
Welcome back to my series on ebpf. In the last blog post, we learned how to use ring buffers with libbpf for efficient communication. This week, we’re looking into the memory layout and alignment of structs transferred between the kernel and user-land.
Alignment is essential; it specifies how the compiler layouts the structs and variables and where to put the data in memory. Take, for example, the struct that we defined in the previous blog post in the RingSample:
#define FILE_NAME_LEN 256
#define TASK_COMM_LEN 16
// Structure to store the data that we want to pass to user
struct event {
u32 e_pid;
char e_filename[FILE_NAME_LEN];
char e_comm[TASK_COMM_LEN];
};
Struct Example
Using Pahole in the Compiler Explorer, we can see the memory layout on amd64:
struct event {
unsigned int e_pid; /* 0 4 */
char e_filename[256]; /* 4 256 */
/* --- cacheline 4 boundary (256 bytes) was 4 bytes ago --- */
char e_comm[16]; /* 260 16 */
/* size: 276, cachelines: 5, members: 3 */
/* last cacheline: 20 bytes */
};
This means that the know also knows how to transform member accesses to this struct and can adequately place the event in the allocated memory:

You’ve actually seen the layouting information before, as the hello-ebpf project requires you to hand layout all structs manually:
record Event(@Unsigned int pid,
@Size(FILE_NAME_LEN) String filename,
@Size(TASK_COMM_LEN) String comm) {}
// define the event records layout
private static final BPFStructType<Event> eventType =
new BPFStructType<>("rb", List.of(
new BPFStructMember<>("e_pid",
BPFIntType.UINT32, 0, Event::pid),
new BPFStructMember<>("e_filename",
new StringType(FILE_NAME_LEN),
4, Event::filename),
new BPFStructMember<>("e_comm",
new StringType(TASK_COMM_LEN),
4 + FILE_NAME_LEN, Event::comm)
), new AnnotatedClass(Event.class, List.of()),
fields -> new Event((int)fields.get(0),
(String)fields.get(1), (String)fields.get(2)));
eBPF is agnostic regarding alignment, as the compiler on your system compiles the eBPF and the C code, so the compiler can decide how to align everything.
Alignment Rules
But where do these alignment rules come from? They come from how your CPU works. Your CPU usually only allows/is optimized for certain types of accesses. So, for example, x86 CPUs are optimized for accessing 32-bit integers that lay at addresses in memory that are a multiple of four. The rules are defined in the Application Binary Interface (ABI). The alignment rules for x86 (64-bit) on Linux are specified in the System V ABI Specification:

And more, but in general, scalar types are aligned by their size. Structs, unions, and arrays are, on the other hand, aligned based on their members:
Structures and unions assume the alignment of their most strictly aligned component. Each member is assigned to the lowest available offset with the appropriate alignment. The size of any object is always a multiple of the object‘s alignment.
System V Application Binary Interface
An array uses the same alignment as its elements, except that a local or global array variable of length at least 16 bytes or a C99 variable-length array variable always has alignment of at least 16 bytes.
Structure and union objects can require padding to meet size and alignment constraints. The contents of any padding is undefined.
AMD64 Architecture Processor Supplement
Draft Version 0.99.6
ARM 64-but has the same scalar alignments and struct alignment rules (see Procedure Call Standard for the Arm® 64-bit Architecture (AArch64)); we can therefore use the same layouting algorithm for both CPU architectures.
We can formulate the algorithm for structs as follows:
struct_alignment = 1
current_position = 0
for member in struct:
# compute the position of the member
# that is properly aligned
# this introduces padding (empty space between members)
# if there are alignment issues
current_position = \
math.ceil(current_position / alignment) * member.alignment
member.position = current_position
# the next position has to be after the current member
current_position += member.size
# the struct alignment is the maximum of all alignments
struct_alignment = max(struct_alignment, member.alignment)
With this at hand, we can look at a slightly more complex example:
Struct Example with Padding
The compiler, at times, has to create an unused memory section between two members to satisfy the individual alignments. This can be seen in the following example:
struct padded_event {
char c; // single byte char, alignment of 1
long l; // alignment of 8
int i; // alignment of 4
void* x; // alignment of 8
};
Using Pahole again in the Compiler Explorer, we see the layout that the compiler generates:
struct padded_event {
char c; /* 0 1 */
/* XXX 7 bytes hole, try to pack */
long l; /* 8 8 */
int i; /* 16 4 */
/* XXX 4 bytes hole, try to pack */
void * x; /* 24 8 */
/* size: 32, cachelines: 1, members: 4 */
/* sum members: 21, holes: 2, sum holes: 11 */
/* last cacheline: 32 bytes */
};
Pahole tells us that it had to introduce 11 bytes of padding. We can visualize this as follows:
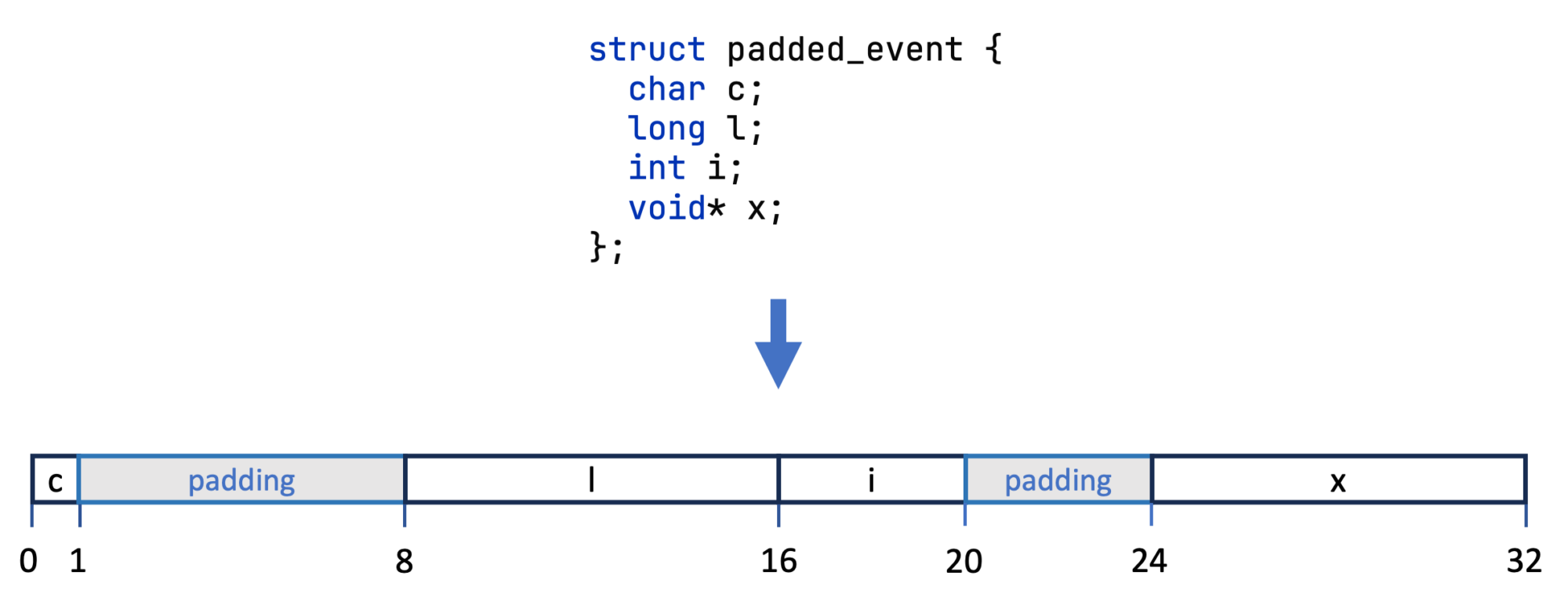
This means that we’re essentially wasting memory. I recommend reading The Lost Art of Structure Packing by Eric S. Raymond to learn more about this. If we really want to save memory, we could reorder the int with the long member, thereby only needing the padding after the char, leading to an object with 24 bytes and only 3 bytes of padding. This is really important when storing many of these structs in arrays, where the wasted memory accumulates.
But what do we do with this knowledge?
Auto-Layouting in hello-ebpf
The record that we defined in Java before contains all the information to auto-generate the BPFStructType for the class; we just need a little bit of annotation processor magic:
@Type
record Event(@Unsigned int pid,
@Size(FILE_NAME_LEN) String filename,
@Size(TASK_COMM_LEN) String comm) {}
This record is processed, and out comes the suitable BPFStructType:
We implemented the auto-layouting in the BPFStructType class to reduce the amount of logic in the annotation processor.
This results in a much cleaner RingSample version, named TypeProcessingSample:
@BPF
public abstract class TypeProcessingSample extends BPFProgram {
static final String EBPF_PROGRAM = """...""";
private static final int FILE_NAME_LEN = 256;
private static final int TASK_COMM_LEN = 16;
@Type
record Event(@Unsigned int pid,
@Size(FILE_NAME_LEN) String filename,
@Size(TASK_COMM_LEN) String comm) {}
public static void main(String[] args) {
try (TypeProcessingSample program = BPFProgram.load(TypeProcessingSample.class)) {
program.autoAttachProgram(
program.getProgramByName("kprobe__do_sys_openat2"));
// get the generated struct type
var eventType = program.getTypeForClass(Event.class);
var ringBuffer = program.getRingBufferByName("rb", eventType,
(buffer, event) -> {
System.out.printf("do_sys_openat2 called by:%s file:%s pid:%d\n",
event.comm(), event.filename(), event.pid());
});
while (true) {
ringBuffer.consumeAndThrow();
}
}
}
}
The annotation processor currently supports the following members in records:
- integer types (int, long, …), optionally annotated with
@Unsignedif unsigned - String types, annotated with
@Sizeto specify the size - Other
@Typeannotated types in the same scope @Type.Memberannotated member to specify the BPFType directly
You can find the up-to-date list in the documentation for the Type annotation.
Conclusion
We have to model all C types that we use in both eBPF and Java in Java, too; this includes placing the different members of structs in memory and keeping them properly aligned. We saw that the general algorithm behind the layouting is straightforward. This algorithm can be used in the hello-ebpf library with an annotation processor to make writing eBPF applications more concise and less error-prone.
I hope you liked this introduction to struct layouts. See you in two weeks when we start supporting more features of libbpf.
This article is part of my work in the SapMachine team at SAP, making profiling and debugging easier for everyone.

