A Java thread in the JVM regularly checks whether it should do extra work besides the execution of the bytecode. This work is done during so-called safepoints. There are two types of safepoints: local and global. At thread-local safepoints, also known as thread-local handshakes, only the current thread does some work and is therefore blocked from executing the application. At global safepoints, all Java threads are blocked and do some work. At these safepoints, the state of the thread (thread-local safepoints) or the JVM (global safepoints) is fixed. This allows the JVM to do activities like method deoptimizations or stop-the-world garbage collections, where the amount of concurrency should be limited.
But this blog post isn’t about what (global) safepoints are; for this, please refer to Nitsan Wakart’s and Seetha Wenner’s articles on this topic and for thread-local safepoints, which are a relatively recent addition to JEP 312. I’ll cover in this post the actual implementation of safepoints in the OpenJDK and present a related bug that I found along the way.
Update: FOSDEM talk
I gave a talk on the topic of this blog post at FOSDEM 2024’s Free Java Devroom:
Implementing Safepoint Checks
Global safepoints are implemented using thread-local safepoints by stopping the threads at thread-local safepoints till all threads reach a barrier (source code), so we only have thread-local checks. Therefore I’ll only cover thread-local safepoints here and call them “safepoints.”
The simplest option for implementing safepoint checks would be to add code like
if (thread->at_safepoint()) {
SafepointMechanism::process();
}
to every location where a safepoint check should occur. The main problem is its performance. We either add lots of code or wrap it in a function and have a function call for every check. We can do better by exploiting the fact that the check often fails, so we can optimize for the fast path of “thread not at safepoint”. The OpenJDK does this by exploiting the page protection mechanisms of modern CPUs (source) in JIT compiled code:
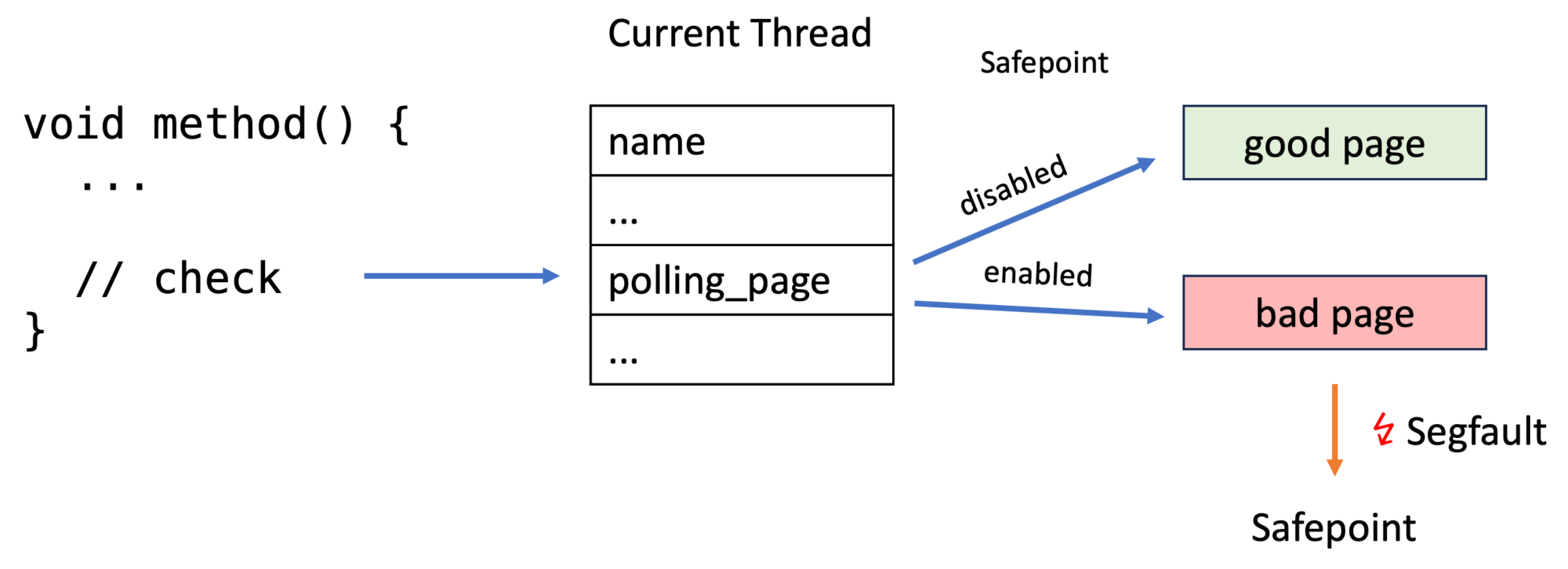
The JVM creates a good and a bad page/memory area for every thread before a thread executes any Java code (source):
char* bad_page = polling_page; char* good_page = polling_page + page_size; os::protect_memory(bad_page, page_size, os::MEM_PROT_NONE); os::protect_memory(good_page, page_size, os::MEM_PROT_READ); //... _poll_page_armed_value = reinterpret_cast<uintptr_t>(bad_page); _poll_page_disarmed_value = reinterpret_cast<uintptr_t>(good_page);
The good page can be accessed without issues, but accessing the protected bad page causes an error. os::protect_memory uses the mprotect method under the hood:
mprotect() changes the access protections for the calling process's memory pages [...]. If the calling process tries to access memory in a manner that violates the protections, then the kernel generates a SIGSEGV signal for the process. prot is a combination of the following access flags: PROT_NONE or a bitwise-or of the other values in the following list: PROT_NONE The memory cannot be accessed at all. PROT_READ The memory can be read. PROT_WRITE The memory can be modified. [...]
Now every thread has a field _polling_page which points to either the good page (safepoint check fails) or the bad page (safepoint check succeeds). The segfault handler of JVM then calls the safepoint handler code. Handling segfaults is quite expensive, but this is only used on the slow path; the fast path consists only of reading from the address that _polling_page points to.
In addition to simple safepoints, which trigger indiscriminate of the current program state, Erik Österlund added functionality to parametrize safepoints with JEP 376: The safepoint can be configured to cause a successful safepoint only if the current frame is older than the specified frame, based on the frame pointer. The frame pointer of the specified frame is called a watermark.
Keep in mind that stacks grow from higher to lower addresses. But how is this implemented? It is implemented by adding a _polling_word field next to the _poll_page field to every thread. This polling word specifies the watermark and is checked in the safepoint handler. The configured safepoints are used for incremental stack walking.
The cool thing is that (source) that when enabling the regular safepoint, one sets the watermark to 1 and for disarming it to ~1 (1111...10), so the fp > watermark is always true when the safepoint is enabled (fp > 1 is always true) and false when disabled (fp > 111...10 is always false). Therefore, we can use the same checks for both kinds of safepoints.
More on watermarks and how they can be used to reduce the latency of garbage collectors can be found in the video by Erik:
Bug with Interpreted Aarch64 Methods
The OpenJDK uses multiple compilation tiers; methods can be interpreted or compiled; see Mastering the Art of Controlling the JIT: Unlocking Reproducible Profiler Tests for more information. A common misconception is that “interpreted” means that the method is evaluated by a kind of interpreter loop that has the basic structure:
for (int i = 0; i < byteCode.length; i++) {
switch (byteCode[i].op) {
case OP_1:
...
}
}
The bytecode is actually compiled using a straightforward TemplateInterpreter, which maps every bytecode instruction to a set of assembler instructions. The compilation is fast because there is no optimization, and the evaluation is faster than a traditional interpreter.
The TemplateInterpreter adds safepoint checks whenever required, like method returns. All return instructions are mapped to assembler instructions by the TemplateTable::_return(TosState state) method. On x86, it looks like (source):
void TemplateTable::_return(TosState state) {
// ...
if (_desc->bytecode() == Bytecodes::_return_register_finalizer){
// ... // finalizers
}
if (_desc->bytecode() != Bytecodes::_return_register_finalizer){
Label no_safepoint;
NOT_PRODUCT(__ block_comment("Thread-local Safepoint poll"));
// ...
__ testb(Address(r15_thread,
JavaThread::polling_word_offset()),
SafepointMechanism::poll_bit());
// ...
__ jcc(Assembler::zero, no_safepoint);
__ push(state);
__ push_cont_fastpath();
__ call_VM(noreg, CAST_FROM_FN_PTR(address,
InterpreterRuntime::at_safepoint));
__ pop_cont_fastpath();
__ pop(state);
__ bind(no_safepoint);
}
// ...
__ remove_activation(state, rbcp);
__ jmp(rbcp);
}
This adds the safepoint check using the simple method without page faults (for some reason, I don’t know why), ensuring that a safepoint check is done at the return of every method.
We can therefore expect that when a safepoint is triggered in the interpreted_method in
interpreted_method(); compiled_method();
that the safepoint is handled at least at the end of the method; in our example, the method is too small to have any other safepoints. Yet on my M1 MacBook, the safepoint is only handled in the compiled_method. I found this while trying to fix a bug in safepoint-dependent serviceability code. The cause of the problem is that the TemplateTable::_return(TosState state) is missing the safepoint check generation on aarch64 (source):
void TemplateTable::_return(TosState state)
{
// ...
if (_desc->bytecode() == Bytecodes::_return_register_finalizer){
// ... // finalizers
}
// Issue a StoreStore barrier after all stores but before return
// from any constructor for any class with a final field.
// We don't know if this is a finalizer, so we always do so.
if (_desc->bytecode() == Bytecodes::_return)
__ membar(MacroAssembler::StoreStore);
// ...
__ remove_activation(state);
__ ret(lr);
}
And no the remove_activation method doesn’t check for the safepoint, it only checks for the safepoint (and therefore whether a watermark is set) and calls the InterpreterRuntime::at_unwind method to deal with unwinding of a frame which is related to a watermark. It does not call any safepoint handler related methods.
The same issue is prevalent in the OpenJDK’s riscv and arm ports. The real-world implications of this bug are minor, as the interpreted methods without any inner safepoint checks (in loops, calls to compiled methods, …) seldom run long enough to matter.
I’m neither an expert on the TemplateInterpreter nor on the different architectures. Maybe there are valid reasons to omit this safepoint check on ARM. But if there are not, then it should be fixed; I propose adding something like the following directly before if (_desc->bytecode() == Bytecodes::_return) for aarch64 (source):
if (_desc->bytecode() != Bytecodes::_return_register_finalizer){
Label slow_path;
Label fast_path;
__ safepoint_poll(slow_path, true /* at_return */,
false /* acquire */, false /* in_nmethod */);
__ br(Assembler::AL, fast_path);
__ bind(slow_path);
__ call_VM(CAST_FROM_FN_PTR(address,
InterpreterRuntime::at_safepoint), rthread);
__ bind(fast_path);
}
Update: Thanks to Leela Mohan Venati on Twitter for spotting that at_safepoint has to be called using call_VM and not super_call_VM_leaf, because at_safepoint is defined using JRT_ENTRY.
I’m happy to hear the opinion of any experts on this topic, the related bug is JBS-8313419.
Conclusion
Understanding the implementation of safepoints can be helpful when working on the OpenJDK. This blog post showed the inner workings, focusing on a bug in the TemplateInterpreter related to the safepoints checks.
Thank you for being with me on this journey down a rabbit hole, and see you next week with a blog post on profiling APIs.
This post is part of my work in the SapMachine team at SAP, making profiling easier for everyone. Thanks to Richard Reingruber, Matthias Baesken, Jaroslav Bachorik, Lutz Schmitz, and Aleksey Shipilëv for their invaluable input.