JCmd allows you to quickly get information on an existing JVM. This helpful for getting things like thread-dumps (see jstall for tool that heavily relies on this). In this blog post you’ll learn to send JCmd diagnostic commands programmatically. You can find the whole code of this blog post on GitHub.
Let’s get a sample application running:
> java Loop.java &
[1] 23462
Now we want to obtain the VM arguments and the Java command, that’s easy on the command line via jcmd:
Or: How I use GitHub Copilot to go from feature to idea
A few weeks back, I introduced you to jstall (Quickly Inspect your Java Application with JStall), a tool that analyses what your JVM is currently doing. This week is the first time I’m bringing you in on the development and letting you peek behind the curtains to see how I go from idea to implemented feature. The feature I’ll implement the jvm-support analysis that checks that the JVM running your application is not outdated.
This is the first time I recorded my development process, so I hope you still liked it.
See you on another day for something command-line parser- or redaction-related.
This blog post is part of my work in the SapMachine team at SAP, making profiling easier for everyone.
While JFR is a great tool for profiling your application and gaining insights, the file format is, on purpose, not well documented or specified. One of the best sources of information is Gunnar Morling’s blog post on the topic, and of course, the OpenJDK source code.
But of course, there are ready-made APIs for reading JFR files and OpenJDK-adjacent libraries to write them. In this overview blog post, I’ll showcase the built-in Java JFR API, Jaroslav Bachorik’s jafar API, and the JMC JFR writer API, as well as my own basic-jfr-processor library based on the latter.
Last week, I demonstrated that OpenJDK is faster than GraalVM Java, at least for obtaining the Java version. This even prompted the mighty Thomas Wuerthinger (creator of GraalVM) to react. But the measured ~20ms for the OpenJDK is still too slow for applications like execjar, where it could significantly increase the runtime of short-running CLI tools. In this week’s brief blog post, I’ll show you the fastest way to access the Java version.
The main performance issue is that calling java -version creates a process with a fairly large (around 38MB) maximum resident set size, and using a proper command line parser. But do we actually need to call the java binary to get the version?
TL;DR: I created the java-version tool, which can obtain the Java version in under a millisecond.
Basic Idea
No, we can just realize that most Java installations have a release file that contains the relevant information in a machine-readable format. You can find this file in the main folder of the installation (./release when java is in ./bin).
Welcome to the last blog post of the year. Last week, I discussed the limitations of custom JFR events. This week, I’ll also be covering a profiling-related topic and showcasing a tiny tool called JStall.
I hope I’m not the only one who sometimes wonders: “What is my Java application doing right now?” When you don’t see any output. Yes, you could perform a simple thread dump via jstack, but it is hard to understand which threads are actually consuming CPU and making any sort of progress. This is where my tiny tool called JStall comes in:
JStall is a small command-line tool for one-shot inspection of running JVMs using thread dumps and short, on-demand profiling. The tool essentially takes multiple thread dumps of your application and uses the per-thread cpu-time information to find the most CPU-time-consuming Java threads.
First, download the JStall executable from the GitHub releases page. Let us then start by finding the currently running JVMs:
> ./jstall
Usage: jstall <command> <pid|files> [options]
Available commands:
status - Show overall status (deadlocks + most active threads)
deadlock - Check for deadlocks
most-work - Show threads doing the most work
flame - Generate flame graph
threads - List all threads
Available JVMs:
7153 ./jstall
1223 <unknown>
8136 ./renaissance-gpl-0.16.0.jar
6138 org.jetbrains.idea.maven.server.RemoteMavenServer36
5597 DeadlockDemo
49294 com.intellij.idea.Main
This provides us with a list of options for the main status command, as well as a list of JVM processes and their corresponding main classes. Let’s start checking for deadlocking:
JDK Flight Recorder (JFR) provides support for custom events as a profiler. Around two years ago, I wrote a blog post on this very topic: Custom JFR Events: A Short Introduction. These custom events are beneficial because they enable us to record additional project-specific information alongside the standard JFR events, all in the same file. We can then view and process this information with the JFR tools. You can freely specify these events in Java.
There is only one tiny problem nobody talks about: Array support (and, in more general, the support of complex types).
Over a year ago, I wrote a blog post called Who instruments the instrumenters? together with Mikaël Francoeur on how we debugged the Java instrumentation code. In the meantime, I gave a more detailed talk on this topic at VoxxedDays Amsterdam. The meta-agent that I developed for this worked well for Java agents/instrumenters, but what about native agents? Marco Sussitz found my agent and asked exactly this question. Native agents are agents that utilize the JVMTI API to, for example, modify class bytecode; however, they are not written in Java. With this blog post, I’m proud to announce that the meta-agent now supports instrumenting native agents.
TL;DR: Meta-agent allows you to see how an agent, native or Java, transforms bytecode.
There are many examples of native agents, like DynaTrace‘s monitoring agent or async-profiler‘s method tracer. I’m using the latter in my example here, as it’s open-source and readily available. The method tracer instruments the Java bytecode to trace the execution time of specific methods. You can find more about it in the async-profiler forum.
As a sample program, we use Loop.java:
public class Loop {
public static void main(String[] args)
throws InterruptedException {
while (true) Thread.sleep(1000);
}
}
Let’s trace the Thrread.sleep method and use the meta-agent to see what async-profiler does with the bytecode:
This opens a server at localhost:7071 and we check how async-profiler modified the Thread class:
So we can now instrument native agents like any other Java agent. And the part: As all Java agents are built on top of the libinstrument native agent, we can also see what any Java agent is doing. For example, we can see that the Java instrumentation agent instruments itself:
So I finally built an instrumenter that can essentially instrument my instrumentation agent, which in turn instruments other instrumentation agents. Another benefit is that the instrumenter can find every modification of any Java agent.
In my previous post, I showed you how tricky it is to compare objects from the JFR Java API. You probably wondered why I wrote about this topic. Here is the reason: In this blog post, I’ll cover how to load JFR files into a DuckDB database to allow querying profiling data with simple SQL queries, all JFR views included.
This blog post will start a small series on making JFR quack.
TL;DR
You can now use a query tool (via GitHub) to transform JFR files into similarly sized DuckDB files:
CREATE VIEW "hot-methods" AS
SELECT
(c.javaName || '.' || m.name || m.descriptor) AS "Method",
COUNT(*) AS "Samples",
format_percentage(COUNT(*) / (SELECT COUNT(*) FROM ExecutionSample)) AS "Percent"
FROM ExecutionSample es
JOIN Method m ON es.stackTrace$topMethod = m._id
JOIN Class c ON m.type = c._id
GROUP BY es.stackTrace$topApplicationMethod, c.javaName, m.name, m.descriptor
ORDER BY COUNT(*) DESC
LIMIT 25
In the last blog post, I showed you how to silence JFR’s startup messages. This week’s blog post is also related to JFR, and no, it’s not about the JFR Events website, which got a simple search bar. It’s a short blog post on comparing objects from JFR recordings in Java and why this is slightly trickier than you might have expected.
Example
Getting a JFR recording is simple; just use the RecordingStream API. We do this in the following to record an execution trace of a tight loop using JFR and store it in a list:
List<RecordedEvent> events = new ArrayList<>();
// Know when to stop the loop
AtomicBoolean running = new AtomicBoolean(true);
// We obtain one hundred execution samples
// that have all the same stack trace
final long currentThreadId = Thread.currentThread().threadId();
try (RecordingStream rs = new RecordingStream()) {
rs.enable("jdk.ExecutionSample").with("period", "1ms");
rs.onEvent("jdk.ExecutionSample", event -> {
if (event.getThread("sampledThread")
.getJavaThreadId() != currentThreadId) {
return; // don't record other threads
}
events.add(event);
if (events.size() >= 100) {
// we can signal to stop
running.set(false);
}
});
rs.startAsync();
int i = 0;
while (running.get()) { // some busy loop to produce sample
for (int j = 0; j < 100000; j++) {
i += j;
}
}
rs.stop();
}
[0.172s][info][jfr,startup] Started recording 1. No limit specified, using maxsize=250MB as default.
[0.172s][info][jfr,startup]
[0.172s][info][jfr,startup] Use jcmd 29448 JFR.dump name=1 to copy recording data to file.
when starting the Flight Recorder with -XX:StartFlightRecorder? Even though the default logging level is warning, not info?
This is what this week’s blog post is all about. After I showed you last week how to waste CPU like a Professional, this week I’ll show you how to silence JFR. Back to the problem:
As a short backstory, my profiler needed a test to check that the queue size of the sampler really increased dynamically (see Java 25’s new CPU-Time Profiler: Queue Sizing (3)), so I needed a way to let a thread spend a pre-defined number of seconds running natively on the CPU. You can find the test case in its hopefully final form here, but be aware that writing such cases is more complicated than it looks.
So here we are: In need to essentially properly waste CPU-time, preferably in user-land, for a fixed amount of time. The problem: There are only a few scant resources online, so I decided to create my own. I’ll show you seven different ways to implement a simple
void my_wait(int seconds);
method, and you’ll learn far more about this topic than you ever wanted to. That works both on Mac OS and Linux. All the code is MIT licensed; you can find it on GitHub in my waste-cpu-experiments, alongside some profiling results.
I developed, together with others, the new CPU-time profiler for Java, which is now included in JDK 25. A few weeks ago, I covered the profiler’s user-facing aspects, including the event types, configuration, and rationale, alongside the foundations of safepoint-based stack walking in JFR (see Taming the Bias: Unbiased Safepoint-Based Stack Walking). If you haven’t read those yet, I recommend starting there. In this week’s blog post, I’ll dive into the implementation of the new CPU-time profiler.
It was a remarkable coincidence that safepoint-based stack walking made it into JDK 25. Thanks to that, I could build on top of it without needing to re-implement:
The actual stack walking given a sampling request
Integration with the safepoint handler
Of course, I worked on this before, as described in Taming the Bias: Unbiased Safepoint-Based Stack Walking. But Erik’s solution for JDK 25 was much more complete and profited from his decades of experience with JFR. In March 2025, whether the new stack walker would get into JDK 25 was still unclear. So I came up with other ideas (which I’m glad I didn’t need). You can find that early brain-dump in Profiling idea (unsorted from March 2025).
In this post, I’ll focus on the core components of the new profiler, excluding the stack walking and safepoint handler. Hopefully, this won’t be the last article in the series; I’m already researching the next one.
Main Components
There are a few main components of the implementation that come together to form the profiler:
This is my actual collection of ideas from March 2025, when it was unclear whether the updated JFR sampling at safepoints made it into JDK 25. It eventually did, so I scrapped the ideas. But it offers the reader an interesting, unfiltered look into my ideas and thoughts at the time, probably only useful for people who are really into profiling and the OpenJDK. Just be aware that it is therefore a document of its time (March 2025) and doesn’t reflect the actual current implementation. Also, don’t expect any deeper explanations.
Ever wondered how the views of the jfr tool are implemented? There are views like hot-methods which gives the most used methods, or cpu-load-samples that gives you the system load over time that you can directly use on the command line:
> jfr view cpu-load-samples recording.jfr
CPU Load
Time JVM User JVM System Machine Total
------------------ ------------------ -------------------- -----------------------
14:33:29 8,25% 0,08% 29,65%
14:33:30 8,25% 0,00% 29,69%
14:33:31 8,33% 0,08% 25,42%
14:33:32 8,25% 0,08% 27,71%
14:33:33 8,25% 0,08% 24,64%
14:33:34 8,33% 0,00% 30,67%
...
This is helpful when glancing at JFR files and trying to roughly understand their contents, without loading the files directly into more powerful, but also more resource-hungry, JFR viewers.
In this short blog post, I’ll show you how the views work under the hood using JFR queries and how to use the queries with my new experimental JFR query tool.
I didn’t forget the promised blog post on implementing the new CPU-time profiler in JDK 25; it’ll come soon.
Under the hood, JFR views use a built-in query language to define all views in the view.ini file. The above is, for example, defined as:
More than three years in the making, with a concerted effort starting last year, my CPU-time profiler landed in Java with OpenJDK 25. It’s an experimental new profiler/method sampler that helps you find performance issues in your code, having distinct advantages over the current sampler. This is what this week’s and next week’s blog posts are all about. This week, I will cover why we need a new profiler and what information it provides; next week, I’ll cover the technical internals that go beyond what’s written in the JEP. I will quote the JEP 509 quite a lot, thanks to Ron Pressler; it reads like a well-written blog post in and of itself.
Before I show you its details, I want to focus on what the current default method profiler in JFR does:
Two years ago, I still planned to implement a new version of AsyncGetCallTrace in Java. This plan didn’t materialize, but Erik Österlund had the idea to fully walk the stack at safepoints during the discussions. Walking stacks only at safepoints normally would incur a safepoint-bias (see The Inner Workings of Safepoints), but when you record some program state in signal handlers, you can prevent this. I wrote about this idea and its basic implementation in Taming the Bias: Unbiased Safepoint-Based Stack Walking. I’ll revisit this topic in this week’s short blog post because Markus Grönlund took Erik’s idea and started implementing it for the standard JFR method sampler:
Around ten months ago I wrote a blog post together with Mikaël Francoeur on how to instrument instrumenters:
Have you ever wondered how libraries like Spring and Mockito modify your code at run-time to implement all their advanced features? Wouldn’t it be cool to get a peek behind the curtains? This is the premise of my meta-agent, a Java agent to instrument instrumenters, to get these insights and what this blog post is about.
This launched a website under localhost:7071 where you could view the actions of every instrument and transformer. The only problem? It’s cumbersome to use, especially programmatically. Join me in this short blog post to learn about the newest edition of meta-agent and what it can offer.
Instrumentation Handler
An idea that came up at the recent ConFoo conference in discussion with Mikaël and Jonatan Ivanov was to add a new handler mechanism to call code every time a new transformer is added or a class is instrumented. So I got to work.
If you’re here for eBPF content, this blog post is not for you. I recommend reading an article on a concurrency fuzzing scheduler at LWN.
Ever wonder how the JDK Flight Recorder (JFR) keeps track of the classes and methods it has collected for stack traces and more? In this short blog post, I’ll explore JFR tagging and how it works in the OpenJDK.
Tags
JFR files consist of self-contained chunks. Every chunk contains:
The maximum chunk size is usually 12MB, but you can configure it:
java -XX:FlightRecorderOptions:maxchunksize=1M
Whenever JFR collects methods or classes, it has to somehow tell the JFR writer which entities have been used so that their mapping can be written out. Each entity also has to have a tracing ID that can be used in the events that reference it.
This is where JFR tags come in. Every class, module, and package entity has a 64-bit value called _trace_id (e.g., classes). Which consists of both the ID and the tag. Every method has an _orig_method_idnum, essentially its ID and a trace flag, which is essentially the tag.
In a world without any concurrency, the tag could just be a single bit, telling us whether an entity is used. But in reality, an entity can be used in the new chunk while we’re writing out the old chunk. So, we need to have two distinctive periods (0 and 1) and toggle between them whenever we write a chunk.
Tagging
We can visualize the whole life cycle of a tag for a given entity:
In this example, the entity, a class, is brought into JFR by the method sampler (link) while walking another thread’s stack. This causes the class to be tagged and enqueued in the internal entity queue (and is therefore known to the JFR writer) if it hasn’t been tagged before (source):
This shows that tagging also prevents entities from being duplicated in a chunk.
Then, when a chunk is written out. First, a safepoint is requested to initialize the next period (the next chunk) and the period to be toggled so that the subsequent use of an entity now belongs to the new period and chunk. Then, the entity is written out, and its tag for the previous period is reset (code). This allows the aforementioned concurrency.
But how does it ensure that the tagged classes aren’t unloaded before they are emitted? By writing out the classes when any class is unloaded. This is simple yet effective and doesn’t need any change in the GC.
Conclusion
Tagging is used in JFR to record classes properly, methods, and other entities while also preventing them from accidentally being garbage collected before they are written out. This is a simple but memory-effective solution. It works well in the context of concurrency but assumes entities are used in the event creation directly when tagging them. It is not supported to tag the entities and then push them into the queue to later create events asynchronously. This would probably require something akin to reference counting.
Thanks for coming this far in a blog post on a profiling-related topic. I chose this topic because I wanted to know more about tagging and plan to do more of these short OpenJDK-specific posts.
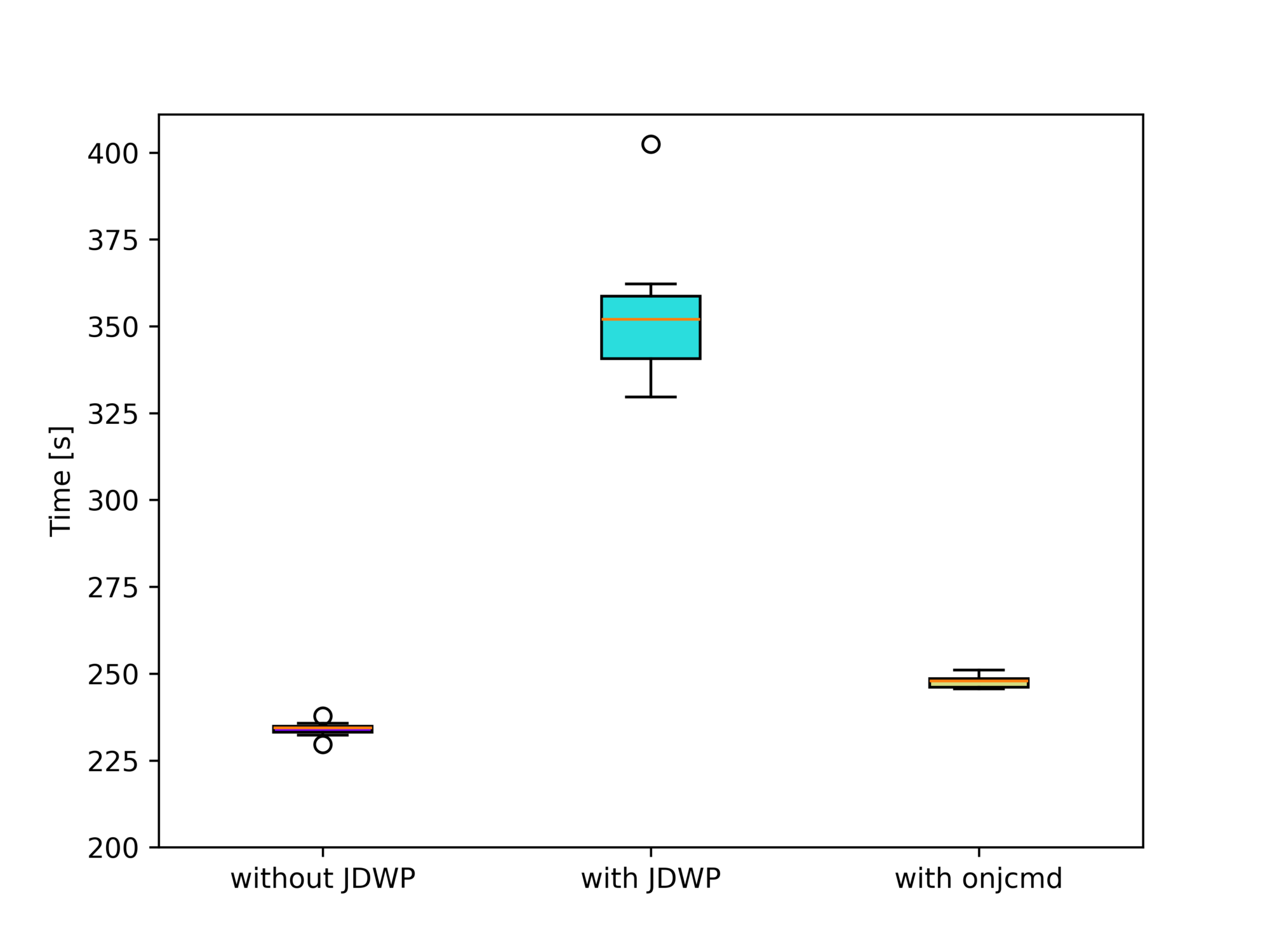
Almost to the day, a year ago, I published my blog post called Level-up your Java Debugging Skills with on-demand Debugging. In this blog post, I wrote about multiple rarely known and rarely used features of the Java debugging agent, including the onjcmd feature. To quote my own blog post:
JCmd triggered debugging
There are often cases where the code that you want to debug is executed later in your program’s run or after a specific issue appears. So don’t waste time running the debugging session from the start of your program, but use the onjcmd=y option to tell the JDWP agent to wait with the debugging session till it is triggered via jcmd.
The alternative to using this feature is to start the debugging session at the beginning and only connect to the JDWP agent when you want to start debugging. But this was, for a time, significantly slower than using the onjcmd feature (source):