Please be aware that this blog post uses the discontinued libbcc-based API in hello-ebpf.
eBPF allows you to attach programs directly to hooks in the Linux kernel without loading kernel modules, like hooks for networking or executing programs. This has historically been used for writing custom package filters in firewalls. Still, nowadays, it is used for monitoring and tracing, becoming an ever more critical building block of modern observability tools. To quote from ebpf.io:
Historically, the operating system has always been an ideal place to implement observability, security, and networking functionality due to the kernel’s privileged ability to oversee and control the entire system. At the same time, an operating system kernel is hard to evolve due to its central role and high requirement towards stability and security. The rate of innovation at the operating system level has thus traditionally been lower compared to functionality implemented outside of the operating system.
eBPF changes this formula fundamentally. It allows sandboxed programs to run within the operating system, which means that application developers can run eBPF programs to add additional capabilities to the operating system at runtime. The operating system then guarantees safety and execution efficiency as if natively compiled with the aid of a Just-In-Time (JIT) compiler and verification engine. This has led to a wave of eBPF-based projects covering a wide array of use cases, including next-generation networking, observability, and security functionality.
Today, eBPF is used extensively to drive a wide variety of use cases: Providing high-performance networking and load-balancing in modern data centers and cloud native environments, extracting fine-grained security observability data at low overhead, helping application developers trace applications, providing insights for performance troubleshooting, preventive application and container runtime security enforcement, and much more. The possibilities are endless, and the innovation that eBPF is unlocking has only just begun.
Writing eBPF apps
On the lowest level, eBPF programs are compiled down to eBPF bytecode and attached to hooks in the kernel via a syscall. This is tedious; so many libraries for eBPF allow you to write applications using and interacting with eBPF in C++, Rust, Go, Python, and even Lua.
But there are none for Java, which is a pity. So… I decided to write bindings using the new Foreign Function API (Project Panama, preview in 21) and bcc, the first and widely used library for eBPF, which is typically used with its Python API and allows you to write eBPF programs in C, compiling eBPF programs dynamically at runtime.
Anyway, I’m starting my new blog series and eBPF library hello-ebpf:
Let’s discover eBPF together. Join me on the journey to write all examples from the Learning eBPF book (get it also from Bookshop.org, Amazon, or O’Reilly) by Liz Rice and more in Java, implementing a Java library for eBPF along the way, with a blog series to document the journey. I highly recommend reading the book alongside my articles; for this blog post, I read the book till page 18.
The project is still in its infancy, but I hope that we can eventually extend the overview image from ebpf.io with a duke:
Goals
The main goal is to provide a library (and documentation) for Java developers to explore eBPF and write their own eBPF programs without leaving their favorite language and runtime.
The Python API is just a wrapper around the bcc library using the built-in cffi, which extends the raw bindings to improve usability. The initial implementation of the library is a translation of the Python code to Java 21 code with Panama for FFI.
For example the following method of the Python API
def get_syscall_fnname(self, name):
name = _assert_is_bytes(name)
return self.get_syscall_prefix() + name
is translated into Java as follows:
public String get_syscall_fnname(String fnName) {
return get_syscall_prefix() + fnName;
}
This is the reason why the library has the same license as the Python API, Apache 2.0. The API is purposefully close to the Python API and only deviates where absolutely necessary, adding a few helper methods to improve it slightly. This makes it easier to work with the examples from the book and speeds up the initial development. But finishing a translation of the Python API is not the end goal:
Plans
A look ahead into the future so you know what to expect:
Implement the full API so that we can recreate all bcc examples from the book
Make it adequately available as a library on Maven Central
These plans might change, but I’ll try to keep this current. I’m open to suggestions, contributions, and ideas.
Contributing
Contributions are welcome; just open an issue or a pull request. Discussions take place in the discussions section of the GitHub repository. Please spread the word if you like it; this greatly helps the project.
I’m happy to include more example programs, API documentation, helper methods, and links to repositories and projects that use this library.
Running the first example
The Java library is still in its infancy, but we are already implementing the most basic eBPF program from the book that prints “Hello World!” every time a new program is started via the execve system call:
This helps you track the processes that use execve and lets you observe that Firefox (via MediaSu~isor) creates many processes and see whenever a Z-Shell creates a new process.
public class HelloWorld {
public static void main(String[] args) {
try (BPF b = BPF.builder("""
int hello(void *ctx) {
bpf_trace_printk("Hello, World!");
return 0;
}
""").build()) {
var syscall = b.get_syscall_fnname("execve");
b.attach_kprobe(syscall, "hello");
b.trace_print();
}
}
}
The eBPF program appends a “Hello World” trace message to the /sys/kernel/debug/tracing/trace DebugFS file via bpf_trace_printk everytime the hello method is called. The trace has the following format: “<current task, e.g. zsh>-<process id> [<CPU id the task is running on>] <options> <timestamp>: <appending ebpf method>: <actual message, like 'Hello World'>“. But bpf_trace_printk is slow, it should only be used for debugging purposes.
The Java code attaches the hello method to the execve system call and then prints the lines from the /sys/kernel/debug/tracing/trace file. The program is equivalent to the Python code from the book. But, of course, many features have not yet been implemented and so the programs you can write are quite limited.
Conclusion
eBPF is an integral part of the modern observability tech stack. The hello-ebpf Java library will allow you to write eBPF applications directly in Java for the first time. This is an enormous undertaking for a side project so it will take some time. With my new blog series, you can be part of the journey, learning eBPF and building great tools.
I plan to write a blog post every few weeks and hope you join me. You wouldn’t be the first: Mohammed Aboullaite has already entered and helped me with his eBPF expertise. The voyage will hopefully take us from the first hello world examples shown in this blog post to a fully fledged Java eBPF library.
This article is part of my work in the SapMachine team at SAP, making profiling and debugging easier for everyone. Thank you to Martin Dörr and Lukas Werling who helped in the preparation of this article.
2023 has been an adventurous year for me: I came into my blogging rhythm, blogging every one to two weeks, resulting in 39 blog posts, spoke at my first conferences, around 14 overall, 22 if you include JUGs and online conferences, and continued working on my IntelliJ plugin, as well as my proposal for a new profiling API. This blog post is a recollection of the year’s highlights. If you want a complete list of my presentations, visit my Talks page or the Presentations page in the SapMachine Wiki.
QCon London was a great experience, albeit I traveled via TGV and Eurostar on my birthday. It was only the second time that I’d been to London, so it was great to explore the city (and have my first blog post, Writing a Profiler in 240 Lines of Pure Java, on the top of the hacker news front page), visiting the British Museum and walking along the Themes:
But this wasn’t actually my first conference talk if you include my two 15-minute talks at FOSDEM 2023 in February, one of which was based on my work on Firefox Profiler:
FOSDEM is an open-source conference where a lot of different open-source communities meet:
The best thing about FOSDEM was meeting all the lovely FooJay people at the FooJay dinner, many of whom I met again at countless other conferences, like JavaZone in September:
In a bar with my fellow speakers
But more on Oslo later. Speaking at QCon London and FOSDEM was frightening, but I learned a lot in the process, so I started submitting my talks to a few conferences and user groups, resulting in my first Tour d’Europe in May/June this year:
I originally just wanted to give a talk at the JUG Milano while I was there any way on holiday with two friends. Sadly, the vacation fell through due to medical reasons, but Mario Fusco offered me a stay at his place in beautiful Gorgonzola/Milan so I could visit Milan and give my talk:
It was where I gave my first presentation in Italy. It was the first time I’ve ever been to Italy, but I hope to return with a new talk next year.
After my stop in Italy, I spoke at a meet-up in Munich, a small conference in the Netherlands, and gave three new talks at two small conferences in Karlsruhe. All in all, I gave eight talks in around two weeks. You can read more about this endeavor in my Report of my small Tour d’Europe. This was quite exhausting, so I only gave a single talk at a user group until September. But I met someone at one of the Karlsruhe conferences who told me at a dinner a month later that I should look into a new topic…
In the meantime, I used August to go on a sailing vacation in Croatia (couch sailing with Zelimir Cernelicc) and had a great time despite some rumblings regarding my JEP:
Before the vacation, I carelessly applied to a few conferences in the fall, including JavaZone in Oslo and Devoxx Belgium. Still, I would have never dreamed of being a speaker at both in my first year as a proper speaker. Being at JavaZone in September, followed by two smaller conferences in northern Germany, was excellent, especially with all the gorgeous food and getting my first duke:
and eating lunch with four of the Java architects, including Brian Goetz and Alan Bateman:
Giving a talk at such a well-known conference was a real highlight of my year:
You can see a recording here:
After Devoxx, I gave my newly created talk on Debugger internals in JUG Darmstadt and JUG Karlsruhe. This is the main talk I’ll be presenting, hopefully at conferences in 2024.
After these two JUGs, I went to Basel to give a talk at Basel One. After five conferences, two user groups, and eight blog posts, I needed a break, so I went on vacation to Bratislava, visiting a good friend there and hiking together for two days in the Tatra mountains:
Then, at the beginning of November, I gave a talk at J-Fall in the Netherlands, the biggest one-day conference in Europe:
While there, I stayed with Ties van de Ven, a speaker I first met at FOSDEM. At my first conferences, I knew no other speaker; later speaker dinners felt more like reunions:
At the speakers’ dinner at J-Fall with Simon Martinelli and Tim te Beek
While I was giving presentations and writing about Java profilers and debuggers, I also wrote a five-part series on creating a Python debugger called Let’s create a debugger together, which culminated in my first presentation at my local Python Meet-Up:
I went this year from being a frightened first-time speaker who knows nobody to somebody who traveled Europe to speak at conferences and meet-ups, both large and small, while also regularly blogging and exploring new topics. I had the opportunity to meet countless other speakers, including Marit van Dyjk and Theresa Mammerella, who helped me get better at what I do. I hope I can give something back to the community next year, helping other first-time speakers succeed.
To conclude, here is a list of my most notable blog posts:
Next year will become interesting. My first conference will be the free online Java Developer Days on Jan 17th by WeAreDevelopers, where I will give a presentation about debugging. I got accepted at FOSDEM with a talk on Python’s new monitoring API, ConFoo in Canada, JavaLand, the largest German Java conference, and Voxxed Days Zürich, and I hope for many more. But also regarding blogging: I will start a new series soon on eBPF in which we’ll explore eBPF with Java, developing a new library along the way.
I’m so grateful to my SapMachine team at SAP, which supports me in all my endeavors. Be sure to check out our website to get the best OpenJDK distribution.
Thanks for reading my blog; I hope you’ll come to one of my talks next year, write a comment, and spread the word.
This article is part of my work in the SapMachine team at SAP, making profiling and debugging easier for everyone.
JFR (JDK Flight Recorder) is the default profiler for OpenJDK (see my other blog posts for more information). What makes JFR stand out from the other profilers is the ability to log many, many different events that contain lots of information, like information on class loading, JIT compilation, and garbage collection. You can see a list of all available events on my JFR Event Collection website:
This website gives an overview of the events, with descriptions from the OpenJDK, their properties, examples, configurations, and the JDK versions in which every event is present. However, few descriptions are available, and the available texts are mostly single sentences.
TL:DR: I used GPT3.5 to create a description for every event by giving it the part of the OpenJDK source code that creates the event.
For most events, I state the lack of a description, coupled with a request that the knowledgeable reader might contribute one:
But as you can see, there is not really any progress in creating documentation. So, I have two options left:
Ask knowledgeable JDK developers to add descriptions: It’s time-consuming, and it would only be added in the next release
Write the descriptions myself directly for the website: This is pretty time-consuming, with over 150 events per JDK version.
Task AI to interpret the code that creates each event in the JDK source code.
With 1. and 2. infeasible, I started working on the AI approach, implementing it in my JFR event collector tool that collects the information displayed on the website.
I tried to use local AI models for this project but failed, so I started using GPT3.5-turbo and testing it on the OpenAI ChatGPT website. The main structure of my endeavor is as follows:
For every event, I first collect all usages and creations in the OpenJDK source, and then I construct a prompt of the following form that includes the surrounding context of the source locations:
Explain the JFR event <event> concisely so that the reader, proficient in JFR, knows the meaning and relevance of the event to profiling and its fields, without giving code snippets or referencing the code directly, take the following code as the context of its usage and keep it short and structured (and in markdown format, so format it properly to make it readable, using bullet points for field lists, but nothing else): <context>
Now some information about the event: Fields: <fields> It is <flags: experimental, internal>
Don’t mention implementation details, like methods, but explain the meaning of the event and how to use it for profiling. Keep field names lowercase and in backticks. Don’t use headings. Don’t repeat yourself. Keep it short.
For example, I asked ChatGPT the following for the ReservedStackActivation event:
Explain the JFR event ReservedStackActivation […]:
I then pass this prompt to GPT-3.5 and obtain the result:
The ReservedStackActivation event in JFR signifies a potentially dangerous stack overflow in a Java method that has been annotated with ReservedStackAccess. It is used for profiling purposes to identify methods that may be causing stack overflows.
The relevant field for this event is:
method: Represents the Java method where the potential stack overflow occurred.
My prompt and the code used to find the usage contexts, simple regular expressions without C++ parsing, is quite simplistic, but the results are somewhat usable.
But this event has also a description:
Activation of Reserved Stack Area caused by stack overflow with ReservedStackAccess annotated method in call stack
Why did I choose this event, then? Because it allows you to compare the LLM generated and the OpenJDK developer’s written description. Keep in mind that the LLM did not get passed the event description. The generated version is similar, yet more text.
You can find my implementation on GitHub (GPLv2.0 licensed) and the generated documentation on the JFR Event Collection:
Conclusion
I’m unsure whether I like or dislike the results of this experiment: It’s, on the one hand, great to generate descriptions for events that didn’t have any, using the code as the source of truth. But does it really give new insights, or is it just bloated text? I honestly don’t know whether the website needs it. Therefore, I am currently just generating it for JDK 21 and might remove the feature in the future. The AI can’t replace the insights you get by reading articles on specific events, like Gunnar Morling’s recent post on the NativeMemory events.
Do you have any opinions on this? Feel free to use the usual channels to voice your opinion, and consider improving the JFR documentation if you can.
See you next week with a blog post on something completely different yet slightly related to Panama and the reason for my work behind last week’s From C to Java Code using Panama article. Consider this as my Christmas present to my readers.
This article is part of my work in the SapMachine team at SAP, making profiling and debugging easier for everyone. Thanks to Vedran Lerenc for helping me with the LLM part of this project.
The Foreign Function & Memory API (also called Project Panama) has come a long way since it started. You can find the latest version implemented in JDK 21 as a preview feature (use --enable-preview to enable it) which is specified by the JEP 454:
By efficiently invoking foreign functions (i.e., code outside the JVM), and by safely accessing foreign memory (i.e., memory not managed by the JVM), the API enables Java programs to call native libraries and process native data without the brittleness and danger of JNI.
This is pretty helpful when trying to build wrappers around existing native libraries. Other languages, like Python with ctypes, have had this for a long time, but Java is getting a proper API for native interop, too. Of course, there is the Java Native Interface (JNI), but JNI is cumbersome and inefficient (call-sites aren’t inlined, and the overhead of converting data from Java to the native world and back is huge).
Be aware that the API is still in flux. Much of the existing non-OpenJDK documentation is not in sync.
Example
Now to my main example: Assume you’re tired of all the abstraction of the Java I/O API and just want to read a file using the traditional I/O functions of the C standard lib (like read_line.c): we’re trying to read the first line of the passed file, opening the file via fopen, reading the first line via gets, and closing the file via fclose.
This would have involved writing C code in the old JNI days, but we can access the required C functions directly with Panama, wrapping the C functions and writing the C program as follows in Java:
public static void main(String[] args) {
var file = fopen(args[0], "r");
var line = gets(file, 1024);
System.out.println(line);
fclose(file);
}
But do we implement the wrapper methods? We start with the FILE* fopen(char* file, char* mode) function which opens a file. Before we can call it, we have to get hold of its MethodHandle:
This looks up the fopen symbol in all the libraries that the current process has loaded, asking both the NativeLinker and the SymbolLookup. This code is used in many examples, so we move it into the function lookup:
The look-up returns the memory address at which the looked-up function is located.
We can proceed with the address of fopen and use it to create a MethodHandle that calls down from the JVM into native code. For this, we also have to specify the descriptor of the function so that the JVM knows how to call the fopen handle properly.
But how do we use this handle? Every handle has an invokeExact function (and an invoke function that allows the JVM to convert data) that we can use. The only problem is that we want to pass strings to the fopen call. We cannot pass the strings directly but instead have to allocate them onto the C heap, copying the chars into a C string:
In JDK 22 allocateUtf8String changes to allocateFrom (thanks Brice Dutheil for spotting this).
We use a confined arena for allocations, which is cleaned after exiting the try-catch. The newly allocated strings are then used to invoke fopen, letting us return the FILE*.
Older tutorials might mention MemorySessions, but they are removed in JDK 21.
After opening the file, we can focus on the char* fgets(char* buffer, int size, FILE* file) function. This function is passed a buffer of a given size, storing the next line from the passed file in the buffer.
Only the wrapper method differs because we have to allocate the buffer in the arena:
public static String gets(MemorySegment file, int size) {
try (var arena = Arena.ofConfined()) {
var buffer = arena.allocateArray(ValueLayout.JAVA_BYTE, size);
var ret = (MemorySegment) fgets.invokeExact(buffer, size, file);
if (ret == MemorySegment.NULL) {
return null; // error
}
return buffer.getUtf8String(0);
} catch (Throwable t) {
throw new RuntimeException(t);
}
}
Finally, we can implement the int fclose(FILE* file) function to close the file:
private static MethodHandle fclose = Linker.nativeLinker().downcallHandle(
PanamaUtil.lookup("fclose"),
FunctionDescriptor.of(ValueLayout.JAVA_INT, ValueLayout.ADDRESS));
public static int fclose(MemorySegment file) {
try {
return (int) fclose.invokeExact(file);
} catch (Throwable e) {
throw new RuntimeException(e);
}
}
You can find the source code in my panama-examples repository on GitHub (file HelloWorld.java) and run it on a Linux x86_64 machine via
> ./run.sh HelloWorld LICENSE # build and run
Apache License
which prints the first line of the license file.
Errno
We didn’t care much about error handling here, but sometimes, we want to know precisely why a C function failed. Luckily, the C standard library on Linux and other Unixes has errno:
Several standard library functions indicate errors by writing positive integers to errno.
On error, fopen returns a null pointer and sets errno. You can find information on all the possible error numbers on the man page for the open function.
We only have to have a way to obtain the errno directly after a call, we have to capture the call state and declare the capture-call-state option in the creation of the MethodHandle for fopen:
try (var arena = Arena.ofConfined()) {
// declare the errno as state to be captured,
// directly after the downcall without any interence of the
// JVM runtime
StructLayout capturedStateLayout = Linker.Option.captureStateLayout();
VarHandle errnoHandle =
capturedStateLayout.varHandle(
MemoryLayout.PathElement.groupElement("errno"));
Linker.Option ccs = Linker.Option.captureCallState("errno");
MethodHandle fopen = Linker.nativeLinker().downcallHandle(
lookup("fopen"),
FunctionDescriptor.of(POINTER, POINTER, POINTER),
ccs);
MemorySegment capturedState = arena.allocate(capturedStateLayout);
try {
// reading a non-existent file, this will set the errno
MemorySegment result =
(MemorySegment) fopen.invoke(capturedState,
// for our example we pick a file that doesn't exist
// this ensures a proper error number
arena.allocateUtf8String("nonexistent_file"),
arena.allocateUtf8String("r"));
int errno = (int) errnoHandle.get(capturedState);
System.out.println(errno);
return result;
} catch (Throwable e) {
throw new RuntimeException(e);
}
}
// returned char* require this specific type
static AddressLayout POINTER =
ValueLayout.ADDRESS.withTargetLayout(
MemoryLayout.sequenceLayout(JAVA_BYTE));
static MethodHandle strerror = Linker.nativeLinker()
.downcallHandle(lookup("strerror"),
FunctionDescriptor.of(POINTER,
ValueLayout.JAVA_INT));
static String errnoString(int errno){
try {
MemorySegment str =
(MemorySegment) strerror.invokeExact(errno);
return str.getUtf8String(0);
} catch (Throwable t) {
throw new RuntimeException(t);
}
}
When we then print the error string in our example after the fopen call, we get:
No such file or directory
This is as expected, as we hard-coded a non-existent file in the fopen call.
JExtract
Creating all the MethodHandles manually can be pretty tedious and error-prone. JExtract can parse header files, generating MethodHandles and more automatically. You can download jextract on the project page.
For our example, I wrote a small wrapper around jextract that automatically downloads the latest version and calls it on the misc/headers.h file to create MethodHandles in the class Lib. The headers file includes all the necessary headers to run examples:
Of course, we still have to take care of the string allocation in our wrapper, but this wrapper gets significantly smaller:
public static MemorySegment fopen(String filename, String mode) {
try (var arena = Arena.ofConfined()) {
// using the MethodHandle that has been generated
// by jextract
return Lib.fopen(
arena.allocateUtf8String(filename),
arena.allocateUtf8String(mode));
}
}
You can find the example code in the GitHub repository in the file HelloWorldJExtract.java. I integrated jextract via a wrapper directly into the Maven build process, so just mvn package to run the tool.
More Information
There are many other resources on Project Panama, but be aware that they might be dated. Therefore, I recommend reading JEP 454, which describes the newly introduced API in great detail. Additionally, the talk “The Panama Dojo: Black Belt Programming with Java 21 and the FFM API” by Per Minborg at this year’s Devoxx Belgium is a great introduction:
As well as the talk by Maurizio Cimadamore at this year’s JVMLS:
Conclusion
Project Panama greatly simplifies interfacing with existing native libraries. I hope it will gain traction after leaving the preview state with the upcoming JDK 22, but it should already be stable enough for small experiments and side projects.
I hope my introduction gave you a glimpse into Panama; as always, I’m happy for any comments, and I’ll see you next week(ish) for the start of a new blog series.
This article is part of my work in the SapMachine team at SAP, making profiling and debugging easier for everyone. Thank you to my colleague Martin Dörr, who helped me with Panama and ported Panama to PowerPC.
Or: I just released version 0.0.11 with a cool new feature that I can’t wait to tell you about…
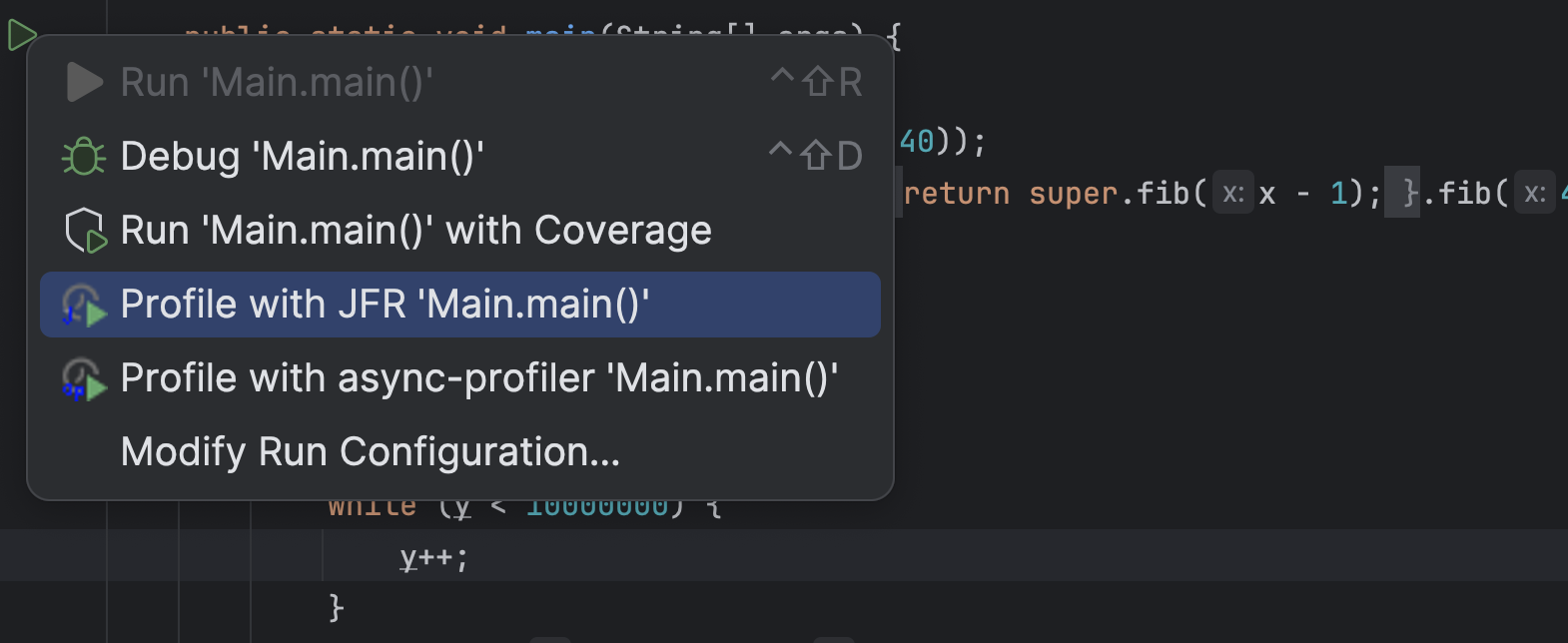
According to the recent JetBrains survey, most people use Maven as their build system and build Spring Boot applications with Java. Yet my profiling plugin for IntelliJ only supports profiling pure Java run configuration. Configurations where the JVM gets passed the main class to run. This is great for tiny examples where you directly right-click on the main method and profile the whole application using the context menu:
But this is not great when you’re using the Maven build system and usually run your application using the exec goal, or, god forbid, use Spring Boot or Quarkus-related goals. Support for these goals has been requested multiple times, and last week, I came around to implementing it (while also two other bugs). So now you can profile your Spring Boot, like the Spring pet-clinic, application running with spring-boot:run:
Giving you a profile like:
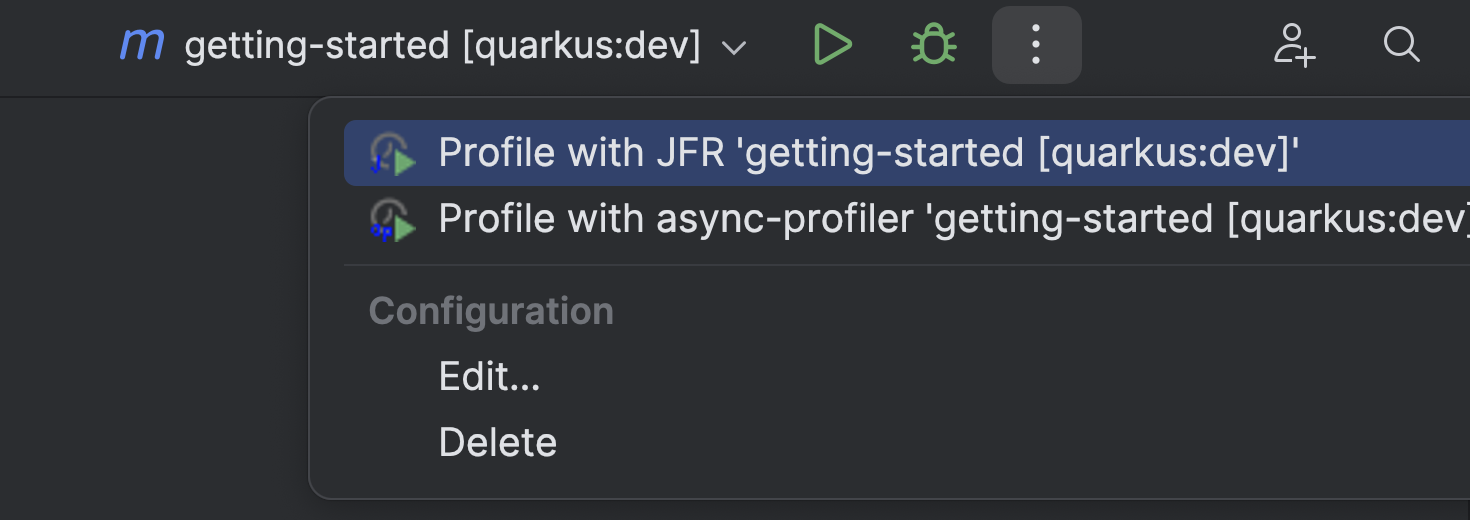
Or your Quarkus application running with quarkus:dev:
Giving you a profile like:
This works specifically by using the options of these goals, which allows the profiler plugin to pass profiling-specific JVM options. If the plugin doesn’t detect a directly supported plugin, it passes the JVM options via the MAVEN_OPTS environment variable. This should work with the exec goals and others.
Gradle script support has also been requested, but despite searching the whole internet till the night, I didn’t find any way to add JVM options to the JVM that Gradle runs for the Spring Boot or run tasks without modifying the build.gradle file itself (see Baeldung).
I left when it was dark and rode out into the night with my bike. Visiting other lost souls in the pursuit of sweet potato curry.
Only Quarku’s quarkusDev task has the proper options so that I can pass the JVM options. So, for now, I only have basic Quarkus support but nothing else. Maybe one of my readers knows how I could still provide profiling support for non-Quarkus projects.
You can configure the options that the plugin uses for specific task prefixes yourself in the .profileconfig.json file:
{
"additionalGradleTargets": [
{
// example for Quarkus
"targetPrefix": "quarkus",
"optionForVmArgs": "-Djvm.args",
"description": "Example quarkus config, adding profiling arguments via -Djvm.args option to the Gradle task run"
}
],
"additionalMavenTargets": [
{ // example for Quarkus
"targetPrefix": "quarkus:",
"optionForVmArgs": "-Djvm.args",
"description": "Example quarkus config, adding profiling arguments via -Djvm.args option to the Maven goal run"
}
]
}
This update has been the first one with new features since April. The new features should make life easier for profiling both real-world and toy applications. If you have any other feature requests, feel free to create an issue on GitHub and, ideally, try to create a pull request. I’m happy to help you get started.
See you next week on some topics I have not yet decided on. I have far more ideas than time…
This article is part of my work in the SapMachine team at SAP, making profiling and debugging easier for everyone. Thanks to the issue reporters and all the other people who tried my plugin.
Another blog post in which I use sys.settrace. This time to solve a real problem.
When working with new modules, it is sometimes beneficial to get a glimpse of which entities of a module are actually used. I wrote something comparable in my blog post Instrumenting Java Code to Find and Handle Unused Classes, but this time, I need it in Python and with method-level granularity.
TL;DR
Download trace.py from GitHub and use it to print a call tree and a list of used methods and classes to the error output:
This could be a hard problem, but it isn’t when we’re using sys.settrace to set a handler for every method and function call, reapplying the knowledge we gained in my Let’s create a debugger together series to develop a small utility.
There are essentially six different types of functions (this sample code is on GitHub):
def log(message: str):
print(message)
class TestClass:
# static initializer of the class
x = 100
def __init__(self):
# constructor
log("instance initializer")
def instance_method(self):
# instance method, self is bound to an instance
log("instance method")
@staticmethod
def static_method():
log("static method")
@classmethod
def class_method(cls):
log("class method")
def free_function():
log("free function")
This is important because we have to handle them differently in the following. But first, let’s define a few helpers and configuration variables:
We also want to print a method call-tree, so we use indent to track the current indentation level. The module_matcher is the regular expression that we use to determine whether we want to consider a module, its classes, and methods. This could, e.g., be __main__ to only consider the main module. The print_location tells us whether we want to print the path and line location for every element in the call tree.
Now to the main helper class:
def log(message: str):
print(message, file=sys.stderr)
STATIC_INIT = "<static init>"
@dataclass
class ClassInfo:
""" Used methods of a class """
name: str
used_methods: Set[str] = field(default_factory=set)
def print(self, indent_: str):
log(indent_ + self.name)
for method in sorted(self.used_methods):
log(indent_ + " " + method)
def has_only_static_init(self) -> bool:
return (
len(self.used_methods) == 1 and
self.used_methods.pop() == STATIC_INIT)
used_classes: Dict[str, ClassInfo] = {}
free_functions: Set[str] = set()
The ClassInfo stores the used methods of a class. We store the ClassInfo instances of used classes and the free function in global variables.
Now to the our call handler that we pass to sys.settrace:
def handler(frame: FrameType, event: str, *args):
""" Trace handler that prints and tracks called functions """
# find module name
module_name: str = mod.__name__ if (
mod := inspect.getmodule(frame.f_code)) else ""
# get name of the code object
func_name = frame.f_code.co_name
# check that the module matches the define regexp
if not re.match(module_matcher, module_name):
return
# keep indent in sync
# this is the only reason why we need
# the return events and use an inner trace handler
global indent
if event == 'return':
indent -= 2
return
if event != "call":
return
# insert the current function/method
name = insert_class_or_function(module_name, func_name, frame)
# print the current location if neccessary
if print_location:
do_print_location(frame)
# print the current function/method
log(" " * indent + name)
# keep the indent in sync
indent += 2
# return this as the inner handler to get
# return events
return handler
def setup(module_matcher_: str = ".*", print_location_: bool = False):
# ...
sys.settrace(handler)
Now, we “only” have to get the name for the code object and collect it properly in either a ClassInfo instance or the set of free functions. The base case is easy: When the current frame contains a local variable self, we probably have an instance method, and when it contains a cls variable, we have a class method.
def insert_class_or_function(module_name: str, func_name: str,
frame: FrameType) -> str:
""" Insert the code object and return the name to print """
if "self" in frame.f_locals or "cls" in frame.f_locals:
return insert_class_or_instance_function(module_name,
func_name, frame)
# ...
def insert_class_or_instance_function(module_name: str,
func_name: str,
frame: FrameType) -> str:
"""
Insert the code object of an instance or class function and
return the name to print
"""
class_name = ""
if "self" in frame.f_locals:
# instance methods
class_name = frame.f_locals["self"].__class__.__name__
elif "cls" in frame.f_locals:
# class method
class_name = frame.f_locals["cls"].__name__
# we prefix the class method name with "<class>"
func_name = "<class>" + func_name
# add the module name to class name
class_name = module_name + "." + class_name
get_class_info(class_name).used_methods.add(func_name)
used_classes[class_name].used_methods.add(func_name)
# return the string to print in the class tree
return class_name + "." + func_name
But how about the other three cases? We use the header line of a method to distinguish between them:
class StaticFunctionType(Enum):
INIT = 1
""" static init """
STATIC = 2
""" static function """
FREE = 3
""" free function, not related to a class """
def get_static_type(code: CodeType) -> StaticFunctionType:
file_lines = Path(code.co_filename).read_text().split("\n")
line = code.co_firstlineno
header_line = file_lines[line - 1]
if "class " in header_line:
# e.g. "class TestClass"
return StaticFunctionType.INIT
if "@staticmethod" in header_line:
return StaticFunctionType.STATIC
return StaticFunctionType.FREE
These are, of course, just approximations, but they work well enough for a small utility used for exploration.
If you know any other way that doesn’t involve using the Python AST, feel free to post in a comment below.
Using the get_static_type function, we can now finish the insert_class_or_function function:
def insert_class_or_function(module_name: str, func_name: str,
frame: FrameType) -> str:
""" Insert the code object and return the name to print """
if "self" in frame.f_locals or "cls" in frame.f_locals:
return insert_class_or_instance_function(module_name,
func_name, frame)
# get the type of the current code object
t = get_static_type(frame.f_code)
if t == StaticFunctionType.INIT:
# static initializer, the top level class code
# func_name is actually the class name here,
# but classes are technically also callable function
# objects
class_name = module_name + "." + func_name
get_class_info(class_name).used_methods.add(STATIC_INIT)
return class_name + "." + STATIC_INIT
elif t == StaticFunctionType.STATIC:
# @staticmethod
# the qualname is in our example TestClass.static_method,
# so we have to drop the last part of the name to get
# the class name
class_name = module_name + "." + frame.f_code.co_qualname[
:-len(func_name) - 1]
# we prefix static class names with "<static>"
func_name = "<static>" + func_name
get_class_info(class_name).used_methods.add(func_name)
return class_name + "." + func_name
free_functions.add(frame.f_code.co_name)
return module_name + "." + func_name
Our utility library then prints the following upon execution:
standard error:
__main__.TestClass.<static init>
__main__.all_methods
__main__.log
__main__.TestClass.__init__
__main__.log
__main__.TestClass.instance_method
__main__.log
__main__.TestClass.<static>static_method
__main__.log
__main__.TestClass.<class>class_method
__main__.log
__main__.free_function
__main__.log
********** Trace Results **********
Used classes:
only static init:
not only static init:
__main__.TestClass
<class>class_method
<static init>
<static>static_method
__init__
instance_method
Free functions:
all_methods
free_function
log
standard output:
all methods
instance initializer
instance method
static method
class method
free function
Conclusion
This small utility uses the power of sys.settrace (and some string processing) to find a module’s used classes, methods, and functions and the call tree. The utility is pretty helpful when trying to grasp the inner structure of a module and the module entities used transitively by your own application code.
I published this code under the MIT license on GitHub, so feel free to improve, extend, and modify it. Come back in a few weeks to see why I actually developed this utility…
This article is part of my work in the SapMachine team at SAP, making profiling and debugging easier for everyone.