
Welcome back to my hello-ebpf series. A few weeks ago, I showed you how to write a minimal Linux scheduler in both Java and C using the new Linux scheduler extensions. Before we start: The Linux kernel with sched-ext support has finally been released, so the next Ubuntu version will probably have support for writing custom Linux schedulers out-of-the-box.
In this week’s blog posts, I’ll show you how to use a custom scheduler to control the execution of tasks and processes. The main idea is that I want to be able to tell a task (a single thread of a process) or a task group (usually a process) to stop for a few seconds. This can be helpful for testing the behaviour of programs in scheduling edge cases, when for example a consumer thread isn’t scheduled as it used to be normally.
Of course, we can achieve this without a custom Linux scheduler: We can just send the task a POSIX SIGSTOP signal and a SIGCONT signal when we want to continue it. But where is the fun in that? Also, some applications (I look at you, OpenJDK) don’t like it when you send signals to them, and they will behave strangely, as they can observe the signals.
Idea
I showed before that we can write schedulers ourselves, so why not use them for this case? The main idea is to only schedule processes in the scheduler that are allowed to be scheduled, according to a task (and task group) settings BPF map:
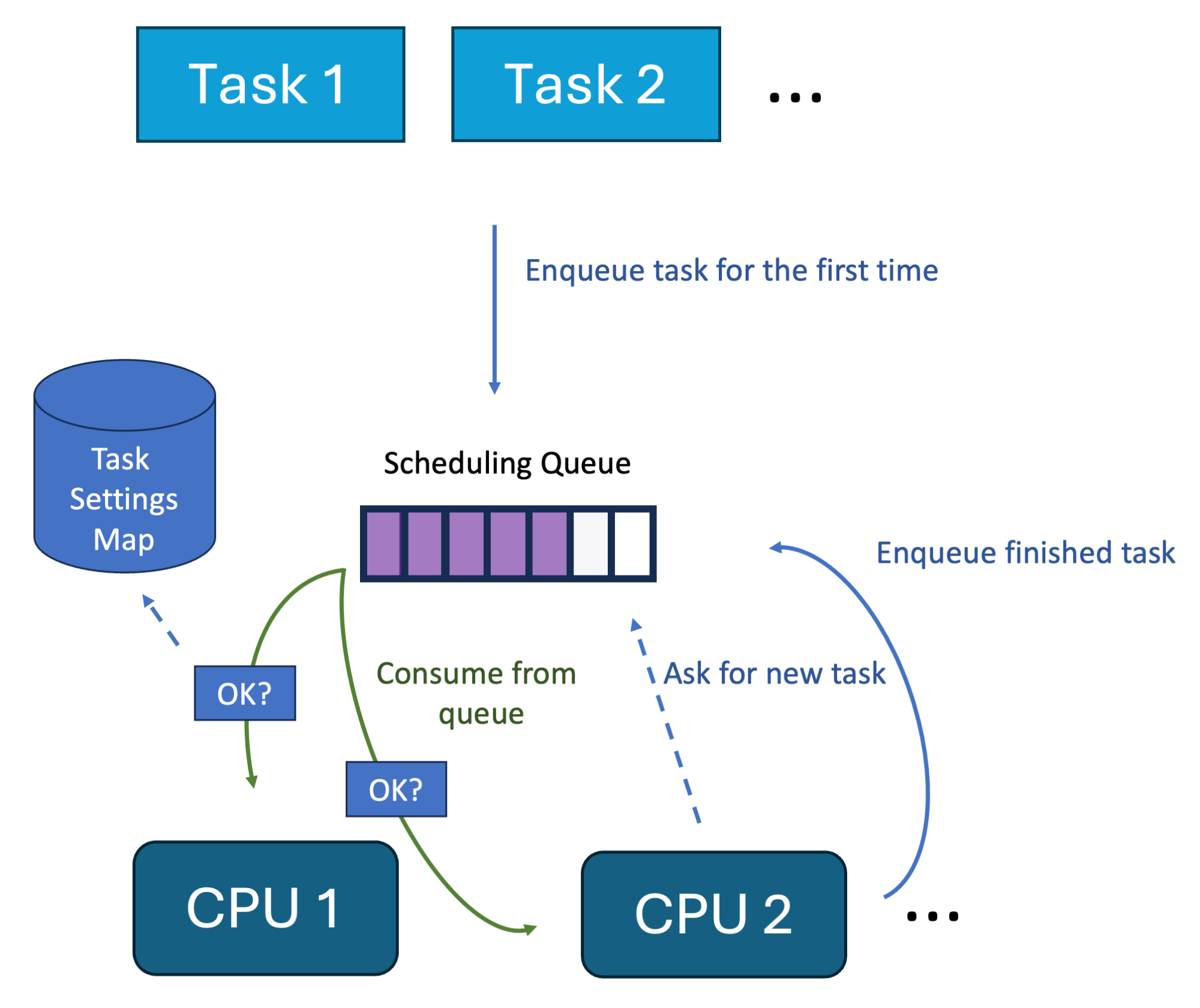
This is essentially our minimal scheduler, with one slight modification that I show you later.
And yes, the tasks are not stopped immediately, but with a maximum of 5ms scheduling intervals, we only have a small delay.
I implemented all this in the taskcontrol project, which you can find on GitHub. This is where you also find information on the required dependencies and how to install a 6.12 Kernel if you’re on Ubuntu 24.10.
Usage
But first, what can you do with this? As the scheduler is written in Java with hello-ebpf, we can simply add a REST web frontend written with Javalin that exposes the functionality to the rest of the system without root privileges. On top of this, we can use the techniques from my blog post Mapping Java Thread Ids to OS Thread Ids to create a library that connects with the scheduler server and uses it to stop specific Java threads:
// Start a sample thread Thread clockThread = new ClockThread(); clockThread.start(); ThreadControl threadControl = new ThreadControl(); // stop the thread from being scheduled threadControl.stopThread(clockThread); Thread.sleep(10000); // resume the thread again threadControl.resumeThread(clockThread);
Before we can use the library, we have to launch the scheduling server, which can be done using the schedule.sh script in the taskcontrol project.
The underlying REST API is:
GET localhost:8087/help prints you this help
GET localhost:8087/task/{id} to get the status of a task
GET localhost:8087/task/{id}?stopping=true|false to stop or resume a task
GET localhost:8087/task/plan/{id}?plan=s10,r10 to set the plan for a task (e.g. 10s running, 10s stopped)
GET localhost:8087/task/plan/{id} to get the current plan for a task
GET localhost:8087/plans the current plans as JSON
The same for taskGroup (process)
This even allows you to set scheduling plans. Just be aware that every task must be scheduled at least every 30 minutes, or the custom scheduler will be removed. Why? As someone from the sched-ext team told me, 30 seconds is like infinity in the scheduling world, so if the scheduler doesn’t schedule the task for 30 seconds, the scheduler is probably broken. Although this might feel limiting, it is actually great when you develop a custom scheduler and make a mistake. Your system is usually only unresponsive for a maximum of 30 seconds.
So, assume you run the Ticker Java application, which increments a counter every second and prints it, from the samples folder of the taskcontrol project; you can start playing with the REST API.
Start the scheduler at the default port 8087:
./scheduler.sh
In another terminal, start the Ticker application:
java samples/Ticker.java &
Now take the PID of the Ticker program and stop it via the API:
curl "localhost:8087/taskGroup/$(pgrep -f Ticker)?stopping=true"
It should now stop being rescheduled and, therefore, stop emitting Tick n.
You can resume it via:
curl "localhost:8087/taskGroup/$(pgrep -f Ticker)?stopping=false"
You can also set a sequence of stopping and running times via:
curl "localhost:8087/taskGroup/plan/$(pgrep -f Ticker)?plan=10s,5r,10s,5s"
This will stop the tasks of the task group for 10 seconds, run it for 5 seconds, stop it for 10 seconds, and stop it for 5 seconds. After ending the scheduling plan, the task will run normally.
Now, on to the implementation. I’ll skip the non-scheduler parts, as developing a small REST API is luckily quite easy with Javalin (and without all the magic that is involved in Spring Boot). The REST client simply uses the built-in HttpClient.
Implementation
First, we define a generic interface for schedulers which extends the Scheduler interface from hello-ebpf:
@BPFInterface
public interface BaseScheduler extends Scheduler, AutoCloseable {
@Type
record TaskSetting(boolean stop) {
}
default void tracePrintLoop() {
if (this instanceof BPFProgram program) {
program.tracePrintLoop();
}
}
BPFHashMap<Integer, TaskSetting> getTaskSettingsMap();
BPFHashMap<Integer, TaskSetting> getTaskGroupSettingsMap();
}
This interface allows access to the task (thread) and task group (process) BPF maps, which the eBPF code uses to check the settings of tasks and task groups. Currently, the task settings only consist of the simple boolean stop, which signals, when set to true, that a task or task group should not be scheduled.
Currently, we only have one implementation: The minimal FIFO scheduler. This scheduler, as presented in my previous blog posts A Minimal Scheduler with eBPF, sched_ext and C and Hello eBPF: Writing a Linux scheduler in Java with eBPF (15), has a main scheduling from which all CPUs obtain the next task to schedule.
The basic structure of the class is simple; it just implements the BasicScheduler interface, sets its scheduler name, and creates the two eBPF maps as mentioned before:
@BPF(license = "GPL")
@Property(name = "sched_name", value = "minimal_stopping_scheduler")
public abstract class FIFOScheduler extends BPFProgram
implements BaseScheduler {
private static final int SHARED_DSQ_ID = 0;
@BPFMapDefinition(maxEntries = 10000)
BPFHashMap<Integer, TaskSetting> taskSettings;
@BPFMapDefinition(maxEntries = 10000)
BPFHashMap<Integer, TaskSetting> taskGroupSettings;
// ...
@Override
public BPFHashMap<Integer, TaskSetting> getTaskGroupSettingsMap() {
return taskGroupSettings;
}
@Override
public BPFHashMap<Integer, TaskSetting> getTaskSettingsMap() {
return taskSettings;
}
}
The init and the enqueue methods are as before:
@Override
public int init() {
return scx_bpf_create_dsq(SHARED_DSQ_ID, -1);
}
@Override
public void enqueue(Ptr<TaskDefinitions.task_struct> p,
long enq_flags) {
var sliceLength = ((@Unsigned int) 5_000_000) /
scx_bpf_dsq_nr_queued(SHARED_DSQ_ID);
scx_bpf_dispatch(p, SHARED_DSQ_ID, sliceLength, enq_flags);
}
The only difference comes with the dispatch method. We can describe it in pseudo-code first:
def dispatch(cpu: int, task: prev):
for task in shared_queue:
if shouldStop(task):
// ignore tasks that should be stopped
continue
if not can_run_on_cpu(cpu, task):
// ignore tasks that can't be run on the CPU
continue
if dispatch_to_cpu(cpu, task):
// dispatch has been successful
return
The shouldStop method just checks the two settings maps:
@BPFFunction
@AlwaysInline
public boolean shouldStop(Ptr<TaskDefinitions.task_struct> p) {
var taskSetting = taskSettings.bpf_get(p.val().pid);
var groupSetting = taskGroupSettings.bpf_get(p.val().tgid);
return (taskSetting != null && taskSetting.val().stop())
|| (groupSetting != null && groupSetting.val().stop());
}
The main difficulty is looping over the scheduling queue entries on every dispatch. This is essentially iterator-based, but we can use the C macro bpf_for_each to make it more readable. Sadly I haven’t yet found a way to expose this macro to Java properly. But luckily, hello-ebpf supports inline C code. I extracted the inner loop into the tryDispatching method to make it more readable. The dispatch method is then implemented as follows:
@Override
public void dispatch(int cpu, Ptr<TaskDefinitions.task_struct> prev) {
// macros like bpf_for_each are not yet supported in hello-ebpf Java
String CODE = """
s32 this_cpu = bpf_get_smp_processor_id();
struct task_struct *p;
bpf_for_each(scx_dsq, p, SHARED_DSQ_ID, 0) {
if (tryDispatching(BPF_FOR_EACH_ITER, p, this_cpu)) {
break;
}
}
""";
}
This macro actually had problems in the Linux Kernel 6.11 because the eBPF verifier didn’t support it properly. This is one of the reasons why it took so long to write this blog post.
The implementation of the tryDispatching method is then straight-forward and in pure Java:
@BPFFunction
@AlwaysInline
public boolean tryDispatching(Ptr<BpfDefinitions.bpf_iter_scx_dsq> iter,
Ptr<TaskDefinitions.task_struct> p, int cpu) {
if (shouldStop(p)) {
return false;
}
// check if the CPU is usable by the task
if (!bpf_cpumask_test_cpu(cpu, p.val().cpus_ptr)) {
return false;
}
return scx_bpf_dispatch_from_dsq(iter, p,
SCX_DSQ_LOCAL_ON.value() | cpu,
SCX_ENQ_PREEMPT.value());
}
And this is all.
Conclusion
In this blog post, I showed you how to write a simple FIFO scheduler to schedule tasks selectively with sched-ext and hello-ebpf. Of course, we can and will extend this scheduler to support more features, like pinning tasks to specific CPUs and using a weighted scheduling queue. But this is all for this week.
Thank you for joining me on this journey to bring eBPF and sched-ext to the Java world. It has been a while since my last blog post, but I hope to resume regular blogging again this month.
P.S.: If you live near Malmö, I give a talk on writing Linux schedulers in Java at the Javaforum Malmö on the 20th of January.
To close, here is a picture of one of my travels, visiting the Gutenberg Museum in Mainz:

This article is part of my work in the SapMachine team at SAP, making profiling and debugging easier for everyone. Thank you to the people of the sched-ext slack, like Tejun Heo and Andrea Righi, for answering all my questions.

")
")


")