Java Flight Recorder (JFR) is one of the main open-source profilers for Java, and the only one built directly into the OpenJDK. You can find an introduction to Java profiling in my InfoQ Unleash the Power of Open-Source Profilers article and additional information and presentation on my Profiling Talks page. Furthermore, I wrote an introduction to custom JFR events: Custom JFR Events: A Short Introduction. JFR and custom events are pretty helpful when profiling applications, this blog post gives you an example from the real world.
I was searching for some JFR-related settings on the internet when I stumbled upon the /jfr command that exists in Minecraft:
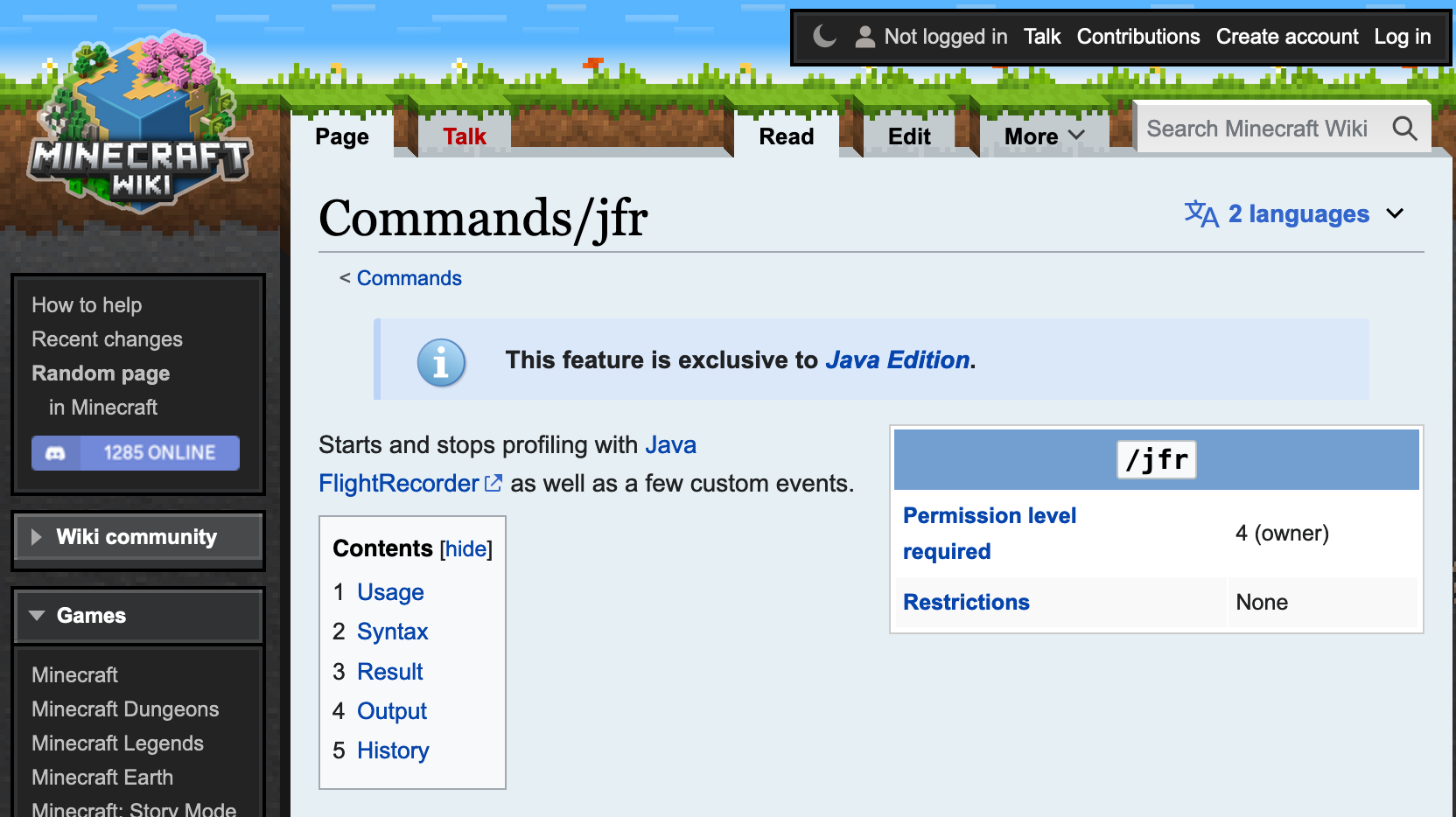
This, of course, intrigued me, especially as Minecraft apparently adds some custom JFR events:

So I had to check it out. I downloaded and started the Java server, got a demo account, and connected to my local instance. This works with a demo account when you launch the demo world, enable the cheat mode in the settings, kick yourself via “/kick @p,” and then select your own server. I found this via this bug report.
You then must ensure that you have OP privileges and add them, if not via the Minecraft server shell. Then, you can type /jfr start in the chat (launch it by typing T) to start the recording and /jfr stop to stop it.
You see that it’s my first time “playing” Minecraft, and I’m great at getting attacked. It’s probably also my last time.
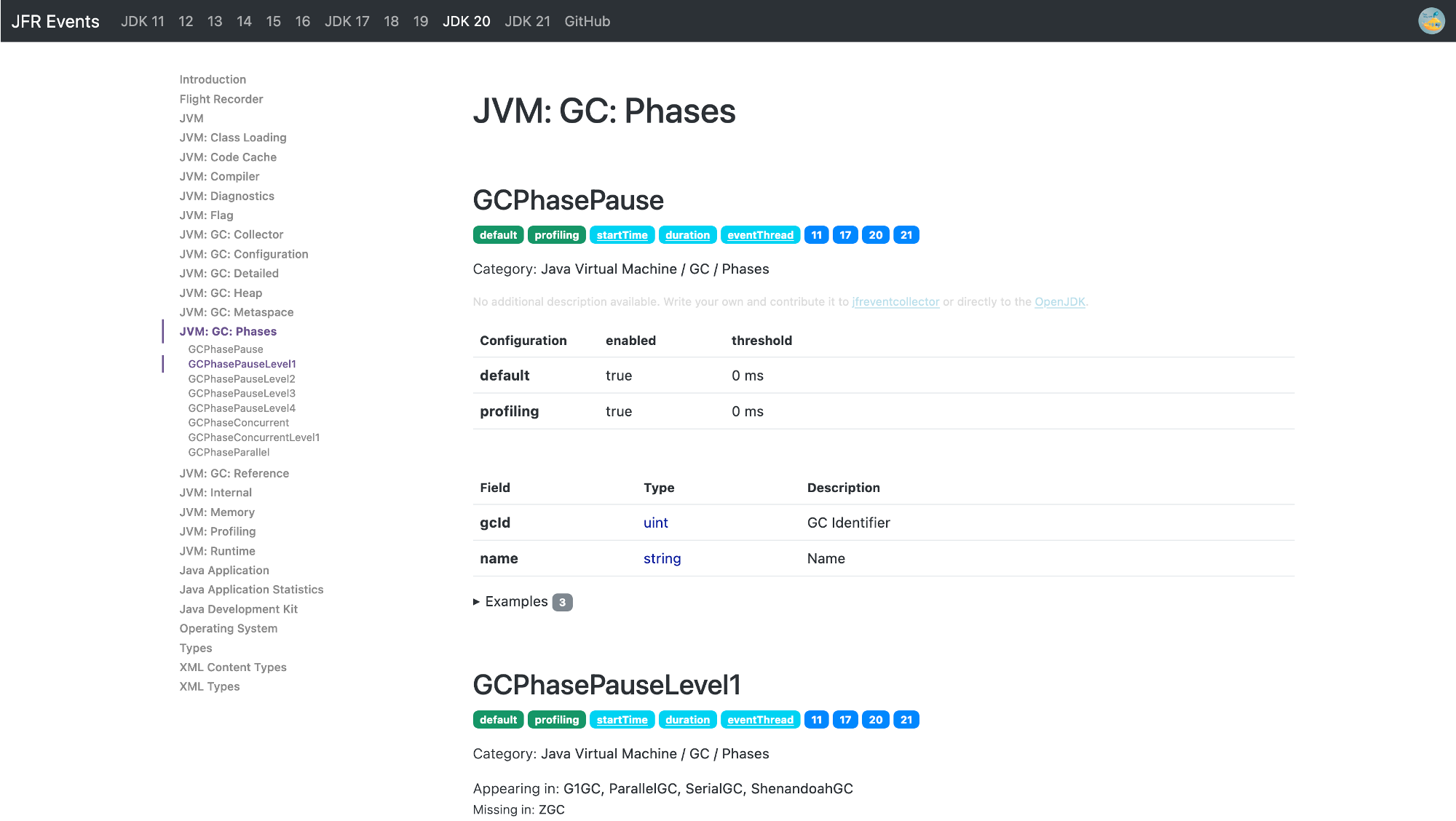
Minecraft stores the JFR file in the debug folder in the working directory of your server, both as a JFR file and as a JSON file. You can view the JFR file in a JFR viewer of your choice, like JMC or my IntelliJ JFR plugin (web view of the file, JFR file itself), and explore the custom JFR events:

This lets you get insights into the chunk generation and specific traffic patterns of the Minecraft server.
But what does the event specification look like? We could disassemble the Minecraft JAR and potentially get into legal trouble, or we could just use the jfr utility with its metadata command and get an approximation of the event definition from the JFR metadata:
jfr metadata debug/server-2023-11-17-155349.jfr | \
grep minecraft --after-context=40
The ChunkGeneration event looks as follows:
@Name("minecraft.ChunkGeneration")
@Label("Chunk Generation")
@Category({"Minecraft", "World Generation"})
class ChunkGeneration extends jdk.jfr.Event {
@Label("Start Time")
@Timestamp("TICKS")
long startTime;
@Label("Duration")
@Timespan("TICKS")
long duration;
@Label("Event Thread")
@Description("Thread in which event was committed in")
Thread eventThread;
@Label("Stack Trace")
@Description("Stack Trace starting from the method the event was committed in")
StackTrace stackTrace;
@Label("First Block X World Position")
int worldPosX;
@Label("First Block Z World Position")
int worldPosZ;
@Label("Chunk X Position")
int chunkPosX;
@Label("Chunk Z Position")
int chunkPosZ;
@Label("Status")
String status;
@Label("Level")
String level;
}
You can find all defined events here. The actual implementation of these events is only slightly larger because some events accumulate data over a period of time.
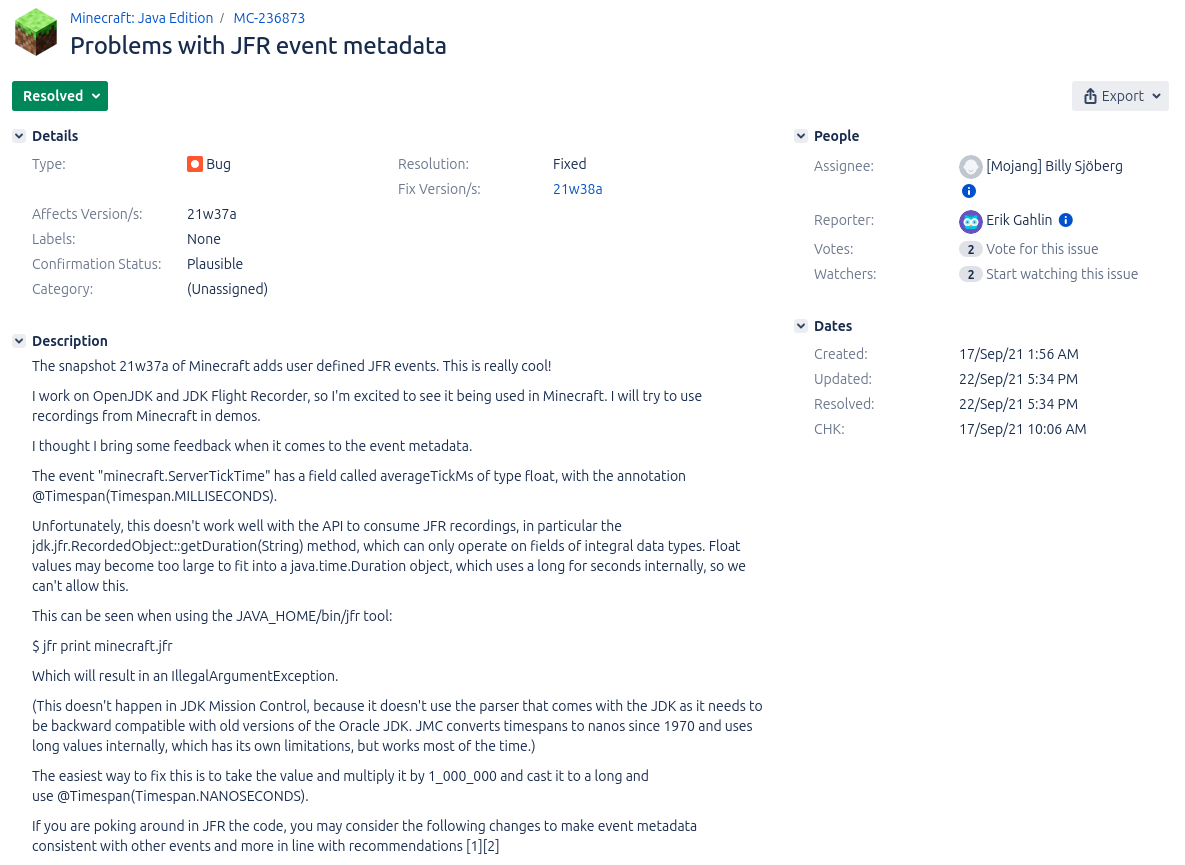
I’m, of course, not the first OpenJDK developer who stumbled upon these custom events. Erik Gahlin even found them shortly after their addition in 2021 and promptly created an issue to recommend improvements (see MC-236873):
Conclusion
In my previous blog post, I showed you how to create custom JFR events for a small sample application. Seeing custom events in Minecraft shows you that custom events are used in the wild by applications used by millions of users, helping developers improve the performance of their applications.
If you’re looking for more information on custom JFR events, I would recommend reading my previous blog post Custom JFR Events: A Short Introduction and Gunnar Morlings Monitoring REST APIs with Custom JDK Flight Recorder Events article. See you in a couple of days with a new blog post on JFR event configuration.
This article is part of my work in the SapMachine team at SAP, making profiling and debugging easier for everyone.