Or: Learn how to write a performant* Linux scheduler in 25 lines of Java code.
Welcome back to my series on ebpf. In the last post, I presented a recording of my JavaZone presentation on eBPF and a list of helpful resources for learning about the topic. Today, I’ll show you how to write a Linux scheduler in Java with eBPF. This blog post is the accompanying post to my eBPF summit keynote of the same title:
With my newest hello-ebpf addition, you can create a Linux scheduler by just implementing the methods of the Scheduler interface, allowing you to write a small scheduler with ease:
Is it really as easy as that? Of course not, at least not yet. Developing and running this scheduler requires a slightly modified version of hello-ebpf, which lives in the branch scx_demo, and a kernel patched with the sched-ext extension or a CachyOS instance with a 6.10 kernel, as well as some luck because it’s still slightly brittle.
Nonetheless, when you get it working, you can enter the wondrous world of people who build their schedulers with eBPF. You can find some of them on the sched-ext slack and many of their creation in the sched-ext/scx repository on GitHub. The kernel patches will hopefully be merged into the mainline kernel soon and will be available with version 6.12.
Before I show you how to develop a simple scheduler, I want first to give you some background:
What is scheduling?
When operating computers, you usually have the issue of multiple processes that want to run and multiple CPU cores that want to execute operations. Scheduling now dynamically distributes the processes onto the cores so that every process makes a progress. An example is a system with two processes A and B with one CPU core:
Here, the scheduler runs both processes interleaved.
Creating your own scheduler allows you to explore new scheduling policies and rapidly iterate on custom implementation. To quote Tejun Heo on why we need the sched-ext extension for the Linux kernel:
1. Ease of experimentation and exploration: Enabling rapid iteration of new scheduling policies.
2. Customization: Building application-specific schedulers which implement policies that are not applicable to general-purpose schedulers.
3. Rapid scheduler deployments: Non-disruptive swap outs of scheduling policies in production environments.
[…]
Scheduling is a challenging problem space. Small changes in scheduling behavior can have a significant impact on various components of a system, with the corresponding effects varying widely across different platforms, architectures, and workloads.
While complexities have always existed in scheduling, they have increased dramatically over the past 10-15 years. In the mid-late 2000s, cores were typically homogeneous and further apart from each other, with the criteria for scheduling being roughly the same across the entire die.
Systems in the modern age are by comparison much more complex. Modern CPU designs, where the total power budget of all CPU cores often far exceeds the power budget of the socket, with dynamic frequency scaling, and with or without chiplets, have significantly expanded the scheduling problem space.
[…]
Use-cases have become increasingly complex and diverse as well. Applications such as mobile and VR have strict latency requirements to avoid missing deadlines that impact user experience. Stacking workloads in servers is constantly pushing the demands on the scheduler in terms of workload isolation and resource distribution.
Experimentation and exploration are important for any non-trivial problem space. However, given the recent hardware and software developments, we believe that experimentation and exploration are not just important, but critical in the scheduling problem space.
Now that we have established that we probably want to be able to create our own schedulers, you might still wonder why I want to write one with hello-ebpf:
Why write a scheduler in Java?
Because I can and also because it allows me to easily create schedulers without leaving the Java ecosystem. In the future, I hope this can help solve a major problem in testing concurrent Java programs: the lack of control over the execution order of the different threads (which are processes in the Linux sense). When we control the scheduler, we can specify the execution order and degree of parallelism. This could make it easier to find and reproduce common concurrency issues like race conditions where the order of execution determines what value each of the threads sees in memory:
As well as deadlocks, which happen when two threads want to acquire the same locks in different orders:
Furthermore, one could test extreme scheduling cases, e.g., where one thread is not scheduled for one minute, and check that the program behaves as expected. This could even help find bugs in the OpenJDK itself (maybe this is a foreshadowing for a follow-up blog post if I find the time because I’m a JDK developer, after all).
After the motivation for writing schedulers in Java, I continue with a rough overview of what schedulers typically do:
Basic Idea
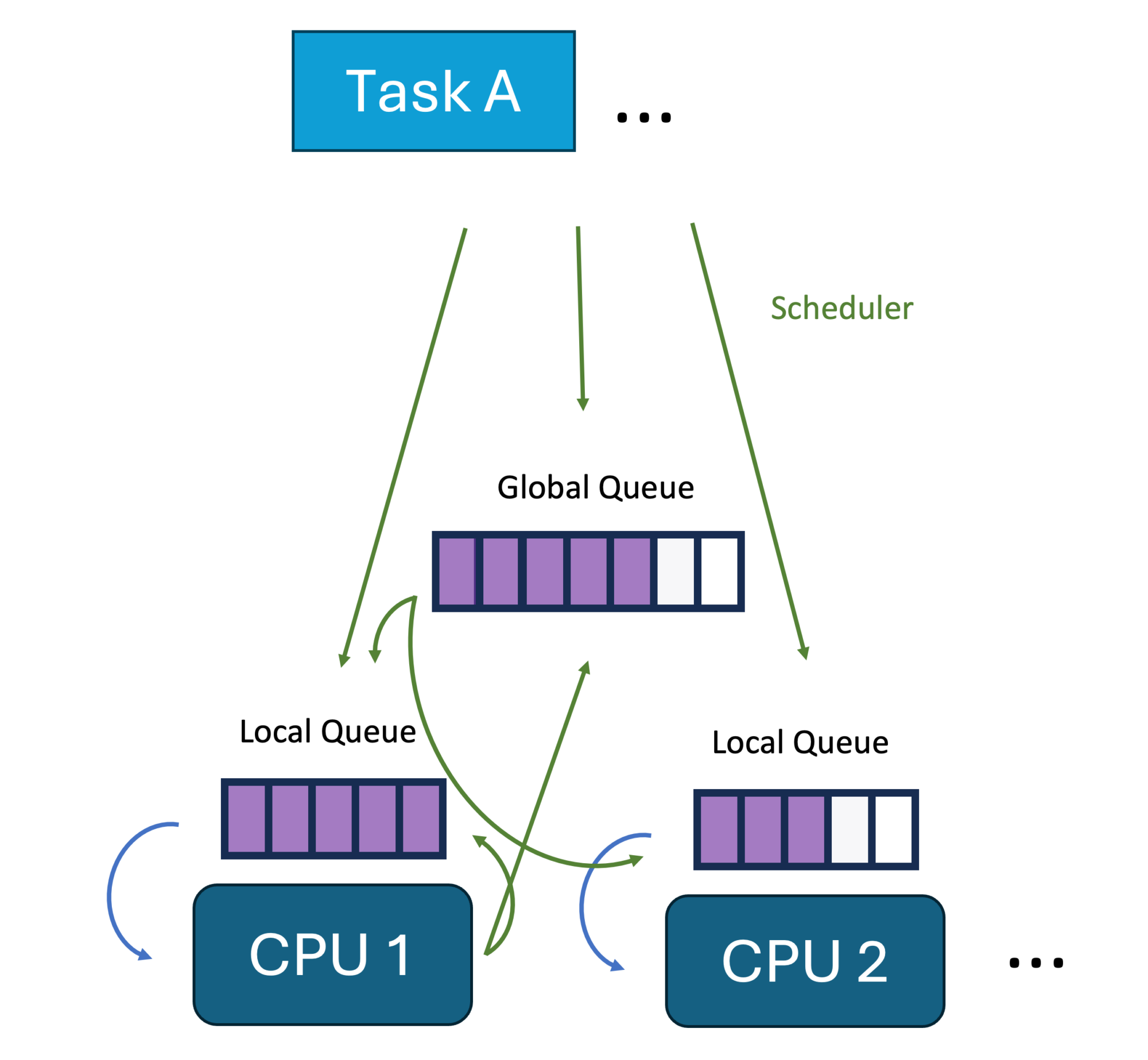
Most basic schedulers have two sets of queues: local scheduling queues per CPU each CPU uses to get the next task to execute and global queues used for inter-CPU distribution of functions. The task of the scheduler is to move the functions between the queues based on its scheduling policy:
But how does the scheduler do this? That’s what the different methods of the Scheduler Interface are for:
The Scheduler Interface
The primary data structure of sched-ext is the sched_ext_ops operations table. Implementing the Scheduler interface methods allows you to populate this table with custom methods. Let’s take a look at the different methods in the following; we see later how we can implement them to create two small schedulers. I recommend reading the ext.c kernel source file, which defines all sched-ext related methods and structs and is well documented. The following description is a shortened version of the comments on sched_ext_ops. To avoid the confusing terms “thread” and “process,” I’ll be using “task” in the following, which is the process in the Linux kernel sense of the word and effectively means a thread in most applications.
Now to the description of the methods, albeit just of the subset that is required for the small demo sampler:
int init(): Called when the scheduler is initialized, used typically to initialize scheduling queues and other data structures, might return an error code (as far as I understand).
void exit(Ptr<scx_exit_info> ei): Called when the scheduler exits, the exit info contains, for example, the exit reason.
int selectCPU(Ptr<task_struct> p, int prev_cpu, long wake_flags): Called to select the CPU for a task that is just woken up (and is soon to be scheduled). A task can be directly dispatched to an idle CPU by using the scx_bpf_dispatch() in this method, dispatching it to the returned CPU (as far as I understand). If the task is later dispatched to SCX_DSQ_LOCAL, then it will be dispatched to the scheduling CPU of the selected CPU.
void enqueue(Ptr<task_struct> p, long enq_flags): Called whenever a task is ready to be dispatched again if it is not already dispatched in selectCPU(). This method typically enqueues the task in a queue, see selectCPU, or dispatches the task directly to the selected CPU using the scx_bpf_dispatch() method.
void dispatch(int cpu, Ptr<task_struct> prev): Called when the CPU’s local scheduling queue is empty to fill it by getting a task via scx_bpf_consume() from another scheduling queue or by directly dispatching a task via scx_bpf_dispatch().
void running(Ptr<task_struct> p): Called when a task starts to run on its associated CPU.
void stopping(Ptr<task_struct> p, boolean runnable): Called when a task stops its execution on a CPU.
void enable(Ptr<task_struct> p): Called whenever a task starts to be scheduled by the currently implemented scheduler.
With this at hand, we can implement our first scheduler.
FIFO Scheduler
The First-In-First-Out (FIFO) scheduler is the first scheduler we’ll implement, based on the scx_simple from scx. This scheduler has a pretty simple policy: It schedules the tasks in order of their arrival for a time slice of 20 ms. The advantage is that scheduling decisions are made quickly.
But there is a major drawback: The scheduler isn’t fair. Consider two tasks: a task A that just runs for a burst of 1 ms and then sleeps and a task B that runs continuously. Even though A uses only 5% of its allotted time slice every time it is scheduled, it will, on average, be scheduled the same number of times as B, thus B runs 20 times longer on the CPU. We see later why this is a problem.
But first, let’s look at the implementation, omitting the user-land and logging code:
@BPF(license = "GPL")
public abstract class FIFOScheduler extends BPFProgram
implements Scheduler {
/**
* A custom scheduling queue
*/
static final long SHARED_DSQ_ID = 0;
@Override
public int init() {
// init the scheduling queue
return scx_bpf_create_dsq(SHARED_DSQ_ID, -1);
}
@Override
public int selectCPU(Ptr<task_struct> p, int prev_cpu,
long wake_flags) {
boolean is_idle = false;
// let sched-ext select the best CPU
int cpu = scx_bpf_select_cpu_dfl(p, prev_cpu,
wake_flags,
Ptr.of(is_idle));
if (is_idle) {
// directly dispatch to the CPU if it is idle
scx_bpf_dispatch(p, SCX_DSQ_LOCAL.value(),
SCX_SLICE_DFL.value(),0);
}
return cpu;
}
@Override
public void enqueue(Ptr<task_struct> p, long enq_flags) {
// directly dispatch to the selected CPU's local queue
scx_bpf_dispatch(p, SHARED_DSQ_ID,
SCX_SLICE_DFL.value(), enq_flags);
}
// ...
public static void main(String[] args) {
try (var program =
BPFProgram.load(FIFOScheduler.class)) {
// ...
}
}
}
But what about a slightly more complex scheduler? Can we write a scheduler that is fairer to tasks that don’t run for their whole time slice?
Weighted Scheduler
A simple solution to our fairness is prioritizing tasks according to their actual runtime on the CPU. While we’re at it, we can also factor in the priority (or weight) of a process by scaling the runtime accordingly. This policy is far better fairness-wise than the FIFO policy, but of course, there is still space improvement. There are reasons why proper schedulers are complex. To learn more, I recommend listening to the Tech Over Tea podcast episode with sched-ext developer David Vernet, which you can find on YouTube or Spotify.
Before I show you the scheduler implementation, I want to bring into focus the properties of the sched_ext_entity typed scx field of type of the task_struct, which are valuable for implementing the described policy (adapted from the C source):
@Type
class sched_ext_entity {
// ...
// priority of the task
@Unsigned int weight;
// ...
/*
* Runtime budget in nsecs. This is usually set through
* scx_bpf_dispatch() but can also be modified directly
* by the BPF scheduler. Automatically decreased by SCX
* as the task executes. On depletion, a scheduling event
* is triggered.
*
* This value is cleared to zero if the task is preempted
* by %SCX_KICK_PREEMPT and shouldn't be used to determine
* how long the task ran. Use p->se.sum_exec_runtime
* instead.
*/
@Unsigned long slice;
/*
* Used to order tasks when dispatching to the
* vtime-ordered priority queue of a dsq. This is usually
* set through scx_bpf_dispatch_vtime() but can also be
* modified directly by the BPF scheduler. Modifying it
* while a task is queued on a dsq may mangle the ordering
* and is not recommended.
*/
@Unsigned long dsq_vtime;
// ...
}
Back to the scheduler implementation, the new scheduler is not too dissimilar to the FIFO scheduler but makes full use of the enqueue and dispatch methods:
@BPF(license = "GPL")
public abstract class WeightedScheduler extends BPFProgram
implements Scheduler {
// current vtime
final GlobalVariable<@Unsigned Long> vtime_now =
new GlobalVariable<>(0L);
/*
* Built-in DSQs such as SCX_DSQ_GLOBAL cannot be used as
* priority queues (meaning, cannot be dispatched to with
* scx_bpf_dispatch_vtime()). We therefore create a
* separate DSQ with ID 0 that we dispatch to and consume
* from. If scx_simple only supported global FIFO scheduling,
* then we could just use SCX_DSQ_GLOBAL.
*/
static final long SHARED_DSQ_ID = 0;
@BPFFunction
@AlwaysInline
boolean isSmaller(@Unsigned long a, @Unsigned long b) {
return (long)(a - b) < 0;
}
@Override
public int init() {
// init the scheduling queue
return scx_bpf_create_dsq(SHARED_DSQ_ID, -1);
}
@Override
public int selectCPU(Ptr<task_struct> p, int prev_cpu,
long wake_flags) {
// same as before
boolean is_idle = false;
int cpu = scx_bpf_select_cpu_dfl(p, prev_cpu,
wake_flags, Ptr.of(is_idle));
if (is_idle) {
scx_bpf_dispatch(p, SCX_DSQ_LOCAL.value(),
SCX_SLICE_DFL.value(),0);
}
return cpu;
}
@Override
public void enqueue(Ptr<task_struct> p, long enq_flags) {
// get the weighted vtime, specified in the stopping
// method
@Unsigned long vtime = p.val().scx.dsq_vtime;
/*
* Limit the amount of budget that an idling task can
* accumulate to one slice.
*/
if (isSmaller(vtime,
vtime_now.get() - SCX_SLICE_DFL.value())) {
vtime = vtime_now.get() - SCX_SLICE_DFL.value();
}
/*
* Dispatch the task to dsq_vtime-ordered priority
* queue, which prioritizes tasks with smaller vtime
*/
scx_bpf_dispatch_vtime(p, SHARED_DSQ_ID,
SCX_SLICE_DFL.value(), vtime,
enq_flags);
}
@Override
public void dispatch(int cpu, Ptr<task_struct> prev) {
scx_bpf_consume(SHARED_DSQ_ID);
}
@Override
public void running(Ptr<task_struct> p) {
/*
* Global vtime always progresses forward as tasks
* start executing. The test and update can be
* performed concurrently from multiple CPUs and
* thus racy. Any error should be contained and
* temporary. Let's just live with it.
*/
@Unsigned long vtime = p.val().scx.dsq_vtime;
if (isSmaller(vtime_now.get(), vtime)) {
vtime_now.set(vtime);
}
}
@Override
public void stopping(Ptr<task_struct> p, boolean runnable) {
/*
* Scale the execution time by the inverse of the weight
* and charge.
*
* Note that the default yield implementation yields by
* setting @p->scx.slice to zero and the following would
* treat the yielding task
* as if it has consumed all its slice. If this penalizes
* yielding tasks too much, determine the execution time
* by taking explicit timestamps instead of depending on
* @p->scx.slice.
*/
p.val().scx.dsq_vtime +=
(SCX_SLICE_DFL.value() - p.val().scx.slice) * 100
/ p.val().scx.weight;
}
@Override
public void enable(Ptr<task_struct> p) {
/*
* Set the virtual time to the current vtime, when the task
* is about to be scheduled for the first time
*/
p.val().scx.dsq_vtime = vtime_now.get();
}
public static void main(String[] args) {
try (var program =
BPFProgram.load(WeightedScheduler.class)) {
// ...
}
}
}
I merged the FIFO and the weighted scheduler implementations into the SampleScheduler class, which you can find on GitHub.
Running the Schedulers
After we’ve built the code via mvn package, you can run the weighted scheduler via
./run.sh SampleScheduler
and the FIFO scheduler via
./run.sh SampleScheduler --fifo
Both schedulers output information on the dispatches per CPU and enqueues per process every 5 seconds.
Comparing the Schedulers
These two schedulers are nice tiny toys, but can we actually use them? I did. I recorded my eBPF summit talk on a laptop running the FIFO scheduler without issues. But let’s run a benchmark:
In the OpenJDK world, there is a commonly used benchmark suite called Renaissance, which runs on as many cores as the system has and allows us to estimate the performance of our scheduler. I ran the benchmark suite three times for every scheduler, the default Linux scheduler, the FIFO, and the weighted scheduler, using a T14 AMD Thinkpad with 32 GB of RAM and 16 hyper-threaded CPU cores (8 physical). The results are interesting:
The FIFO scheduler runs the fastest, with an average runtime of 38:01 minutes, closely followed by the default scheduler, with a runtime of 38:15 minutes. The weighted scheduler faired far worse, with a runtime of 39:44 minutes. The plot shows that the FIFO scheduler is tainted by a single outlier, which was actually the first measurement. I redone this measurement, replacing it with a new one:
This outlier replacement reduces the average runtime of the FIFO scheduler to just 36:30 minutes, which is significantly faster than that of the other schedulers. Of course, this is not conclusive, as
I only run the benchmarks three times
We only measured the raw speed of the program
The benchmarking suite spun up at most as many Java threads as there are CPU cores
However, this shows that a tiny custom scheduler might improve performance in some use cases.
Should we abandon all other schedulers? No, because the responsiveness of a system that uses the FIFO scheduler is terrible. The scheduler inherently, as discussed before, prioritizes tasks that spend all of their allotted time on the CPU. So tasks that do some IO and then wait are penalized. The problem here: programs like web servers or user interfaces fall into this category.
To demonstrate this, I ran a CPU-bound program that spun up five times the amount of threads as there are cores. Alongside, I ran the GNOME stop-watch application:
The system remains responsive with both the default and weighted scheduler but is almost unusable with the FIFO scheduler.
Every scheduler makes trade-offs; being able to create your own scheduler allows you to set your own priorities.
Conclusion
In this blog post, I showed you how to implement two different Linux schedulers using the bleeding edge eBPF scheduler extensions for Linux and a patched version of my hello-ebpf library. This all opens up many possibilities regarding the testing of concurrent applications and furthermore shows the versatility of eBPF. If you want to learn more about how to implement more advanced schedulers, I can really recommend joining the sched-ext slack and looking into the larger schedulers in the scx repository on GitHub.
Thank you for joining me on this journey to bring eBPF to the Java world. I look forward to seeing you in a couple of weeks for another blog post or at a conference.
This article is part of my work in the SapMachine team at SAP, making profiling and debugging easier for everyone. Thank you to the people of the sched-ext slack, like Tejun Heo, Andrea Righi, and Giovanni Gherdovich, for answering all my questions.
Johannes Bechberger is a JVM developer working on profilers and their underlying technology in the SapMachine team at SAP. This includes improvements to async-profiler and its ecosystem, a website to view the different JFR event types, and improvements to the FirefoxProfiler, making it usable in the Java world. His work today comprises many open-source contributions and his blog, where he regularly writes on in-depth profiling and debugging topics. He also works on hello-ebpf, the first eBPF library for Java. His most recent contribution is the new CPU Time Profiler in JDK 25.
New posts like these come out at least every two weeks, to get notified about new posts, follow me on BlueSky, Twitter, Mastodon, or LinkedIn, or join the newsletter:








")
")

")
")
")