AsyncGetCallTrace is an API to obtain the top n Java frames of a thread asynchronously in a signal handler. This API is widely used but has its problems; see JEP 435 and my various blog posts (AsyncGetStackTrace: A better Stack Trace API for the JVM, jmethodIDs in Profiling: A Tale of Nightmares, …). My original approach with my JEP proposal was to build a replacement of the API, which could be used as a drop-in for AsyncGetCallTrace: Still a single method that populates a preallocated frame list:
No doubt this solves a few of the problems, the new API would be officially supported, return more information, and could return the program counter for C/C++ frames. But it eventually felt more like a band-aid, hindered by trying to mimic AsyncGetCallTrace. In recent months, I had a few discussions with Erik Österlund and Jaroslav Bachorik in which we concluded that what we really need is a completely redesigned profiling API that isn’t just an AsyncGetCallTrace v2.
The new API should be more flexible, safer, and future-proof than the current version. It should, if possible, allow incremental stack scanning and support virtual threads. So I got to work redesigning and, more crucially, rethinking the profiling API inspired by Erik Österlunds ideas.
This blog post is the first of two blog posts covering the draft of a new iterator-based stack walking API, which builds the base for the follow-up blog post on safepoint-based profiling. The following blog post will come out on Wednesday as a special for the OpenJDK Committers’ Workshop.
Iterators
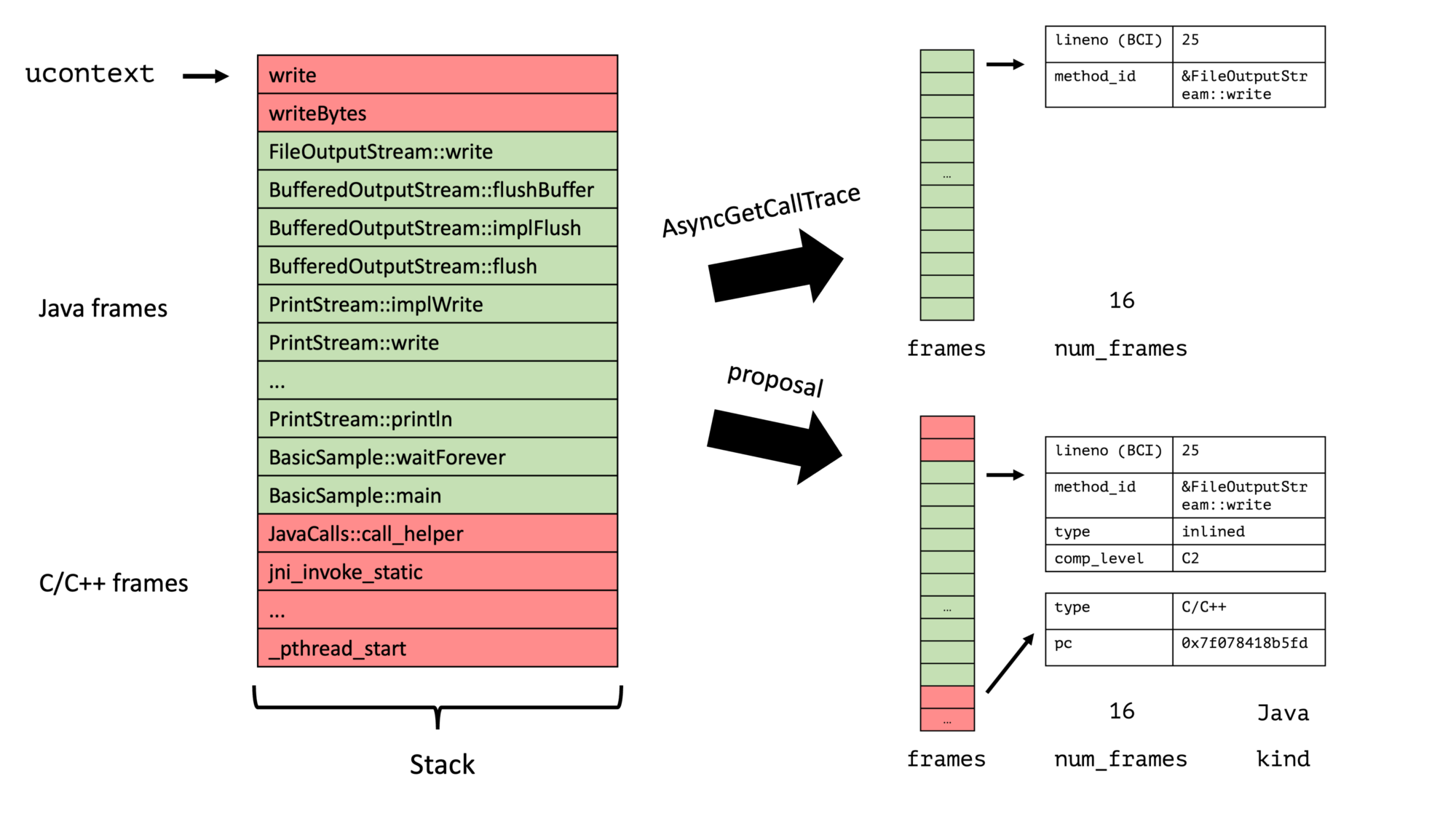
AsyncGetCallTrace fills a preallocated list of frames, which has the most profound expected stack trace length, and many profilers just store away this list. This limits the amount the data we can give for each frame. We don’t have this problem with an iterator-based API, where we first create an iterator for the current stack and then walk from frame to frame:
The API can offer all the valuable information the JVM has, and the profiler developer can pick the relevant information. This API is, therefore, much more flexible; it allows the profiler writer to …
- … walk at frames without a limit
- … obtain program counter, stack pointer, and frame pointer to use their stack walking code for C/C++ frames between Java frames
- … use their compression scheme for the data
- don’t worry about allocating too much data on the stack because the API doesn’t force you to preallocate a large number of frames
This API can be used to develop your version of AsyncGetCallTrace, allowing seamless integration into existing applications.
Using the API in a signal handler and writing it using C declarations imposes some constraints, which result in a slightly more complex API which I cover in the following section.
Proposed API
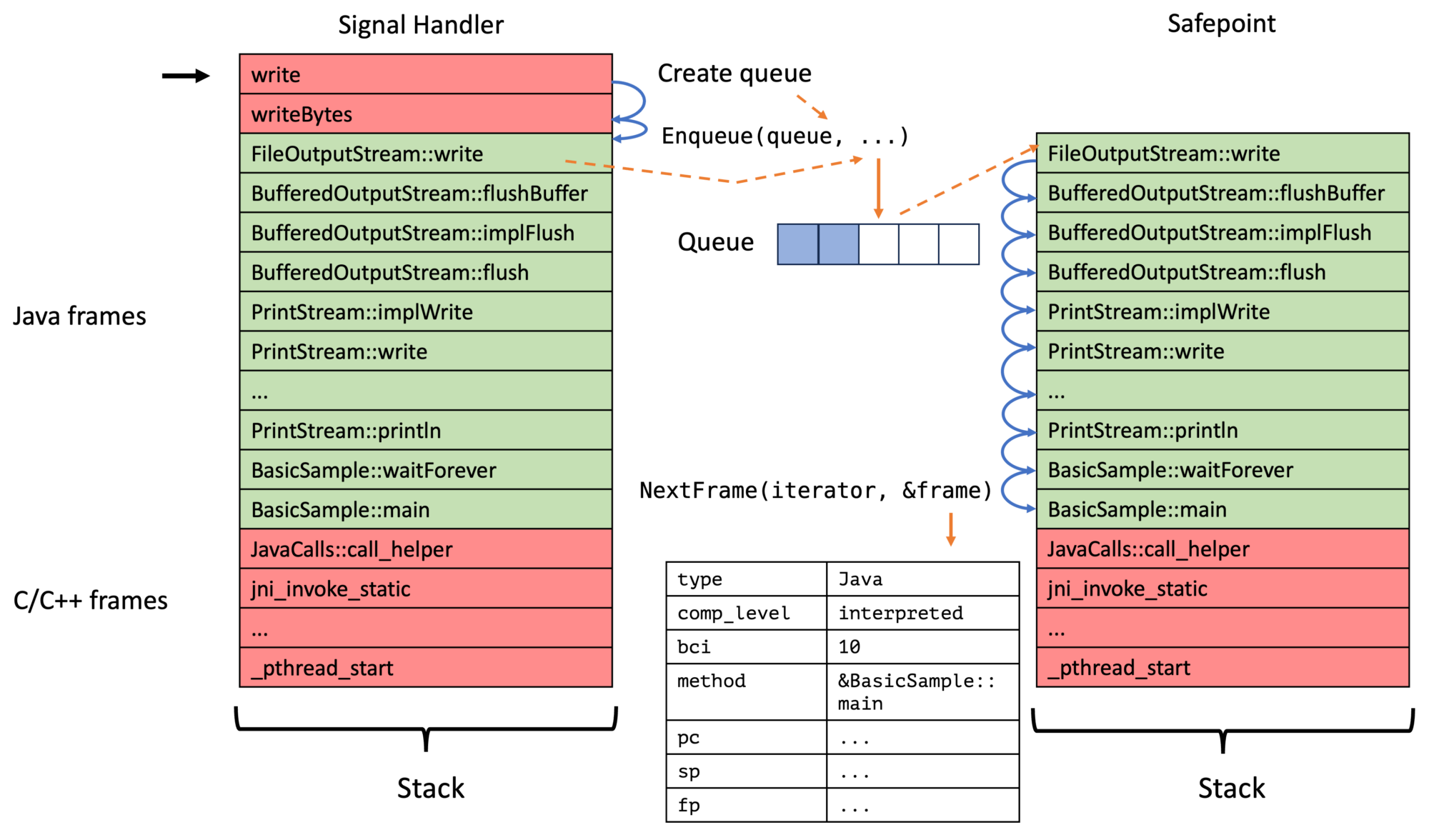
When running in a signal handler, a significant constraint is that we have to allocate everything on the stack. This includes the iterator. The problem is that we don’t want to specify the size of the iterator in the API because this iterator is based on an internal stack walker and is subject to change. Therefore, we have to allocate the iterator on the stack inside an API method, but this iterator is only valid in the method’s scope. This is the reason for the ASGST_RunWithIterator which creates an iterator and passes it to a handler:
// Create an iterator and pass it to fun alongside
// the passed argument.
// @param options ASGST_INCLUDE_NON_JAVA_FRAMES, ...
// @return error or kind
int ASGST_RunWithIterator(void* ucontext,
int32_t options,
ASGST_IteratorHandler fun,
void* argument);
The iterator handler is a pointer to a method in which the ASGST_RunWithIterator calls with an iterator and the argument. Yes, this could be nicer in C++, which lambdas and more, but we are constrained to a C API. It’s easy to develop a helper library in C++ that offers zero-cost abstractions, but this is out-of-scope for the initial proposal.
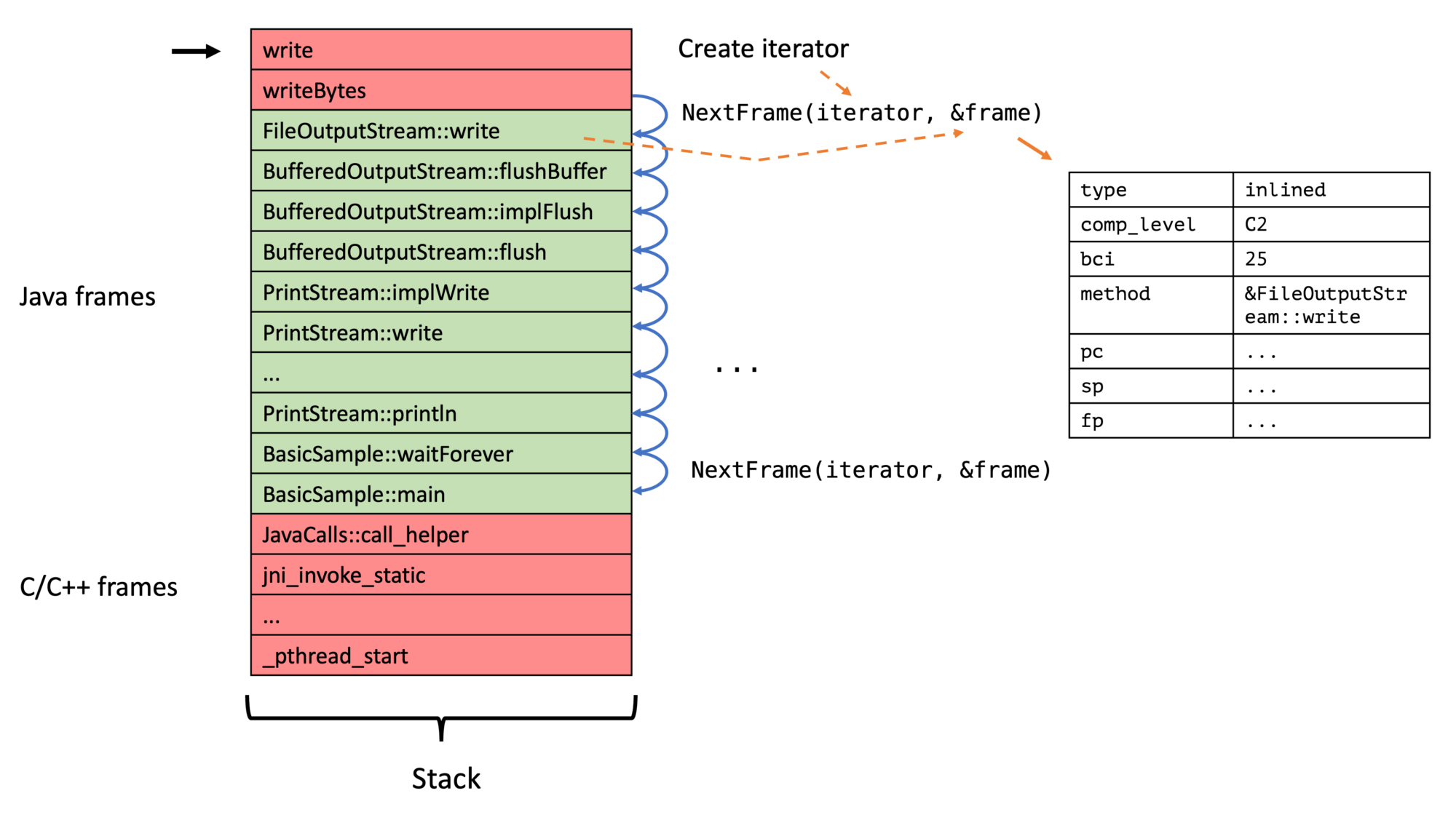
Now to the iterator itself. The main method is ASGST_NextFrame:
// Obtains the next frame from the iterator
// @returns 1 if successful, else error code (< 0) / end (0)
// @see ASGST_State
//
// Typically used in a loop like:
//
// ASGST_Frame frame;
// while (ASGST_NextFrame(iterator, &frame) == 1) {
// // do something with the frame
// }
int ASGST_NextFrame(ASGST_Iterator* iterator, ASGST_Frame* frame);
The frame data structure, as explained in the previous section, contains all required information and is far simpler than the previous proposal (without any union):
enum ASGST_FrameTypeId {
ASGST_FRAME_JAVA = 1, // JIT compiled and interpreted
ASGST_FRAME_JAVA_INLINED = 2, // inlined JIT compiled
ASGST_FRAME_JAVA_NATIVE = 3, // native wrapper to call
// C/C++ methods from Java
ASGST_FRAME_NON_JAVA = 4 // C/C++/... frames
};
typedef struct {
uint8_t type; // frame type
int comp_level; // compilation level, 0 is interpreted,
// -1 is undefined, > 1 is JIT compiled
int bci; // -1 if the bci is not available
// (like in native frames)
ASGST_Method method; // method or nullptr if not available
void *pc; // current program counter
// inside this frame
void *sp; // current stack pointer
// inside this frame, might be null
void *fp; // current frame pointer
// inside this frame, might be null
} ASGST_Frame;
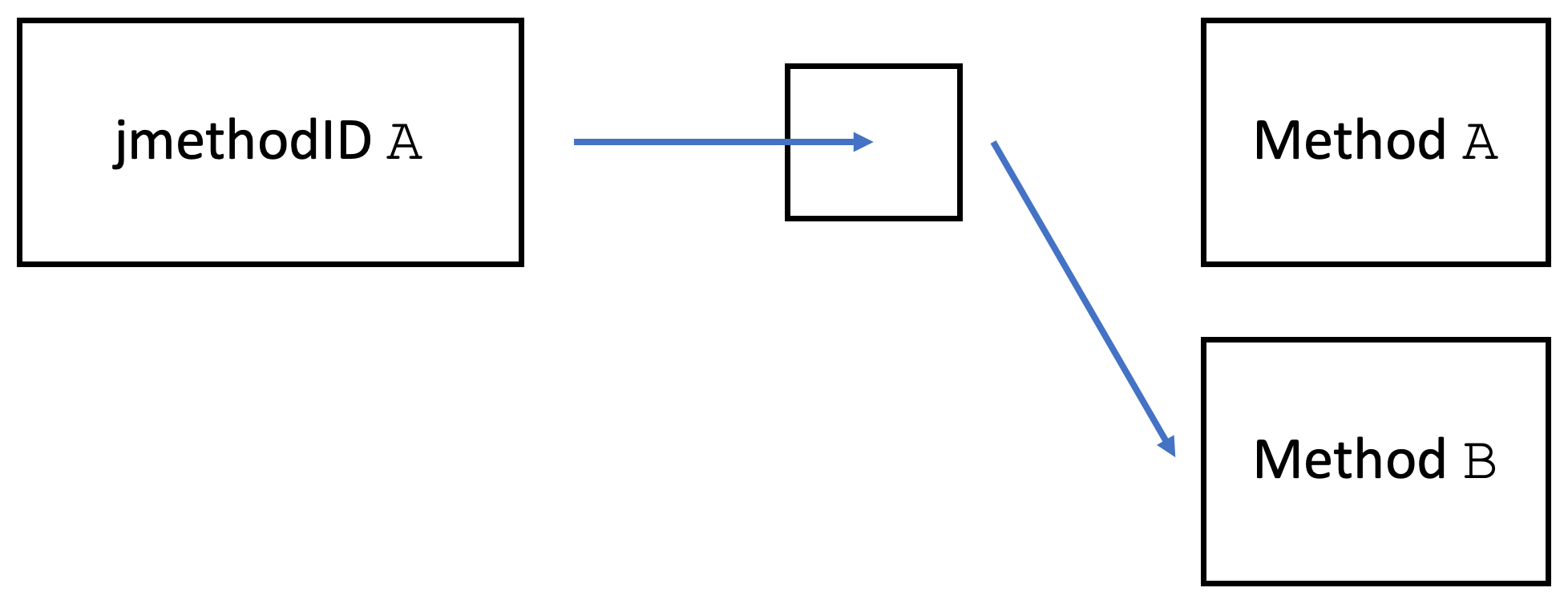
This uses ASGST_Method instead of jmethodID, see jmethodIDs in Profiling: A Tale of Nightmares for more information.
The error codes used both by ASGST_RunWithIterator and ASGST_NextFrame are defined as:
enum ASGST_Error {
ASGST_NO_FRAME = 0, // come to and end
ASGST_NO_THREAD = -1, // thread is not here
ASGST_THREAD_EXIT = -2, // dying thread
ASGST_UNSAFE_STATE = -3, // thread is in unsafe state
ASGST_NO_TOP_JAVA_FRAME = -4, // no top java frame
ASGST_ENQUEUE_NO_QUEUE = -5, // no queue registered
ASGST_ENQUEUE_FULL_QUEUE = -6, // safepoint queue is full
ASGST_ENQUEUE_OTHER_ERROR = -7, // other error,
// like currently at safepoint
// everything lower than -16 is implementation specific
};
ASGST_ENQUEUE_NO_QUEUE and ASGST_ENQUEUE_FULL_QUEUE are not relevant yet, but their importance will be evident in my next blog post.
This API wouldn’t be complete without a few helper methods. We might want to start from an arbitrary frame; for example, we use a custom stack walker for the top C/C++ frames:
// Similar to RunWithIterator, but starting from
// a frame (sp, fp, pc) instead of a ucontext.
int ASGST_RunWithIteratorFromFrame(void* sp, void* fp, void* pc,
int options, ASGST_IteratorHandler fun, void* argument);
The ability to rewind an iterator is helpful too:
// Rewind an interator to the top most frame
void ASGST_RewindIterator(ASGST_Iterator* iterator);
And just in case you want to get the state of the current iterator or thread, there are two methods for you:
// State of the iterator, corresponding
// to the next frame return code
// @returns error code or 1 if no error
// if iterator is null or at end, return ASGST_NO_FRAME,
// returns a value < -16 if the implementation encountered
// a specific error
int ASGST_State(ASGST_Iterator* iterator);
// Returns state of the current thread, which is a subset
// of the JVMTI thread state.
// no JVMTI_THREAD_STATE_INTERRUPTED,
// limited JVMTI_THREAD_STATE_SUSPENDED.
int ASGST_ThreadState();
But how can we use this API? I developed a small profiler in my writing, a profiler from scratch series, which we can now use to demonstrate using the methods defined before. Based on my Writing a Profiler in 240 Lines of Pure Java blog post, I added a flame graph implementation. In the meantime, you can also find the base implementation on GitHub.
Implementing a Small Profiler
First of all, you have to build and use my modified OpenJDK. This JDK has been tested on x86 and aarch64. The profiler API implementation is still a prototype and contains known errors, but it works well enough to build a small profiler. Feel free to review the code; I’m open to help, suggestions, or sample programs and tests.
To use this new API, you have to include the profile2.h header file, there might be some linker issues on Mac OS, so add -L$JAVA_HOME/lib/server -ljvm to your compiler options.
One of the essential parts of this new API is that, as it doesn’t use jmethodID, we don’t have to pre-touch every method (learn more on this in jmethodIDs in Profiling: A Tale of Nightmares). Therefore we don’t need to listen to ClassLoad JVMTI events or iterate over all existing classes at the beginning. So the reasonably complex code
static void JNICALL OnVMInit(jvmtiEnv *jvmti,
JNIEnv *jni_env, jthread thread) {
jint class_count = 0;
env = jni_env;
sigemptyset(&prof_signal_mask);
sigaddset(&prof_signal_mask, SIGPROF);
OnThreadStart(jvmti, jni_env, thread);
// Get any previously loaded classes
// that won't have gone through the
// OnClassPrepare callback to prime
// the jmethods for AsyncGetCallTrace.
JvmtiDeallocator<jclass> classes;
ensureSuccess(jvmti->GetLoadedClasses(&class_count,
classes.addr()),
"Loading classes failed")
// Prime any class already loaded and
// try to get the jmethodIDs set up.
jclass *classList = classes.get();
for (int i = 0; i < class_count; ++i) {
GetJMethodIDs(classList[i]);
}
startSamplerThread();
}
is reduced to just
static void JNICALL OnVMInit(jvmtiEnv *jvmti, JNIEnv *jni_env,
jthread thread) {
sigemptyset(&prof_signal_mask);
sigaddset(&prof_signal_mask, SIGPROF);
OnThreadStart(jvmti, jni_env, thread);
startSamplerThread();
}
improving the start-up/attach performance of the profiler along the way. To get from the new ASGST_Method identifiers to the method name we need for the flame graph, we don’t use the JVMTI methods but ASGST methods:
static std::string methodToString(ASGST_Method method) {
// assuming we only care about the first 99 chars
// of method names, signatures and class names
// allocate all character array on the stack
char method_name[100];
char signature[100];
char class_name[100];
// setup the method info
ASGST_MethodInfo info;
info.method_name = (char*)method_name;
info.method_name_length = 100;
info.signature = (char*)signature;
info.signature_length = 100;
// we ignore the generic signature
info.generic_signature = nullptr;
// obtain the information
ASGST_GetMethodInfo(method, &info);
// setup the class info
ASGST_ClassInfo class_info;
class_info.class_name = (char*)class_name;
class_info.class_name_length = 100;
// we ignore the generic class name
class_info.generic_class_name = nullptr;
// obtain the information
ASGST_GetClassInfo(info.klass, &class_info);
// combine all
return std::string(class_info.class_name) + "." +
std::string(info.method_name) + std::string(info.signature);
}
This method is then used in the profiling loop after obtaining the traces for all threads. But of course, by then, the ways may be unloaded. This is rare but something to consider as it may cause segmentation faults. Due to this, and for performance reasons, we could register class unload handlers and obtain the method names for the methods of unloaded classes therein, as well as obtain the names of all still loaded used ASGST_Methods when the agent is unattached (or the JVM exits). This will be a topic for another blog post.
Another significant difference between the new API to the old API is that it misses a pre-defined trace data structure. So the profiler requires its own:
struct CallTrace {
std::array<ASGST_Frame, MAX_DEPTH> frames;
int num_frames;
std::vector<std::string> to_strings() const {
std::vector<std::string> strings;
for (int i = 0; i < num_frames; i++) {
strings.push_back(methodToString(frames[i].method));
}
return strings;
}
};
We still use the pre-defined frame data structure in this example for brevity, but the profiler could customize this too. This allows the profiler only to store the relevant information.
We fill the related global_traces
static void signalHandler(int signo, siginfo_t* siginfo,
void* ucontext) {
asgct(&global_traces[available_trace++],
MAX_DEPTH, ucontext);
stored_traces++;
}
But now we have to use the ASGST_RunWithIterator with a callback. So we define the callback first:
void storeTrace(ASGST_Iterator* iterator, void* arg) {
CallTrace *trace = (CallTrace*)arg;
ASGST_Frame frame;
int count;
for (count = 0; ASGST_NextFrame(iterator, &frame) == 1 &&
count < MAX_DEPTH; count++) {
trace->frames[count] = frame;
}
trace->num_frames = count;
}
We use the argument pass-through from ASGST_RunWithIterator to the callback to pass the CallTrace instance where we want to store the traces. We then walk the trace using the ASGST_NextFrame method and iterate till the maximum count is reached, or the trace is finished.
ASGST_RunWithIterator itself is called in the signal handler:
static void signalHandler(int signo, siginfo_t* siginfo,
void* ucontext) {
CallTrace &trace = global_traces[available_trace++];
int ret = ASGST_RunWithIterator(ucontext, 0,
&storeTrace, &trace);
if (ret >= 2) { // non Java trace
ret = 0;
}
if (ret <= 0) { // error
trace.num_frames = ret;
}
stored_traces++;
}
You can find the complete code on GitHub; feel free to ask any yet unanswered questions. To use the profiler, just run it from the command line:
java -agentpath:libSmallProfiler.so=output=flames.html \
-cp samples math.MathParser
This assumes that you use the modified OpenJDK. MathParser is a demo program that generates and evaluates simple mathematical expressions. I wrote this for a compiler lab while I was still a student. The resulting flame graph should look something like this:
Conclusion
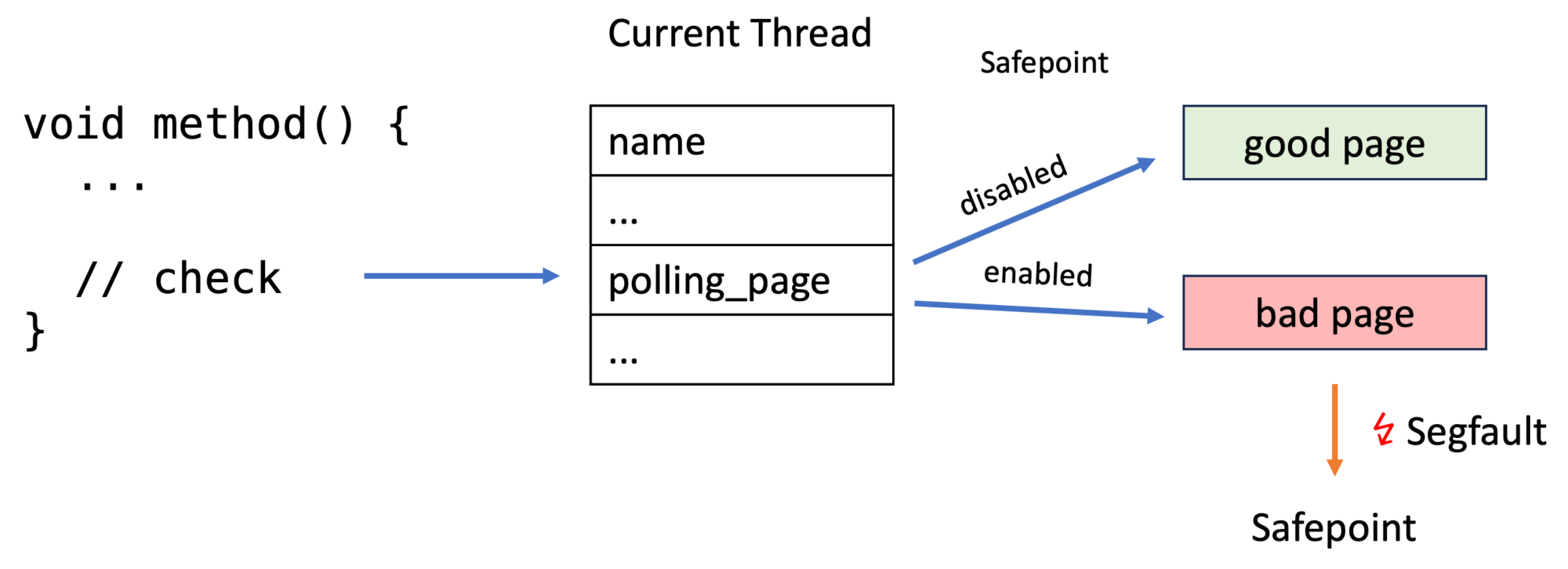
Using an iterator-based profiling API in combination with better method ids offers flexibility, performance, and safety for profiler writers. The new API is better than the old one, but it becomes even better. Get ready for the next blog post in which I tell you about safepoints and why it matters that there is a safepoint-check before unwinding any physical frame, which is the reason why I found a bug in The Inner Workings of Safepoints. So it will all come together.
Thank you for coming this far; I hope you enjoyed this blog post, and I’m open to any suggestions on my profiling API proposal.
This project is part of my work in the SapMachine team at SAP, making profiling easier for everyone.