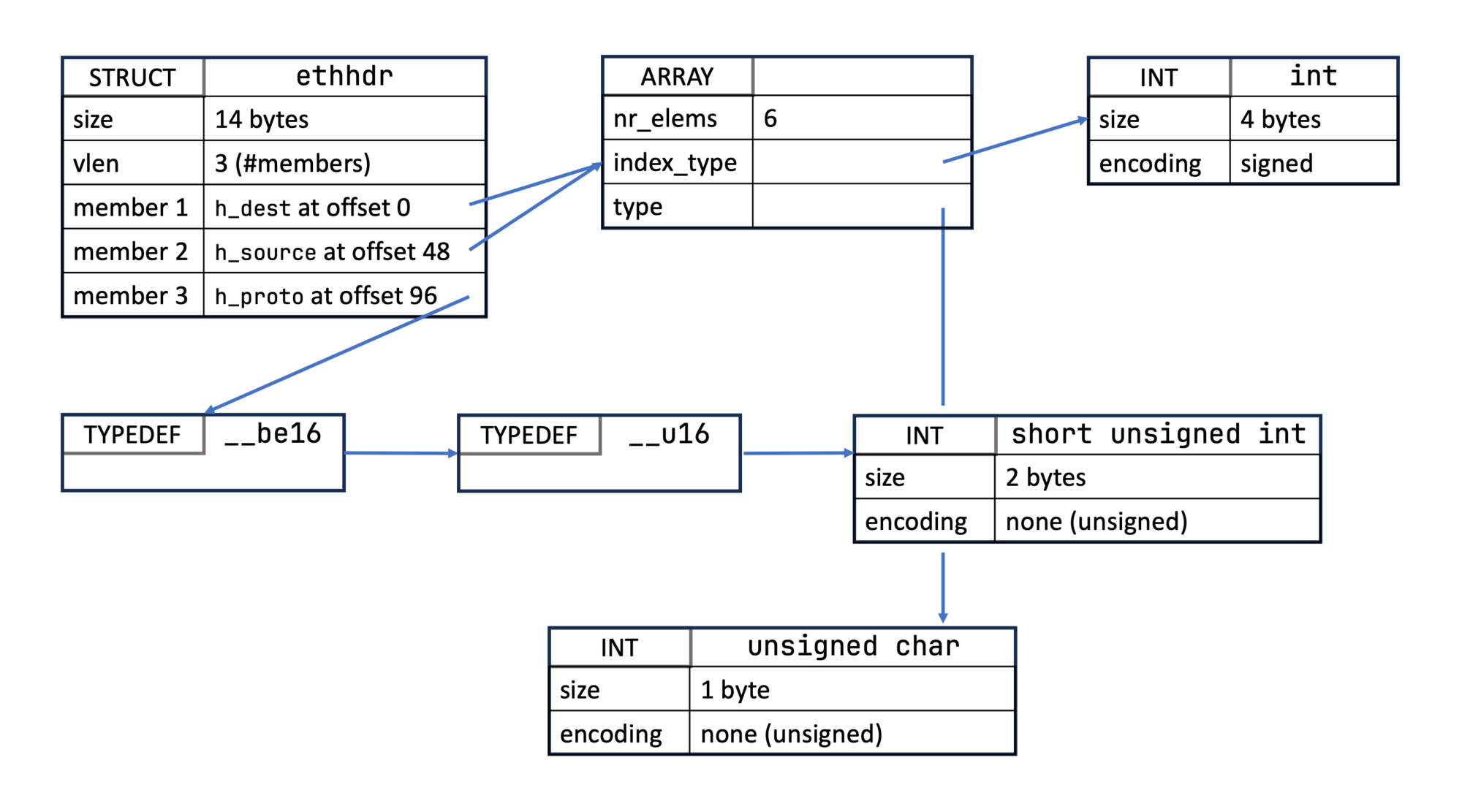
The corresponding raw text version is:
[8] INT 'int' size=4 bits_offset=0 nr_bits=32 encoding=SIGNED
[11] INT 'unsigned char' size=1 bits_offset=0 nr_bits=8 encoding=(none)
[13] TYPEDEF '__u16' type_id=14
[14] INT 'short unsigned int' size=2 bits_offset=0 nr_bits=16 encoding=(none)
[1764] TYPEDEF '__be16' type_id=13
[7095] ARRAY '(anon)' type_id=11 index_type_id=8 nr_elems=6
[10252] STRUCT 'ethhdr' size=14 vlen=3
'h_dest' type_id=7095 bits_offset=0
'h_source' type_id=7095 bits_offset=48
'h_proto' type_id=1764 bits_offset=96
You see here how STRUCT nodes define structs as a set of members at specific offsets. This is important, as this hard codes the placement of every struct and the C code generator has to infer the padding for the C code (see Hello eBPF: Auto Layouting Structs (7) for more on struct layouts). The ARRAY node has both a value type and index type, but the index is largely ignored:
The
BPF Type Format (BTF) from Kernel.ORGindex_typecan be any regular int type (u8,u16,u32,u64,unsigned __int128). The original design of includingindex_typefollows DWARF, which has anindex_typefor its array type. Currently in BTF, beyond type verification, theindex_typeis not used.
Another perculiarity to notice besides the index type, is that type nodes might reference nodes with a higher ID, which allows us to represent type cycles which might happen with recursive data structures.
With this you should have pretty good picture of what BTF this and how the type node tree looks like. There are of course more than the presented four different type node types, there is a type for pointers to other types, for unions, for enums, for every tag (const and more), forward declarations of types, functions and even floats. But I won’t cover them here for the sake of brevity. If you want to learn more about these types, read the kernel documentation, blog posts like Enhancing the Linux kernel with BTF type information by Andrii Nakryiko or btfgen-internals.md by Aqua Security. But be aware that the types in vmlinux might not make sense sometimes, like with the definition of so many different integer types, so start simple.
What can we do with all this newly gained knowledge on BTF? We can try to generate Java representations for all BTF types and functions:
Generating Java Code
To make our lives easier for this task, we assume the following:
- We’re okay with parsing and emitting the in-memory representations for all types as bit-fields and unaligned offsets, are be really hard to support.
- We can ignore ignore typedefs (but use a
@OriginalNameannotation every time the typedefed name is used)
In the actual generator we use then the JSON output of bpftool, because it is far easier to parse than the raw text version and makes debugging far easier compared to using the native libbpf parser for the BTF format.
Our generator, that you can find on GitHub, generates produces the following for the ethhdr struct:
@Type(
noCCodeGeneration = true,
cType = "struct ethhdr" // name in C
)
@NotUsableInJava // mark as eBPF only
public static class ethhdr extends Struct {
public @Unsigned char @Size(6) [] h_dest;
public @Unsigned char @Size(6) [] h_source;
public @Unsigned @OriginalName("__be16") short h_proto;
}
If you’re wondering about the placement of the annotations, please read last week’s blog post.
We can produce similar code for all other around 11600 structs, 1800 unions and 62000 function definitions resulting in inner classes grouped in 1025 classes. Combining the inner classes into classes based on prefixes makes it easier to read understand the class tree.
The resulting Java code, including additional definitions for things that I’ll cover soon, has a size of 87MB, which causes the Java compiler to require at least 16GB of heap memory and slightly less of 1GB of stack memory. This is more than many development VMs support, therefore I pushed a pre-compiled and updated version on Maven Central.
Conclusion
The BPF Type Format is an important part of the eBPF ecosystem, instrumental in being able to compile every eBPF program. In this blog post we learned what this format is and how we can use it. You might currently be bewildered by the generation of Java code, but can you guess why I need it in the future?
It’s taken a while to develop the code generation, but I’m hopefully back on my regular blogging schedule. See you in two weeks time.
This article is part of my work in the SapMachine team at SAP, making profiling and debugging easier for everyone.


")
")


")