
A few months ago, I told you about the onjcmd feature in my blog post Level-up your Java Debugging Skills with on-demand Debugging (which is coming to JavaLand 2024). The short version is that adding onjcmd=y to the list of JDWP options allows you to delay accepting the incoming connection request in the JDWP agent until jcmd <JVM pid> VM.start_java_debugging is called.
The main idea is that the JDWP agent
- only listens on the debugging port after it is triggered, which could have some security benefits
- and that the JDWP agent causes less overhead while waiting, compared to just accepting connections from the beginning.
The first point is debatable; one can find arguments for and against it. But for the second point, we can run some benchmarks. After renewed discussions, I started benchmarking to conclude whether the onjcmd feature improves on-demand debugging performance. Spoiler alert: It doesn’t.
Benchmarks
As for the benchmarks, I chose to run the Renaissance benchmark suite (version 0.15.0):
Renaissance is a modern, open, and diversified benchmark suite for the JVM, aimed at testing JIT compilers, garbage collectors, profilers, analyzers and other tools.
Renaissance is a benchmarking suite that contains a range of modern workloads, comprising of various popular systems, frameworks and applications made for the JVM.
Renaissance benchmarks exercise a range of programming paradigms, including concurrent, parallel, functional and object-oriented programming.
RENAISSANCE.DEV
Renaissance typically runs the sub-benchmarks in multiple iterations. Still, I decided to run the sub-benchmarks just once per Renaissance run (via -r 1) and instead run Renaissance itself ten times using hyperfine to get a proper run-time distribution. I compared three different executions of Renaissance for this blog post:
- without JDWP: Running Renaissance without any debugging enabled, to have an appropriate baseline, via java -jar renaissance.jar all -r 1
- with JDWP: Running Renaissance in debugging mode, with the JDWP agent accepting debugging connections the whole time without suspending the JVM, via java -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005 -jar renaissance.jar all -r 1
- with onjcmd: Running Renaissance in debugging mode, with the JDWP agent accepting debugging connections only after the
jcmdcall without suspending the JVM, via java -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,onjcmd=y,address=*:5005 -jar renaissance.jar all -r 1
Remember that we never start a debugging session or use jcmd, as we’re only interested in the performance of the JVM while waiting for a debugging connection in the JDWP agent.
Yes, I know that Renaissance uses different iteration numbers for the sub-benchmarks, but this should not affect the overall conclusions from the benchmark.
Results
Now to the results. For a current JDK 21 on my Ubuntu 23.10 machine with a ThreadRipper 3995WX CPU, hyperfine obtains the following benchmarks:
Benchmark 1: without JDWP
Time (mean ± σ): 211.075 s ± 1.307 s [User: 4413.810 s, System: 1438.235 s]
Range (min … max): 209.667 s … 213.361 s 10 runs
Benchmark 2: with JDWP
Time (mean ± σ): 218.985 s ± 1.924 s [User: 4533.024 s, System: 1133.126 s]
Range (min … max): 216.673 s … 222.249 s 10 runs
Benchmark 3: with onjcmd
Time (mean ± σ): 219.469 s ± 1.185 s [User: 4537.213 s, System: 1181.856 s]
Range (min … max): 217.824 s … 221.316 s 10 runs
Summary
"without JDWP" ran
1.04 ± 0.01 times faster than "with JDWP"
1.04 ± 0.01 times faster than "with onjcmd"
You can see that the run-time difference between “with JDWP” and “with onjcmd” is 0.5s, way below the standard deviations of both benchmarks. Plotting the benchmark results using box plots visualizes this fact:

Or, more analytically, Welch’s t-test doesn’t rule out the possibility of both benchmarks producing the same run-time distribution with p=0.5. There is, therefore, no measurable effect on the performance if we use the onjcmd feature. But what we do notice is that enabling the JDWP agent results in an increase in the run-time by 4%.
The question is then: Why has it been implemented in the JDK at all? Let’s run Renaissance on JDK 11.0.3, the first release supporting onjcmd.
Results on JDK 11.0.3
Here, using onjcmd results in a significant performance improvement of a factor of 1.5 (from 354 to 248 seconds) compared to running the JDWP agent without it:
Benchmark 1: without JDWP
Time (mean ± σ): 234.011 s ± 2.182 s [User: 5336.885 s, System: 706.926 s]
Range (min … max): 229.605 s … 237.845 s 10 runs
Benchmark 2: with JDWP
Time (mean ± σ): 353.572 s ± 20.300 s [User: 4680.987 s, System: 643.978 s]
Range (min … max): 329.610 s … 402.410 s 10 runs
Benchmark 3: with onjcmd
Time (mean ± σ): 247.766 s ± 1.907 s [User: 4690.555 s, System: 609.904 s]
Range (min … max): 245.575 s … 251.026 s 10 runs
Summary
"without JDWP" ran
1.06 ± 0.01 times faster than "with onjcmd"
1.51 ± 0.09 times faster than "with JDWP"
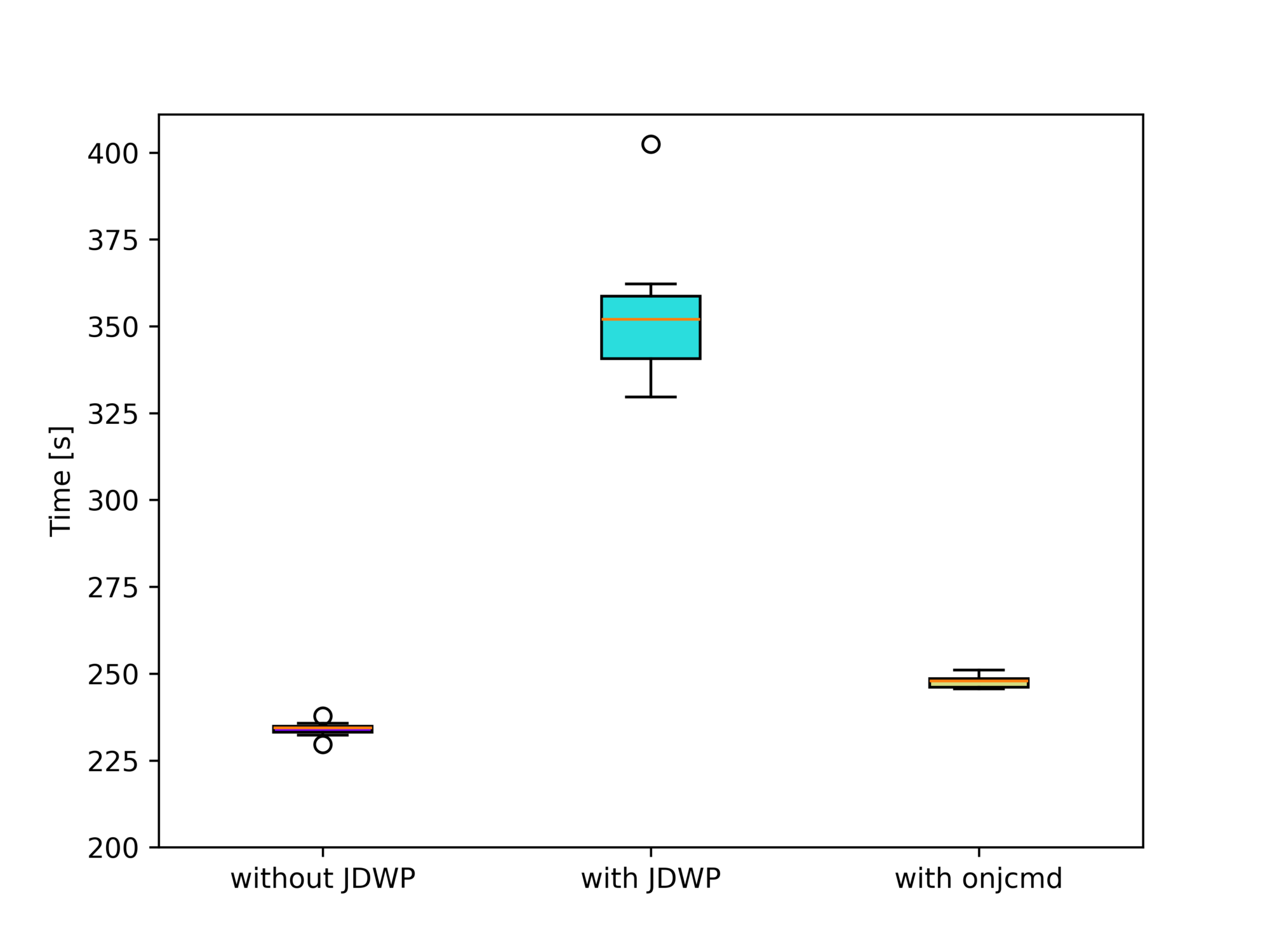
We excluded the finagle-chirper sub-benchmark here, as it causes the run-time to increase drastically. The sub-benchmark alone does not cause any problems, so the GC run possibly causes the performance hit before the sub-benchmark, which cleans up after the dotty sub-benchmark. Dotty is run directly before finagle-chirper.
Please be aware that the run sub-benchmarks on JDK 11 differ from the run on JDK 21, so don’t compare it to the results for JDK 21.
But what explains this difference?
Fixes since JDK 11.0.3
Between JDK 11.0.3 and JDK 21, there have been improvements to the OpenJDK, some of which drastically improved the performance of the JVM in debugging mode. Most notable is the fix for JDK-8227269 by Roman Kennke. The issue, reported by Egor Ushakov, reads as follows:
Slow class loading when running with JDWP
When debug mode is active (-agentlib:jdwp), an application spends a lot of time in JVM internals like Unsafe.defineAnonymousClass or Class.getDeclaredConstructors.Sometimes this happens on EDT and UI freezes occur.
If we look into the code, we’ll see that whenever a new class is loaded and an event about it is delivered, when a garbage collection has occurred, classTrack_processUnloads iterates over all loaded classes to see if any of them have been unloaded. This leads to O(classCount * gcCount) performance, which in case of frequent GCs (and they are frequent, especially the minor ones) is close to O(classCount^2). In IDEA, we have quite a lot of classes, especially counting all lambdas, so this results in quite significant overhead.
JDK-8227269
This change came into the JDK with 11.0.9. We see the 11.0.3 results with 11.0.8, but with 11.0.9, we see the results of the current JDK 11:
Benchmark 1: without JDWP
Time (mean ± σ): 234.647 s ± 2.731 s [User: 5331.145 s, System: 701.760 s]
Range (min … max): 228.510 s … 238.323 s 10 runs
Benchmark 2: with JDWP
Time (mean ± σ): 250.043 s ± 3.587 s [User: 4628.578 s, System: 716.737 s]
Range (min … max): 242.515 s … 254.456 s 10 runs
Benchmark 3: with onjcmd
Time (mean ± σ): 249.689 s ± 1.765 s [User: 4788.539 s, System: 729.207 s]
Range (min … max): 246.324 s … 251.559 s 10 runs
Summary
"without JDWP" ran
1.06 ± 0.01 times faster than "with onjcmd"
1.07 ± 0.02 times faster than "with JDWP"

This clearly shows the significant impact of the change. 11.0.3 came out on Apr 18, 2019, and 11.0.9 on Jul 15, 2020, so the onjcmd improved on-demand debugging for almost a year.
Want to try this out yourself? Get the binaries from SapMachine and run the benchmarks yourself. This kind of performance archaeology is quite rewarding, giving you insights into critical performance issues.
Conclusion
A few years ago, it was definitely a good idea to add the onjcmd feature to have usable on-demand debugging performance-wise. But nowadays, we can just start the JDWP agent to wait for a connection and connect to it whenever we want to, without any measurable performance penalty (in the Renaissance benchmark).
This shows us that it is always valuable to reevaluate if specific features are worth the maintenance cost. I hope this blog post gave you some insights into the performance of on-demand debugging. See you next week for the next installment in my hello-ebpf series.
This article is part of my work in the SapMachine team at SAP, making profiling and debugging easier for everyone.





