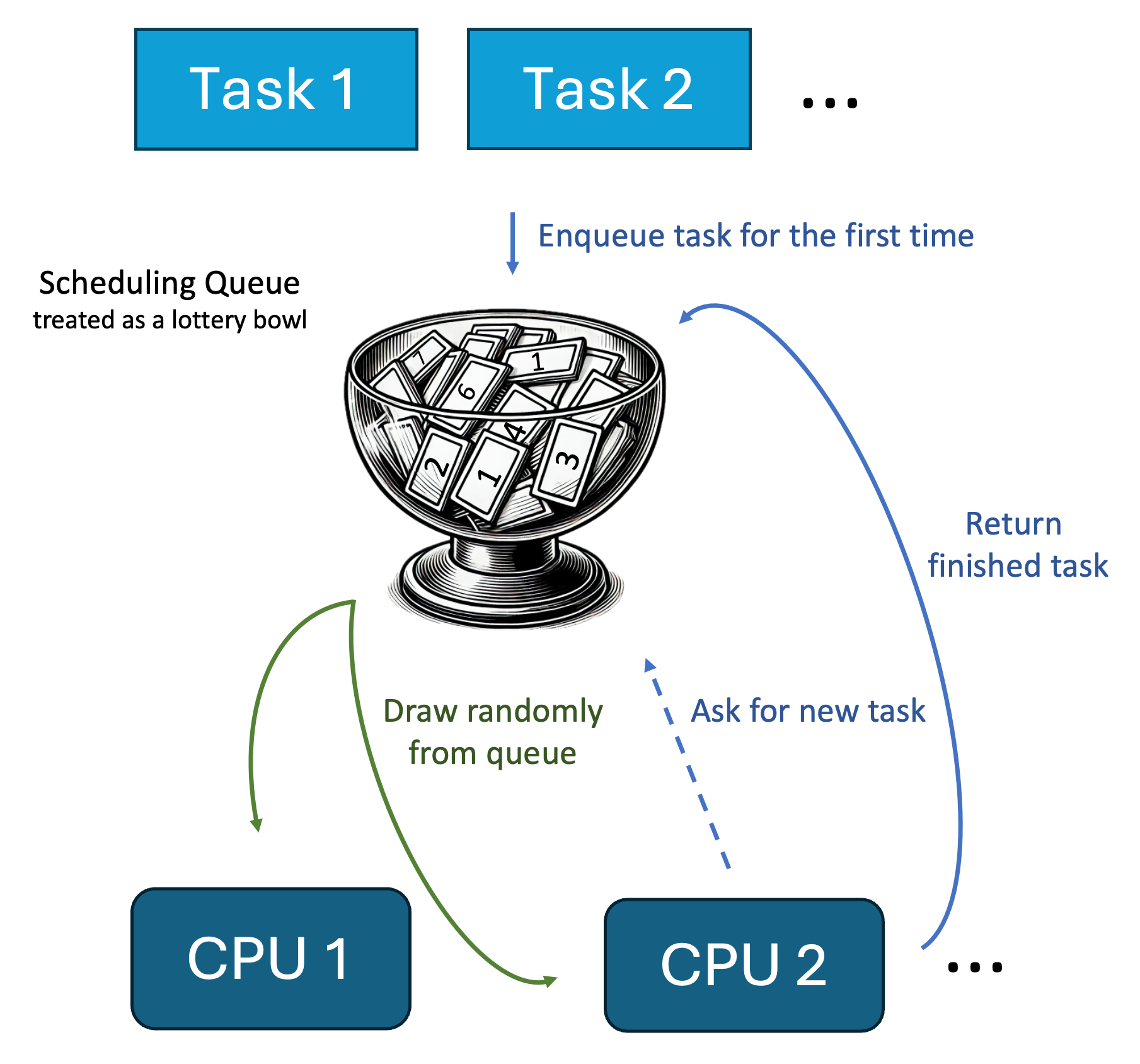
Welcome back to my hello-ebpf series. Last week, we learned about lottery schedulers and how to implement one with sched-ext and hello-ebpf. But there was one major issue when writing the scheduler in Java: hello-ebpf lacked support for the bpf_for_each macro. This is what this weeks short blog post is all about.
To loop over all elements in the scheduling queue, to pick a random one, we had to write inline C code. A simplified version without scheduling priorities looks like the following:
@Override
public void dispatch(int cpu, Ptr<TaskDefinitions.task_struct> prev) {
String CODE = """
// pick a random task struct index
s32 random = bpf_get_prandom_u32() %
scx_bpf_dsq_nr_queued(SHARED_DSQ_ID);
struct task_struct *p = NULL;
bpf_for_each(scx_dsq, p, SHARED_DSQ_ID, 0) {
// iterate till we get to this number
random = random - 1;
// and try to dispatch it
if (random <= 0 &&
tryDispatching(BPF_FOR_EACH_ITER, p, cpu)) {
return 0;
}
};
return 0;
""";
}
This surely works, but inline C code is not the most readable and writing it is error-prone. I’ve written on this topic in my post Hello eBPF: Write your eBPF application in Pure Java (12) before. So what was keeping us from supporting the bpf_for_each macro? Support for lambdas as arguments to built-in bpf functions.
Lottery Scheduler in Pure Java
May I introduce you know the support for directly passed lambda expressions: This let’s us define a bpf_for_each_dsq function and to write a simple lottery scheduler in pure Java: