Java Forum Nord Hannover, 12th September: Unleash the power of Open-Source Java Profilers
code.talks Hamburg, 14th September: Writing a Java Profiler in Pure Java (blog post)
I traveled from Karlsruhe to Oslo (via Stuttgart Airport) and from Oslo to Hanover via plane, then to Hamburg, Hanover, back to Hamburg, and the end via Bonn back to Karlsruhe via train:
This was my first time traveling to a conference by plane because traveling to Oslo by train takes far longer (20 hours or more).
This was my second two-week-long tour giving talks, after my tour d’Europe in May/June this year (see Report of my small Tour d’Europe), but this time it consisted solely of talks at conferences. The following is a short report of my trip that saw me brewing beer, giving a talk at one of my favorite conferences, and visiting Hamburg for the first time.
Oslo
I started by traveling to Oslo on Saturday before the conference, which began on Tuesday with workshops. My journey started with the 2:30 am bus from Karlsruhe to Stuttgart, where I took the 6:30 am flight to Paris and from there to Oslo. Flying in the early hours of the morning is something extraordinary:
I’ve never really been to Oslo before, except as a toddler, according to my parents, so I wanted to explore the city. I arrived in Oslo Saturday afternoon and stayed till Tuesday morning at the home of a friendly expat that I met via the couch-surfing platform BeBelcome.org, staying there till Tuesday morning. It was great: I had the opportunity to visit the famous Fram Polar Exploration Museum, hike around the Vettakollen, and brew beer with my host:
JavaZone
Then, on Tuesday, it was time for the workshop day of JavaZone. I’ve been drawn to this conference since I got introduced to their conference trailers in my first semester at university:
So, speaking, there was a great honor; I can recommend this experience to anyone. It is a lovely venue with good food and great organizers who care about their speakers (shout out to Felix Rabe, Rafael Winterhalter, and Marek Machnik).
I started the conference by attending the “A little taste of testing the Java compiler” workshop by Hasnae Rehioui:
Hasnae Rehioui, in her workshop
If you want to start with building the OpenJDK and running JTREG tests, her accompanying website is an excellent place to start.
At the end of the day, I went to the speaker dinner, where I met the organizers and people like Fabian Stäber and Gunnar Morling. The view from the restaurant was majestic:
Then, the next day, the conference began. The conference paid for the hotel during the week. I met Pasha Finkelshtein and Marit van Dijk from JetBrains at the breakfast buffet. I was that day in many talks, including the Maven Puzzlers talk by Andres Almiray and Ixchel Ruiz:
The day ended with eating with a few of my fellow speakers and going to the AweZone party at Himkok bar, but only after a musical performance by Mr. Orkester:
What a great way to inform all JavaZone participants of the looming AweZone event.
The next day was full of talks, including mine and eating great food. I now understand why some people call JavaZone affectionately FoodZone, with all the food served all day. My talk was in the first slot at 9:00 am; I was amazed that around 150 people turned up to attend it after the long night at the bar:
Thank you to Inna Belyantseva for the great Math-as-a-Service logo and valuable feedback on my presentation style in the weeks before the conference.
Later in the day, I went to Theresa Mammarella’s talk on CVEs:
I was introduced to her the evening before, and it was great to see the only other young JDK developer (in her case, OpenJ9) on stage.
The next day was my last in Oslo before moving to northern Germany. So I took the chance to explore the city center once more and made a photograph of the speaker’s gift:
A Viking duke in front of the Oslo Stock Exchange
I had to say goodbye to Oslo and then traveled to Hamburg via Hanover Airport to stay with a friend in Hamburg.
Hamburg
The problem was that JavaZone pays the hotel till Friday, and the speaker dinner for Java Forum Nord is Monday evening. I knew someone in Hamburg, so I stayed in Hamburg from Friday night till Monday afternoon. I used the time to look into Python debugging, which eventually resulted in my Let’s create a Python Debugger together: Part 1 blog post, went sightseeing, watched the dark comedy Sophia, der Tod und Ich, and visited the Hamburger Miniaturwunderland:
While there, I had the pleasure of traveling with light luggage, as my luggage didn’t arrive in Hamburg till Wednesday because it was somehow stuck in Amsterdam airport, where I had a stopover.
Java Forum Nord
The second conference on my journey was the Java Forum Nord in Hanover on Tuesday. This conference is a small community-run event, without many sponsors and many talks in German. It was my first German Java conference, so there were many German-only speakers that I hadn’t seen at a conference before. I met a few of them at the speaker’s dinner on Monday and at the after-party on Tuesday:
Speakers’ dinner with alcohol-free beer and Spätzle in Hanover
The day after, I traveled back to Hamburg for the code.talks conference.
Code.Talks
This was the third conference in a row and the only one without a focus on Java. The talks were on various technologies, from NFTs to creativity. The most memorable of the conference was by far the speaker’s dinner at the open kitchen restaurant Hensslers Küche and visiting the Heavens Bar & Kitchen rooftop bar in St. Pauli with Jacqueline Franßen, Hannes Drittler, and Samir Ar after the second day of the conference:
While there, I also started preparing an upcoming talk for JCon World with Marit van Dijk and had an online meeting with Jaroslav Bachorik and Erik Österlund on the future of my JEP, so stay tuned.
I traveled back to Karlsruhe via Bonn, where I met a good friend and attended a Haydn concert in the Kreuzkirche, closing the eventful two weeks cooking flammkuchen together with her and one of her new flatmates.
Conclusion
Giving three talks at conferences in a row was an experience I’m grateful for. Talking with many new and old acquaintances was, at times, taxing, yet definitely worthwhile. Especially JavaZone was a conference I never dreamt of being able to speak at.
I’m looking forward to giving many more in the future and happy that the SapMachine team at SAP allows me to do so and fully supports me in my endeavors.
If you want to attend one of my talks, just come to Devoxx Belgium, BaselOne, or J-Fall, where I’ll speak this autumn. You can find all the meet-ups and conferences that I’ve confirmed on my Talks page. I’m happy to talk at your meet-up or conference; just ask me.
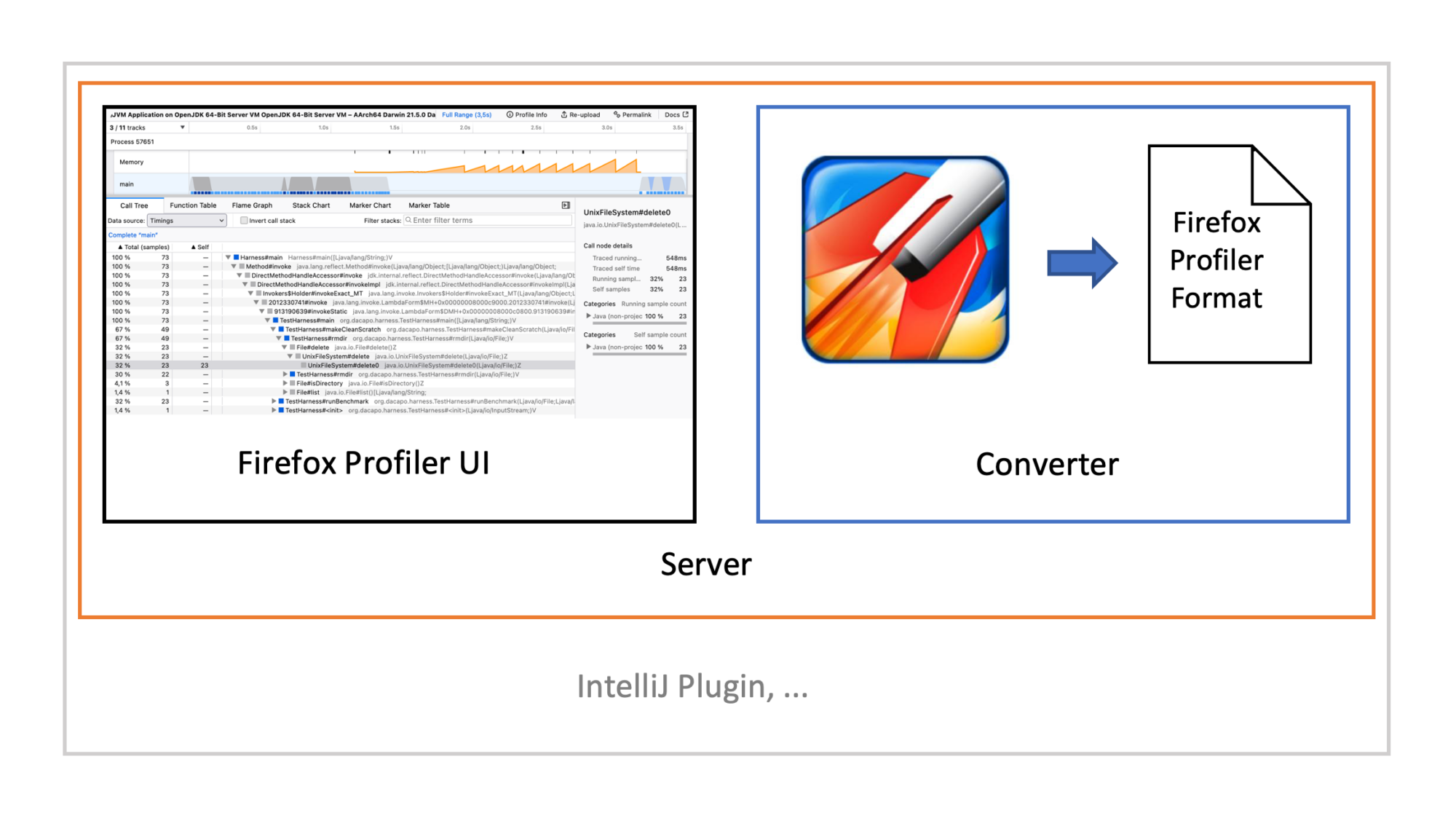
This project is part of my work in the SapMachine team at SAP, making profiling easier for everyone.
At the JavaForumNord two weeks ago, I had a friendly chat with Karl Heinz Marbaise (Chairman of the Apache Maven Project), where he mentioned that he wanted to start profiling maven. This sounded interesting, so I started looking into the performance and bottlenecks of maven. I began by using the Maven build of maven itself as a starting point (excluding the tests). The following is my first observation related to maven builds in CIs.
Maven is one of the most used build systems in the Java ecosystem (JetBrains 2022 survey), and many projects, especially open-source projects, use GitHub Actions to create artifacts and run tests automatically. The free tier of GitHub Actions has two cores (see GitHub docs), so we only have limited parallelism compared to the usual developer machines.
Maven uses the Plexus compiler wrapper Java API around the javax.tools.JavaCompiler API to compile every Java file. The underlying JVM then essentially has three tasks running while compiling:
This is problematic on short builds (like building maven itself in 30s), as the C2 JIT does cost a significant amount of cpu-time, more than is saved by the faster execution of the jitted code. The maven self-built, for example, spent more than half of its cpu-time in the C2 compiler:
Maven 4 (f24266eb64) was built with maven 3.8.7 on SapMachine 17.0.8.1 and profiled with async-profiler; click to view the full flame graph
We can use the information by async-profiler to get the cpu-time proportions for significant parts of the built:
Part
cpu-time percentage
samples
Launcher.main
38 %
3200
C2Compiler::compile_method
47 %
4000
Compiler::compile_method (C1 compiler)
8 %
650
The whole maven build took 44s (82s cpu-time) on two cores of my ThreadRipper 3995WX. Compare this to a run with a disabled C2 which took 41s (50s cpu-time):
Maven 4 (f24266eb64) built with maven 3.8.7 on SapMachine 17.0.8.1 and MVN_OPTS="-XX:TieredStopAtLevel=1" (but stopping at a higher C1 level is unusual, see dzone) profiled with async-profiler, click to view the full flame graph
The proportions are as expected:
Part
cpu-time percentage
samples
Launcher.main
71 %
3700
C2Compiler::compile_method
0 %
0
Compiler::compile_method (C1 compiler)
14 %
750
The time to complete the task changes only by 3s, but the CPU time and, by proxy, the energy use drops significantly. These results are stable over multiple runs with different JDKs.
Side note: Maven only compiles with one thread, compiling with two threads (-T2 option) reduces the build time further by 10 to 15% with C2 and without.
Does this mean that you should always disable C2 in CI builds? No. At a certain project size, the performance increase by the faster, compiled methods outweighs the C2 compilation costs.
Large builds
Take, for example, quarkus: A clean build on two cores runs for 430s (710s cpu-time) with C2 enabled:
Quarkus (af4208a05e) built with maven 3.8.8 on SapMachine 17.0.8.1 and ./mvnd -Dquickly
The runtime proportions are less skewed in the direction of C2:
Part
cpu-time percentage
samples
MavenWrapperMain.main
45 %
39200
C2Compiler::compile_method
30 %
26200
Compiler::compile_method (C1 compiler)
2 %
1750
The built without C2 runs in comparison for 880s (1000s cpu-time), so it doesn’t make any sense to disable C2 with this build. For completeness, the proportion table:
Part
cpu-time percentage
samples
MavenWrapperMain.main
57 %
52700
C2Compiler::compile_method
0 %
0
Compiler::compile_method (C1 compiler)
7 %
6150
Conclusion
Disabling C2 can be an option to speed up builds of smaller Java applications in CI systems, mainly when restricted to one or two CPU cores. I would recommend exploring this for every maven build that runs under a minute, as it is not too hard to integrate (MVN_OPTS="-XX:TieredStopAtLevel=1"), yet might result in less CPU usage. Preliminary findings also show that it reduces memory usage. But my findings also show that it is not helpful for large builds.
I hope you enjoyed this explorative blog post in the realm of JIT compilation. It’s preliminary research; maybe if there’s enough interest, I can do a more thorough investigation. See you in my next blog post on debugging, which should be ready by the end of this week.
Additional Literature: I would recommend reading Startup, containers & Tiered Compilation by Jean-Philippe Bempel if you want to get another take on the impact of C2 on startup time in constrained environments.
This project is part of my work in the SapMachine team at SAP, making profiling easier for everyone. Thank you to Francesco Nigro for the idea to check whether disabling the JIT improves the build times.
Have you ever wondered how debuggers work? What happens when you set a breakpoint and hit it later? Debuggers are tools that we as developers use daily in our work, but few know how they are actually implemented.
Walking only at safepoints has advantages: The main one is that you aren’t walking the stack in a signal handler but synchronously to the executed program. Therefore you can allocate memory, acquire locks and rematerialize virtual thread / Loom frames. The latter is significant because virtual threads are the new Java feature that cannot support using signal-handler-based APIs like AsyncGetCallTrace.
Erik summed up the problems with my previous JEP proposal, and in a way with AsyncGetCallTrace, quite nicely:
Well the current proposal doesn’t have a clear story for 1) Making it safe 2) Working with virtual threads 3) Supporting incremental stack scanning 4) Supporting concurrent stack scanning
He proposed that walking Java threads only at safepoints while obtaining some information in the signal handler might do the trick. So I got to work, implementing an API that does just this.
Idea
The current interaction between a sampler of the profiler and the Java Threads looks like the following:
The sampler thread signals every Java thread using POSIX signals and then obtains the full trace directly in the signal handler while the thread is paused at an arbitrary location. I explored variations of this approach in my post Couldn’t we just Use AsyncGetCallTrace in a Separate Thread?
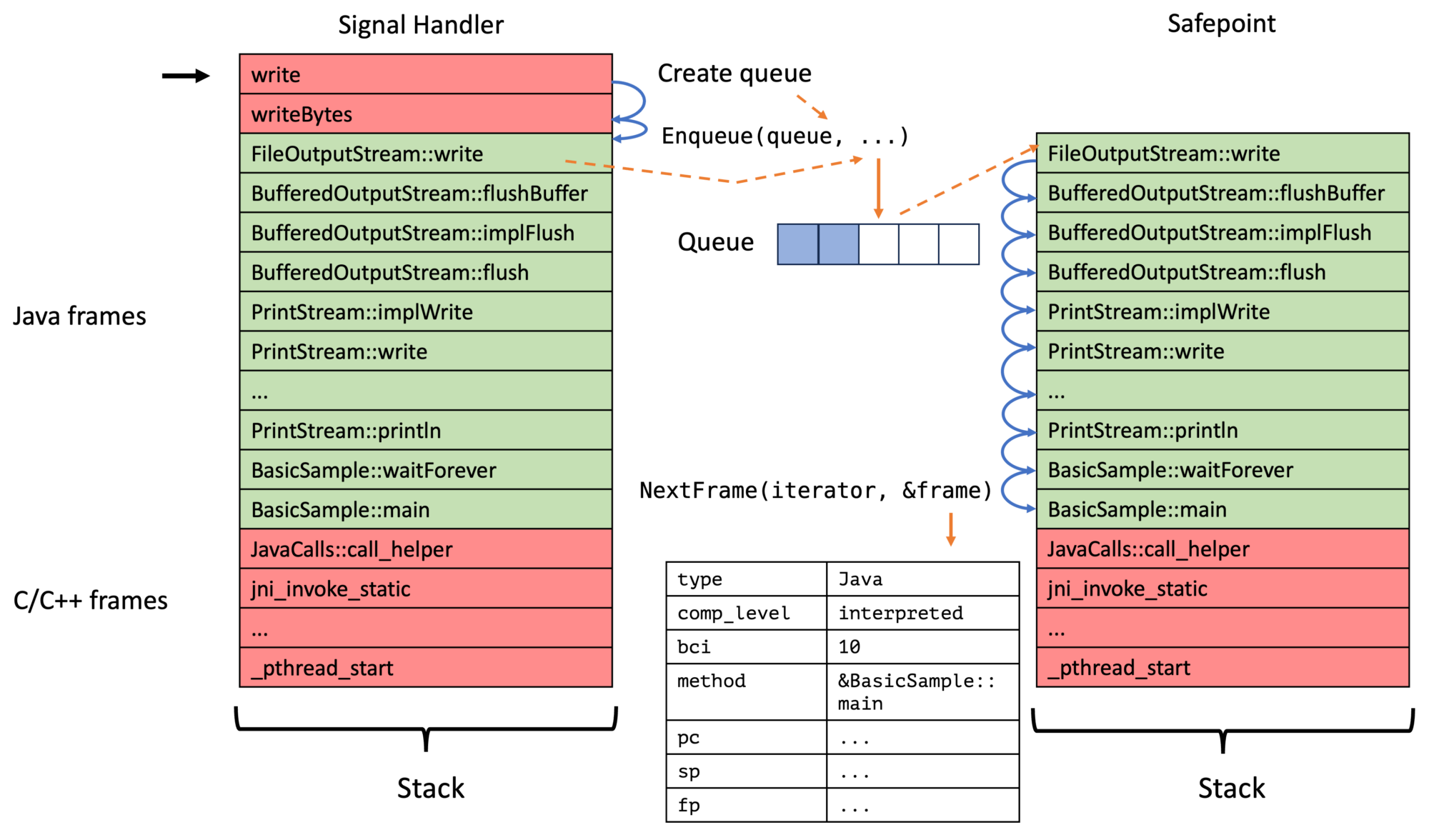
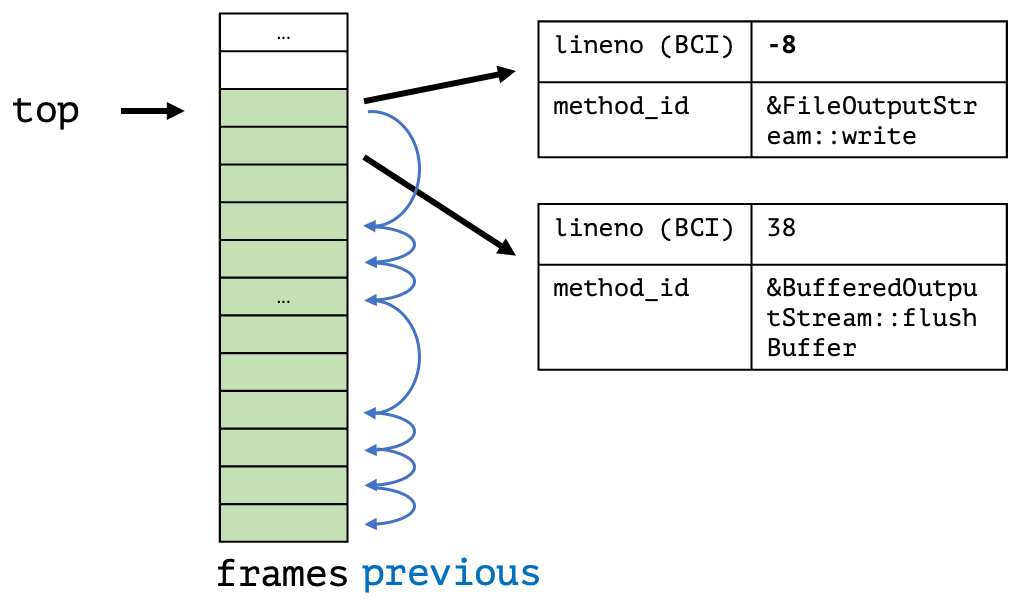
My new approach, on the contrary, walks the Java thread in a signal handler till we find the first bytecode-backed Java frame, stores this in the thread-local queue, triggers a safepoint, and then walks the full Java stack at these safepoints for all enqueued top-frames. We, therefore, have a two-step process:
Instead of just walking the stack in the signal handler:
The new API exploits a few implementation details of the OpenJDK:
There is a safepoint check at least at the end of every non-inlined method (and sometimes there is not, but this is a bug, see The Inner Workings of Safepoints). OpenJ9 doesn’t have checks at returns, so the whole approach I am proposing doesn’t work for them.
When we are at the return of a non-inlined method, we have enough information to obtain all relevant information of the top inlined and the first non-inlined frame using only the program counter, stack pointer, frame pointer, and bytecode pointer obtained in the signal handler. We focus on the first non-inlined method/frame, as inlined methods don’t have physical frames, and walking them would result in walking using Java internal information, which we explicitly want to avoid.
But, in contrast to the other parts of the API, this new safepoint-based part only works when the previously defined conditions hold. This is not the case in OpenJ9, so I propose making the new feature optional. But how do profilers know whether an implementation supports an optional part of the API? By using the ASGST_Capabilities:
// Implementations don't have to implement all methods,
// only the iterator related and those that match
// their capabilities
enum ASGST_Capabilities {
ASGST_REGISTER_QUEUE = 1, // everything safepoint queue related
ASGST_MARK_FRAME = 2 // frame marking related
};
Profilers can query the capability bit map by calling the int ASGST_Capabilities() and should use the signal handler-based approach whenever the capability bit ASGST_REGISTER_QUEUE is absent. ASGST_MARK_FRAME foreshadows a new feature based on stack watermarks, see JEP 376, which I cover in a follow-up blog post. Calling an unsupported API method is undefined.
Now back to the actual API itself. The main two methods of the proposed API are ASGST_RegisterQueue and ASGST_Enqueue. You typically first register a queue for the current thread using ASGST_RegisterQueue, typically in a ThreadStart JVMTI event handler:
typedef void (*ASGST_Handler)(ASGST_Iterator*,
void* queue_arg,
void* arg);
// Register a queue to the current thread
// (or the one passed via env)
// @param fun handler called at a safe point with iterators,
// the argument for RegisterQueue and the argument
// passed via Enqueue
//
// The handler can only call safe point safe methods,
// which excludes all JVMTI methods, but the handler
// is not called inside a signal handler, so allocating
// or obtaining locks is possible
//
// Not signal safe, requires ASGST_REGISTER_QUEUE capability
ASGST_Queue* ASGST_RegisterQueue(JNIEnv* env, int size,
int options, ASGST_Handler fun, void* argument);
A queue has a fixed size and has a registered handler, which is called for every queue item in insertion order at every safepoint, after which the queue elements are removed. Be aware that you cannot obtain the top frames using the queue handler and cannot call any JVMTI methods, but also that you aren’t bound to signal safe methods in the handler.
The ASGST_Enqueue method obtains and enqueues the top frame into the passed queue, as well as triggering a thread-local handshake/safepoint:
// Enqueue the processing of the current stack
// at the end of the queue and return the kind
// (or error if <= 0)
// you have to deal with the top C and native frames
// yourself (but there is an option for this)
//
// @param argument argument passed through
// to the ASGST_Handler for the queue as the third argument
// @return kind or error,
// returns ASGST_ENQUEUE_FULL_QUEUE if queue is full
// or ASGST_ENQUEUE_NO_QUEUE if queue is null
//
// Signal safe, but has to be called with a queue
// that belongs to the current thread, or the thread
// has to be stopped during the duration of this call
// Requires ASGST_REGISTER_QUEUE capability
int ASGST_Enqueue(ASGST_Queue* queue, void* ucontext,
void* argument);
The passed argument is passed directly to the last parameter of the queue handler. Be aware of handling the case that the queue is full. Typically one falls back onto walking the stack in the signal handler or compressing the queue. The elements of a queue, including the arguments, can be obtained using the ASGST_GetQueueElement method:
// Returns the nth element in the queue (from the front),
// 0 gives you the first/oldest element.
// -1 gives you the youngest element, ..., -size the oldest.
//
// Modification of the returned element are allowed,
// as long as the queue's size has not been modified
// between the call to ASGST_GetQueueElement and the
// modification (e.g. by calling ASGST_ResizeQueue).
//
// Modifiying anything besides the arg field
// is highly discouraged.
//
// @returns null if n is out of bounds
//
// Signal safe
ASGST_QueueElement* ASGST_GetQueueElement(ASGST_Queue* queue,
int n);
The critical detail is that modifying the arg field is supported; this allows us to do queue compression: In the signal handler, we obtain the last element in the queue using the ASGST_GetQueueElement method and then get the currently enqueuable element using ASGST_GetEnqueuableElement. We can then check whether both elements are equal and then update the argument, omitting to enqueue the current ucontext.
Another helper method is ASGST_ResizeQueue which can be used to set the queue size:
// Trigger the resizing of the queue at end of the next safepoint
// (or the current if currently processing one)
//
// Signal safe, but has to be called with a queue
// that belongs to the current thread
// Requires ASGST_REGISTER_QUEUE capability
void ASGST_ResizeQueue(ASGST_Queue* queue, int size);
The current queue size and more can be obtained using ASGST_QueueSizeInfo:
typedef struct {
jint size; // size of the queue
jint capacity; // capacity of the queue
jint attempts; // attempts to enqueue since last safepoint end
} ASGST_QueueSizeInfo;
// Returns the number of elements in the queue, its capacity,
// and the number of attempts since finishing the previous
// safepoint
//
// Signal safe, but only proper values in queues thread
ASGST_QueueSizeInfo ASGST_GetQueueSizeInfo(ASGST_Queue* queue);
This returns the defined size/capacity, the current number of elements, and the number of enqueue attempts, including unsuccessful ones. This can be used in combination with ASGST_ResizeQueue to dynamically adjust the size of these queues.
One might want to remove a queue from a thread; this can be done using the non-signal safe method ASGST_DeregisterQueue.
Lastly, one might want to be triggered before and after a non-empty queue is processed:
// Handler that is called at a safe point with enqueued samples
// before and after processing
//
// called with the queue, a frame iterator, and the OnQueue
// argument frame iterator is null if offerIterator at handler
// registration was false
typedef void (*ASGST_OnQueueSafepointHandler)(ASGST_Queue*,
ASGST_Iterator*,
void*);
// Set the handler that is called at a safe point before
// the elements in the (non-empty) queue are processed.
//
// @param before handler or null to remove the handler
//
// Not signal safe, requires ASGST_REGISTER_QUEUE capability
void ASGST_SetOnQueueProcessingStart(ASGST_Queue* queue,
int options, bool offerIterator,
ASGST_OnQueueSafepointHandler before, void* arg);
// Set the handler that is called at a safe point after
// the elements in the (non-empty) queue are processed.
//
// @param after handler or null to remove the handler
//
// Not signal safe, requires ASGST_REGISTER_QUEUE capability
void ASGST_SetOnQueueProcessingEnd(ASGST_Queue* queue,
int options, bool offerIterator,
ASGST_OnQueueSafepointHandler end, void* arg);
This should enable performance optimizations, enabling the profiler to walk the whole stack, e.g., only once per queue processing safepoint.
This is the whole API that can be found in my OpenJDK fork with the profile2.h header. The current implementation is, of course, a prototype; there are, e.g., known inaccuracies with native (C to Java) frames on which I’m currently working.
The best thing: The code gets more straightforward and uses locks to handle concurrency. Writing code that runs at safepoints is far easier than code in signal handlers; the new API moves complexity from the profiler into the JVM.
But first, you have to build and use my modified OpenJDK as before. This JDK has been tested on x86 and aarch64. The profiler API implementation is still a prototype and contains known errors, but it works well enough to build a small profiler. Feel free to review the code; I’m open to help, suggestions, or sample programs and tests.
To use this new API, you have to include the profile2.h header file, there might be some linker issues on Mac OS, so add -L$JAVA_HOME/lib/server -ljvm to your compiler options.
Now to the significant changes to the version that walks the stack in the signal handler written for the previous blog post. First, we have to register a queue into every thread; we do this in the ThreadStart JVMTI event handler and store the result in a thread-local queue variable:
thread_local ASGST_Queue* queue;
// ...
void JNICALL
OnThreadStart(jvmtiEnv *jvmti_env,
JNIEnv* jni_env,
jthread thread) {
// the queue is large, but aren't doing any compression,
// so we need it
queue = ASGST_RegisterQueue(jni_env, 10'000, 0, &asgstHandler,
(void*)nullptr);
// ...
}
We then have to enqueue the last Java frames into the queue in the signal handler:
static void signalHandler(int signo, siginfo_t* siginfo,
void* ucontext) {
totalTraces++;
// queue has not been initialized
if (queue == nullptr) {
failedTraces++;
return;
}
int res = ASGST_Enqueue(queue, ucontext, (void*)nullptr);
if (res != 1) { // not Java trace
failedTraces++;
if (res == ASGST_ENQUEUE_FULL_QUEUE) {
// we could do some compression here
// but not in this example
queueFullTraces++;
}
}
}
We record the total traces, the failed traces, and the number of times the queue had been full. The enqueued frames are processed using the asgstHandler method at every safepoint. This method obtains the current trace and stores it directly in the flame graph, acquiring the lock to prevent data races:
// we can acquire locks during safepoints
std::mutex nodeLock;
Node node{"main"};
void asgstHandler(ASGST_Iterator* iterator, void* queueArg,
void* arg) {
std::vector<std::string> names;
ASGST_Frame frame;
int count;
for (count = 0; ASGST_NextFrame(iterator, &frame) == 1 &&
count < MAX_DEPTH; count++) {
names.push_back(methodToString(frame.method));
}
// lets use locks to deal with the concurrency
std::lock_guard<std::mutex> lock{nodeLock};
node.addTrace(names);
}
That’s all. I might write a blog post on compression in the future, as the queues tend to fill up in wall-clock mode for threads that wait in native.
You can find the complete code on GitHub; feel free to ask any yet unanswered questions. To use the profiler, just run it from the command line as before:
This assumes that you use the modified OpenJDK. MathParser is a demo program that generates and evaluates simple mathematical expressions. The resulting flame graph should look something like this:
Conclusion
The new API can be used to write profilers easier and walk stacks in a safe yet flexible manner. A prototypical implementation of the API showed accuracy comparable to AsyncGetCallTrace when we ignore the native frames. Using the queues offers ample opportunities for profile compression and incremental stack walking, only walking the new stacks for every queue element.
I want to come back to the quote from Erik that I wrote in the beginning, answering his concerns one by one:
Well the current proposal doesn’t have a clear story for 1) Making it safe 2) Working with virtual threads 3) Supporting incremental stack scanning 4) Supporting concurrent stack scanning
Walking at Java frames at safepoints out of signal handlers makes the stack walking safer, and using improved method ids helps with the post-processing.
Walking only at safepoints should make walking virtual threads possible; it is yet to be decided how to expose virtual threads in the API. But the current API is flexible enough to accommodate it.
and 4. Stack watermarks allow profilers to implement incremental and concurrent stack walking, which should improve performance and offer the ability to compress stack traces—more on this in a future blog post.
Thank you for joining me on my API journey; I’m open to any suggestions; please reach me using the typical channels.
Just keep in mind:
This project is part of my work in the SapMachine team at SAP, making profiling easier for everyone.Thanks to Erik Österlund for the basic idea, and to Jaroslav Bachorik for all the feedback and help on the JEP.
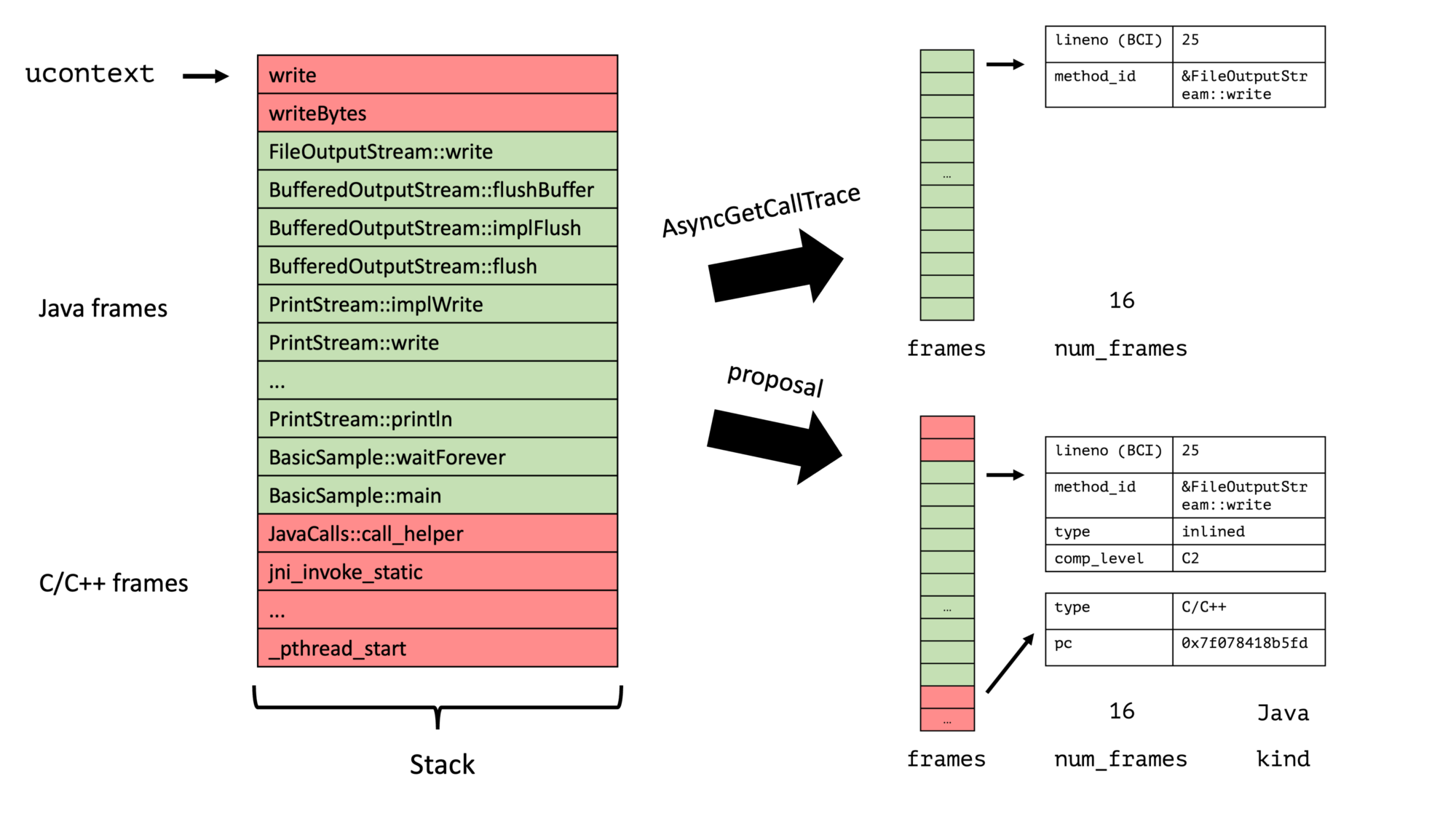
AsyncGetCallTrace is an API to obtain the top n Java frames of a thread asynchronously in a signal handler. This API is widely used but has its problems; see JEP 435 and my various blog posts (AsyncGetStackTrace: A better Stack Trace API for the JVM, jmethodIDs in Profiling: A Tale of Nightmares, …). My original approach with my JEP proposal was to build a replacement of the API, which could be used as a drop-in for AsyncGetCallTrace: Still a single method that populates a preallocated frame list:
No doubt this solves a few of the problems, the new API would be officially supported, return more information, and could return the program counter for C/C++ frames. But it eventually felt more like a band-aid, hindered by trying to mimic AsyncGetCallTrace. In recent months, I had a few discussions with Erik Österlund and Jaroslav Bachorik in which we concluded that what we really need is a completely redesigned profiling API that isn’t just an AsyncGetCallTrace v2.
The new API should be more flexible, safer, and future-proof than the current version. It should, if possible, allow incremental stack scanning and support virtual threads. So I got to work redesigning and, more crucially, rethinking the profiling API inspired by Erik Österlunds ideas.
This blog post is the first of two blog posts covering the draft of a new iterator-based stack walking API, which builds the base for the follow-up blog post on safepoint-based profiling. The following blog post will come out on Wednesday as a special for the OpenJDK Committers’ Workshop.
Iterators
AsyncGetCallTrace fills a preallocated list of frames, which has the most profound expected stack trace length, and many profilers just store away this list. This limits the amount the data we can give for each frame. We don’t have this problem with an iterator-based API, where we first create an iterator for the current stack and then walk from frame to frame:
The API can offer all the valuable information the JVM has, and the profiler developer can pick the relevant information. This API is, therefore, much more flexible; it allows the profiler writer to …
… walk at frames without a limit
… obtain program counter, stack pointer, and frame pointer to use their stack walking code for C/C++ frames between Java frames
… use their compression scheme for the data
don’t worry about allocating too much data on the stack because the API doesn’t force you to preallocate a large number of frames
This API can be used to develop your version of AsyncGetCallTrace, allowing seamless integration into existing applications.
Using the API in a signal handler and writing it using C declarations imposes some constraints, which result in a slightly more complex API which I cover in the following section.
Proposed API
When running in a signal handler, a significant constraint is that we have to allocate everything on the stack. This includes the iterator. The problem is that we don’t want to specify the size of the iterator in the API because this iterator is based on an internal stack walker and is subject to change. Therefore, we have to allocate the iterator on the stack inside an API method, but this iterator is only valid in the method’s scope. This is the reason for the ASGST_RunWithIterator which creates an iterator and passes it to a handler:
// Create an iterator and pass it to fun alongside
// the passed argument.
// @param options ASGST_INCLUDE_NON_JAVA_FRAMES, ...
// @return error or kind
int ASGST_RunWithIterator(void* ucontext,
int32_t options,
ASGST_IteratorHandler fun,
void* argument);
The iterator handler is a pointer to a method in which the ASGST_RunWithIterator calls with an iterator and the argument. Yes, this could be nicer in C++, which lambdas and more, but we are constrained to a C API. It’s easy to develop a helper library in C++ that offers zero-cost abstractions, but this is out-of-scope for the initial proposal.
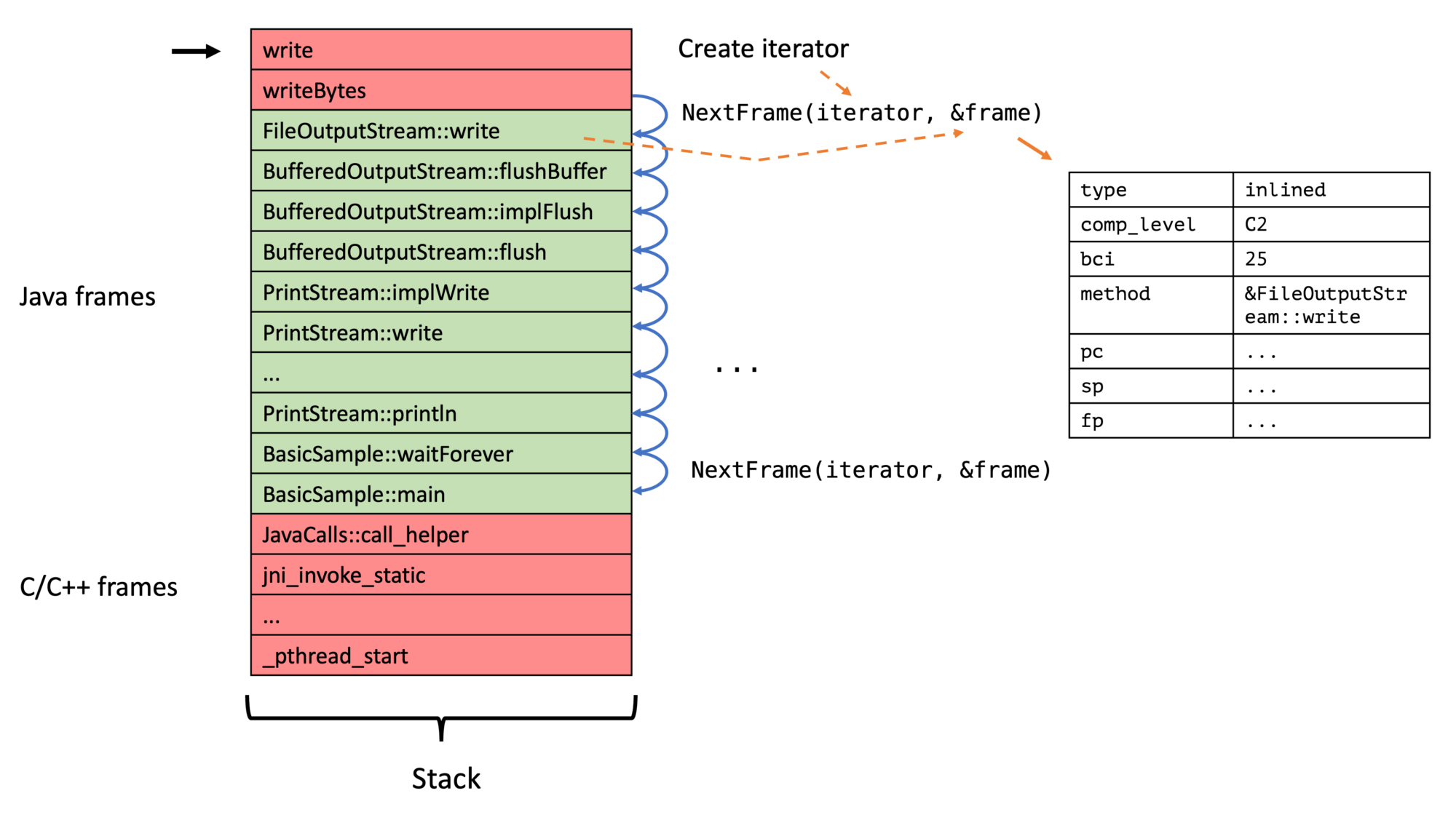
Now to the iterator itself. The main method is ASGST_NextFrame:
// Obtains the next frame from the iterator
// @returns 1 if successful, else error code (< 0) / end (0)
// @see ASGST_State
//
// Typically used in a loop like:
//
// ASGST_Frame frame;
// while (ASGST_NextFrame(iterator, &frame) == 1) {
// // do something with the frame
// }
int ASGST_NextFrame(ASGST_Iterator* iterator, ASGST_Frame* frame);
The frame data structure, as explained in the previous section, contains all required information and is far simpler than the previous proposal (without any union):
enum ASGST_FrameTypeId {
ASGST_FRAME_JAVA = 1, // JIT compiled and interpreted
ASGST_FRAME_JAVA_INLINED = 2, // inlined JIT compiled
ASGST_FRAME_JAVA_NATIVE = 3, // native wrapper to call
// C/C++ methods from Java
ASGST_FRAME_NON_JAVA = 4 // C/C++/... frames
};
typedef struct {
uint8_t type; // frame type
int comp_level; // compilation level, 0 is interpreted,
// -1 is undefined, > 1 is JIT compiled
int bci; // -1 if the bci is not available
// (like in native frames)
ASGST_Method method; // method or nullptr if not available
void *pc; // current program counter
// inside this frame
void *sp; // current stack pointer
// inside this frame, might be null
void *fp; // current frame pointer
// inside this frame, might be null
} ASGST_Frame;
The error codes used both by ASGST_RunWithIterator and ASGST_NextFrame are defined as:
enum ASGST_Error {
ASGST_NO_FRAME = 0, // come to and end
ASGST_NO_THREAD = -1, // thread is not here
ASGST_THREAD_EXIT = -2, // dying thread
ASGST_UNSAFE_STATE = -3, // thread is in unsafe state
ASGST_NO_TOP_JAVA_FRAME = -4, // no top java frame
ASGST_ENQUEUE_NO_QUEUE = -5, // no queue registered
ASGST_ENQUEUE_FULL_QUEUE = -6, // safepoint queue is full
ASGST_ENQUEUE_OTHER_ERROR = -7, // other error,
// like currently at safepoint
// everything lower than -16 is implementation specific
};
ASGST_ENQUEUE_NO_QUEUE and ASGST_ENQUEUE_FULL_QUEUE are not relevant yet, but their importance will be evident in my next blog post.
This API wouldn’t be complete without a few helper methods. We might want to start from an arbitrary frame; for example, we use a custom stack walker for the top C/C++ frames:
// Similar to RunWithIterator, but starting from
// a frame (sp, fp, pc) instead of a ucontext.
int ASGST_RunWithIteratorFromFrame(void* sp, void* fp, void* pc,
int options, ASGST_IteratorHandler fun, void* argument);
The ability to rewind an iterator is helpful too:
// Rewind an interator to the top most frame
void ASGST_RewindIterator(ASGST_Iterator* iterator);
And just in case you want to get the state of the current iterator or thread, there are two methods for you:
// State of the iterator, corresponding
// to the next frame return code
// @returns error code or 1 if no error
// if iterator is null or at end, return ASGST_NO_FRAME,
// returns a value < -16 if the implementation encountered
// a specific error
int ASGST_State(ASGST_Iterator* iterator);
// Returns state of the current thread, which is a subset
// of the JVMTI thread state.
// no JVMTI_THREAD_STATE_INTERRUPTED,
// limited JVMTI_THREAD_STATE_SUSPENDED.
int ASGST_ThreadState();
But how can we use this API? I developed a small profiler in my writing, a profiler from scratch series, which we can now use to demonstrate using the methods defined before. Based on my Writing a Profiler in 240 Lines of Pure Java blog post, I added a flame graph implementation. In the meantime, you can also find the base implementation on GitHub.
Implementing a Small Profiler
First of all, you have to build and use my modified OpenJDK. This JDK has been tested on x86 and aarch64. The profiler API implementation is still a prototype and contains known errors, but it works well enough to build a small profiler. Feel free to review the code; I’m open to help, suggestions, or sample programs and tests.
To use this new API, you have to include the profile2.h header file, there might be some linker issues on Mac OS, so add -L$JAVA_HOME/lib/server -ljvm to your compiler options.
One of the essential parts of this new API is that, as it doesn’t use jmethodID, we don’t have to pre-touch every method (learn more on this in jmethodIDs in Profiling: A Tale of Nightmares). Therefore we don’t need to listen to ClassLoad JVMTI events or iterate over all existing classes at the beginning. So the reasonably complex code
static void JNICALL OnVMInit(jvmtiEnv *jvmti,
JNIEnv *jni_env, jthread thread) {
jint class_count = 0;
env = jni_env;
sigemptyset(&prof_signal_mask);
sigaddset(&prof_signal_mask, SIGPROF);
OnThreadStart(jvmti, jni_env, thread);
// Get any previously loaded classes
// that won't have gone through the
// OnClassPrepare callback to prime
// the jmethods for AsyncGetCallTrace.
JvmtiDeallocator<jclass> classes;
ensureSuccess(jvmti->GetLoadedClasses(&class_count,
classes.addr()),
"Loading classes failed")
// Prime any class already loaded and
// try to get the jmethodIDs set up.
jclass *classList = classes.get();
for (int i = 0; i < class_count; ++i) {
GetJMethodIDs(classList[i]);
}
startSamplerThread();
}
improving the start-up/attach performance of the profiler along the way. To get from the new ASGST_Method identifiers to the method name we need for the flame graph, we don’t use the JVMTI methods but ASGST methods:
static std::string methodToString(ASGST_Method method) {
// assuming we only care about the first 99 chars
// of method names, signatures and class names
// allocate all character array on the stack
char method_name[100];
char signature[100];
char class_name[100];
// setup the method info
ASGST_MethodInfo info;
info.method_name = (char*)method_name;
info.method_name_length = 100;
info.signature = (char*)signature;
info.signature_length = 100;
// we ignore the generic signature
info.generic_signature = nullptr;
// obtain the information
ASGST_GetMethodInfo(method, &info);
// setup the class info
ASGST_ClassInfo class_info;
class_info.class_name = (char*)class_name;
class_info.class_name_length = 100;
// we ignore the generic class name
class_info.generic_class_name = nullptr;
// obtain the information
ASGST_GetClassInfo(info.klass, &class_info);
// combine all
return std::string(class_info.class_name) + "." +
std::string(info.method_name) + std::string(info.signature);
}
This method is then used in the profiling loop after obtaining the traces for all threads. But of course, by then, the ways may be unloaded. This is rare but something to consider as it may cause segmentation faults. Due to this, and for performance reasons, we could register class unload handlers and obtain the method names for the methods of unloaded classes therein, as well as obtain the names of all still loaded used ASGST_Methods when the agent is unattached (or the JVM exits). This will be a topic for another blog post.
Another significant difference between the new API to the old API is that it misses a pre-defined trace data structure. So the profiler requires its own:
struct CallTrace {
std::array<ASGST_Frame, MAX_DEPTH> frames;
int num_frames;
std::vector<std::string> to_strings() const {
std::vector<std::string> strings;
for (int i = 0; i < num_frames; i++) {
strings.push_back(methodToString(frames[i].method));
}
return strings;
}
};
We still use the pre-defined frame data structure in this example for brevity, but the profiler could customize this too. This allows the profiler only to store the relevant information.
We fill the related global_traces entries in the signal handler. Previously we just called:
We use the argument pass-through from ASGST_RunWithIterator to the callback to pass the CallTrace instance where we want to store the traces. We then walk the trace using the ASGST_NextFrame method and iterate till the maximum count is reached, or the trace is finished.
ASGST_RunWithIterator itself is called in the signal handler:
static void signalHandler(int signo, siginfo_t* siginfo,
void* ucontext) {
CallTrace &trace = global_traces[available_trace++];
int ret = ASGST_RunWithIterator(ucontext, 0,
&storeTrace, &trace);
if (ret >= 2) { // non Java trace
ret = 0;
}
if (ret <= 0) { // error
trace.num_frames = ret;
}
stored_traces++;
}
You can find the complete code on GitHub; feel free to ask any yet unanswered questions. To use the profiler, just run it from the command line:
This assumes that you use the modified OpenJDK. MathParser is a demo program that generates and evaluates simple mathematical expressions. I wrote this for a compiler lab while I was still a student. The resulting flame graph should look something like this:
Conclusion
Using an iterator-based profiling API in combination with better method ids offers flexibility, performance, and safety for profiler writers. The new API is better than the old one, but it becomes even better. Get ready for the next blog post in which I tell you about safepoints and why it matters that there is a safepoint-check before unwinding any physical frame, which is the reason why I found a bug in The Inner Workings of Safepoints. So it will all come together.
Thank you for coming this far; I hope you enjoyed this blog post, and I’m open to any suggestions on my profiling API proposal.
This project is part of my work in the SapMachine team at SAP, making profiling easier for everyone.
A Java thread in the JVM regularly checks whether it should do extra work besides the execution of the bytecode. This work is done during so-called safepoints. There are two types of safepoints: local and global. At thread-local safepoints, also known as thread-local handshakes, only the current thread does some work and is therefore blocked from executing the application. At global safepoints, all Java threads are blocked and do some work. At these safepoints, the state of the thread (thread-local safepoints) or the JVM (global safepoints) is fixed. This allows the JVM to do activities like method deoptimizations or stop-the-world garbage collections, where the amount of concurrency should be limited.
But this blog post isn’t about what (global) safepoints are; for this, please refer to Nitsan Wakart’s and Seetha Wenner’s articles on this topic and for thread-local safepoints, which are a relatively recent addition to JEP 312. I’ll cover in this post the actual implementation of safepoints in the OpenJDK and present a related bug that I found along the way.
Global safepoints are implemented using thread-local safepoints by stopping the threads at thread-local safepoints till all threads reach a barrier (source code), so we only have thread-local checks. Therefore I’ll only cover thread-local safepoints here and call them “safepoints.”
The simplest option for implementing safepoint checks would be to add code like
if (thread->at_safepoint()) {
SafepointMechanism::process();
}
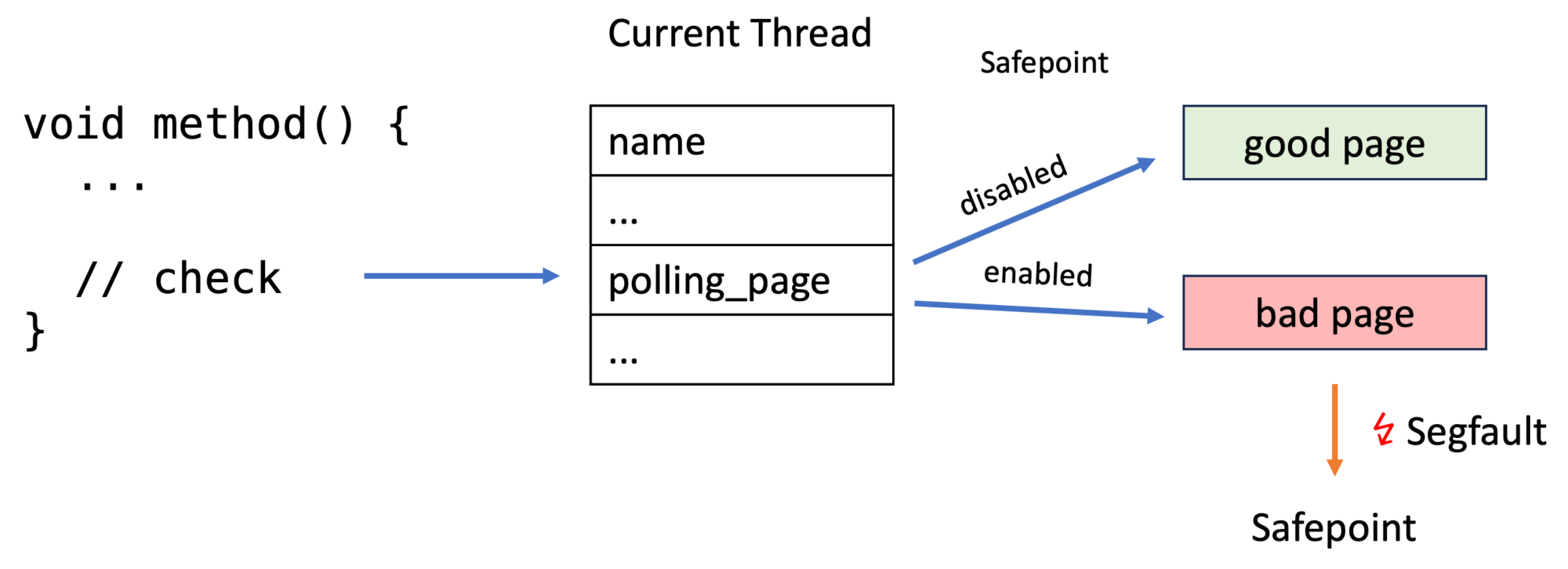
to every location where a safepoint check should occur. The main problem is its performance. We either add lots of code or wrap it in a function and have a function call for every check. We can do better by exploiting the fact that the check often fails, so we can optimize for the fast path of “thread not at safepoint”. The OpenJDK does this by exploiting the page protection mechanisms of modern CPUs (source) in JIT compiled code:
The JVM creates a good and a bad page/memory area for every thread before a thread executes any Java code (source):
The good page can be accessed without issues, but accessing the protected bad page causes an error. os::protect_memory uses the mprotect method under the hood:
mprotect() changes the access protections for the calling
process's memory pages [...].
If the calling process tries to access memory in a manner that
violates the protections, then the kernel generates a SIGSEGV
signal for the process.
prot is a combination of the following access flags: PROT_NONE or
a bitwise-or of the other values in the following list:
PROT_NONE The memory cannot be accessed at all.
PROT_READ The memory can be read.
PROT_WRITE The memory can be modified.
[...]
Now every thread has a field _polling_page which points to either the good page (safepoint check fails) or the bad page (safepoint check succeeds). The segfault handler of JVM then calls the safepoint handler code. Handling segfaults is quite expensive, but this is only used on the slow path; the fast path consists only of reading from the address that _polling_page points to.
In addition to simple safepoints, which trigger indiscriminate of the current program state, Erik Österlund added functionality to parametrize safepoints with JEP 376: The safepoint can be configured to cause a successful safepoint only if the current frame is older than the specified frame, based on the frame pointer. The frame pointer of the specified frame is called a watermark.
Keep in mind that stacks grow from higher to lower addresses. But how is this implemented? It is implemented by adding a _polling_word field next to the _poll_page field to every thread. This polling word specifies the watermark and is checked in the safepoint handler. The configured safepoints are used for incremental stack walking.
The cool thing is that (source) that when enabling the regular safepoint, one sets the watermark to 1 and for disarming it to ~1 (1111...10), so the fp > watermark is always true when the safepoint is enabled (fp > 1 is always true) and false when disabled (fp > 111...10 is always false). Therefore, we can use the same checks for both kinds of safepoints.
More on watermarks and how they can be used to reduce the latency of garbage collectors can be found in the video by Erik:
Bug with Interpreted Aarch64 Methods
The OpenJDK uses multiple compilation tiers; methods can be interpreted or compiled; see Mastering the Art of Controlling the JIT: Unlocking Reproducible Profiler Tests for more information. A common misconception is that “interpreted” means that the method is evaluated by a kind of interpreter loop that has the basic structure:
for (int i = 0; i < byteCode.length; i++) {
switch (byteCode[i].op) {
case OP_1:
...
}
}
The bytecode is actually compiled using a straightforward TemplateInterpreter, which maps every bytecode instruction to a set of assembler instructions. The compilation is fast because there is no optimization, and the evaluation is faster than a traditional interpreter.
The TemplateInterpreter adds safepoint checks whenever required, like method returns. All return instructions are mapped to assembler instructions by the TemplateTable::_return(TosState state) method. On x86, it looks like (source):
This adds the safepoint check using the simple method without page faults (for some reason, I don’t know why), ensuring that a safepoint check is done at the return of every method.
We can therefore expect that when a safepoint is triggered in the interpreted_method in
interpreted_method();
compiled_method();
that the safepoint is handled at least at the end of the method; in our example, the method is too small to have any other safepoints. Yet on my M1 MacBook, the safepoint is only handled in the compiled_method. I found this while trying to fix a bug in safepoint-dependent serviceability code. The cause of the problem is that the TemplateTable::_return(TosState state) is missing the safepoint check generation on aarch64 (source):
void TemplateTable::_return(TosState state)
{
// ...
if (_desc->bytecode() == Bytecodes::_return_register_finalizer){
// ... // finalizers
}
// Issue a StoreStore barrier after all stores but before return
// from any constructor for any class with a final field.
// We don't know if this is a finalizer, so we always do so.
if (_desc->bytecode() == Bytecodes::_return)
__ membar(MacroAssembler::StoreStore);
// ...
__ remove_activation(state);
__ ret(lr);
}
And no the remove_activation method doesn’t check for the safepoint, it only checks for the safepoint (and therefore whether a watermark is set) and calls the InterpreterRuntime::at_unwind method to deal with unwinding of a frame which is related to a watermark. It does not call any safepoint handler related methods.
The same issue is prevalent in the OpenJDK’s riscv and arm ports. The real-world implications of this bug are minor, as the interpreted methods without any inner safepoint checks (in loops, calls to compiled methods, …) seldom run long enough to matter.
I’m neither an expert on the TemplateInterpreter nor on the different architectures. Maybe there are valid reasons to omit this safepoint check on ARM. But if there are not, then it should be fixed; I propose adding something like the following directly before if (_desc->bytecode() == Bytecodes::_return) for aarch64 (source):
Update: Thanks to Leela Mohan Venati on Twitter for spotting that at_safepoint has to be called using call_VM and not super_call_VM_leaf, because at_safepoint is defined using JRT_ENTRY.
I’m happy to hear the opinion of any experts on this topic, the related bug is JBS-8313419.
Conclusion
Understanding the implementation of safepoints can be helpful when working on the OpenJDK. This blog post showed the inner workings, focusing on a bug in the TemplateInterpreter related to the safepoints checks.
Thank you for being with me on this journey down a rabbit hole, and see you next week with a blog post on profiling APIs.
This post is part of my work in the SapMachine team at SAP, making profiling easier for everyone.Thanks to Richard Reingruber, Matthias Baesken, Jaroslav Bachorik, Lutz Schmitz, and Aleksey Shipilëv for their invaluable input.
jmethodIDs identify methods in many low-level C++ JVM API methods (JVMTI). These ids are used in debugging related methods like SetBreakpoint(jvmtiEnv*,jmethodID,jlocation) and, of course, in the two main profiling APIs in the OpenJDK, GetStackTrace, and AsyncGetCallTrace (ASGCT):
JVMTI has multiple helper methods to get the methods name, signature, declaring class, modifiers, and more for a given jmethodID. Using these IDs is, therefore, an essential part of developing profilers but also a source of sorrow:
Honestly, I don’t see a way to use jmethodID safely.
Jaroslav Bachorik, profiler developer
In this blog post, I will tell you about the problems of jmethodID that keep profiler writers awake at night and how I intend to remedy the situation for profiler writers in JEP 435.
Background
But first: What are jmethodIDs, and how are they implemented?
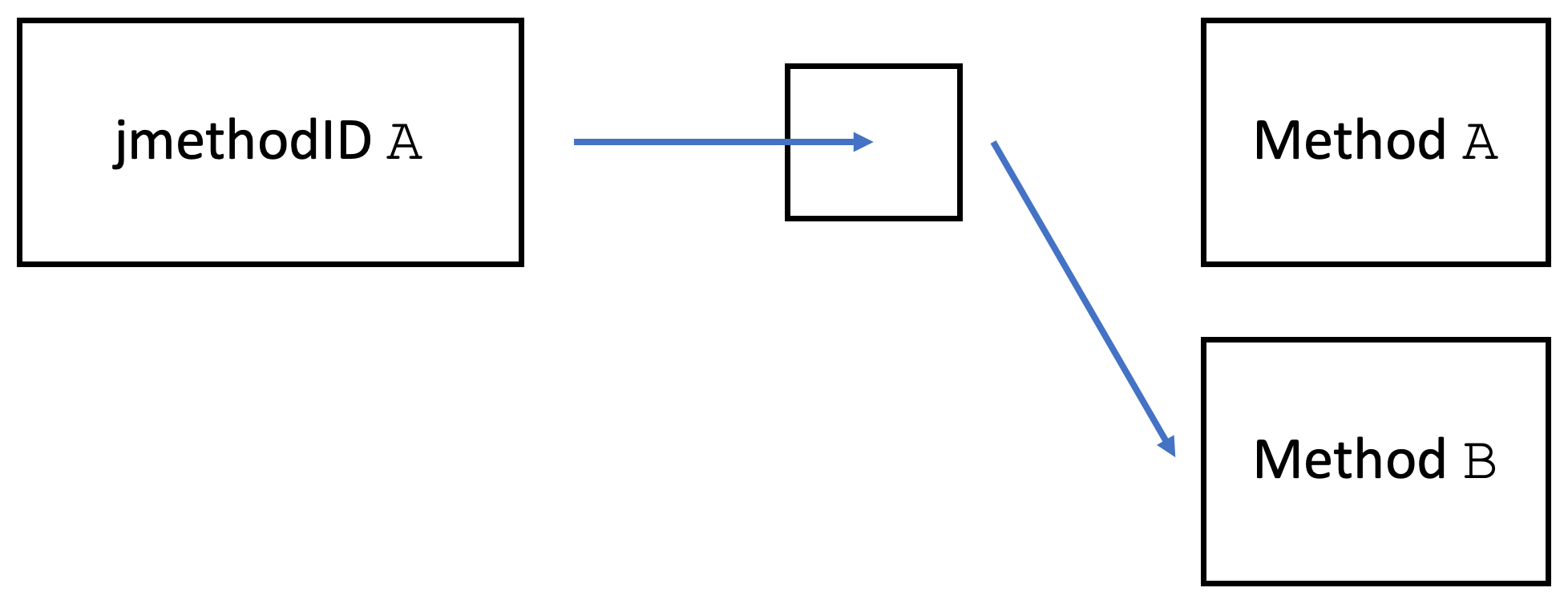
[A jmethodID] identifies a Java programming language method, initializer, or constructor. jmethodIDs returned by JVMTI functions and events may be safely stored. However, if the class is unloaded, they become invalid and must not be used.
In OpenJDK, they are defined as pointers to an anonymous struct (source). Every Java method is backed by an object of the Method class in the JDK. jmethodIDs are actually just pointing to a pointer that points to the related method object (source):
This is not true for jclass, the jmethodID pendant for classes that points directly to a class object:
The jclass becomes invalid if the class is redefined.
jmethodIDs are allocated on demand because they can stay with the JVM till the defining class is unloaded. The indirections for all ids are stored in the jmethodID cache of the related class (source). This cache has a lock to guard its parallel access from different threads, and the cache is dynamically sized (similar to the ArrayList implementation) to conserve memory.
OpenJ9 also uses an indirection (source), but my understanding of the code base is too limited to make any further claims, so the rest of the blog post is focused on OpenJDK. Now over to the problems for profiler writers:
Problems
The fact that jmethodIDs are dynamically allocated in resizable caches causes major issues: Common profilers, like async-profiler, use AsyncGetCallTrace, as stated in the beginning. ASGCT is used inside signal handlers where obtaining a lock is unsupported. So the profiler has to ensure that every method that might appear in a trace (essentially every method) has an allocated jmethodID before the profiling starts. This leads to significant performance issues when attaching profilers to a running JVM. This is especially problematic in OpenJDK 8:
[…] the quadratic complexity of creating new jmethodIDs during class loading: for every added jmethodID, HotSpot runs a linear scan through the whole list of previously added jmethodIDs trying to find an empty slot, when there are usually none. In extreme cases, it took hours (!) to attach async-profiler to a running JVM that had hundreds thousands classes: https://github.com/async-profiler/async-profiler/issues/221
Andrei Pangin, developer of Async-Profiler
A jmethodID becomes invalid when its defining class is unloaded. Still, there is no way for a profiler to know when a jmethodID becomes invalid or even get notified when a class is unloaded. So processing a newly observed jmethodID and obtaining the name, signature, modifiers, and related class, should be done directly after obtaining the id. But this is impossible as all accessor methods allocate memory and thereby cannot be used in signal handlers directly after AsyncGetCallTrace invocations.
As far as I know, methods can be unloaded concurrently to the native code executing JVMTI functions. This introduces a potential race condition where the JVM unloads the methods during the check->use flow, making it only a partial solution. To complicate matters further, no method exists to confirm whether a jmethodID is valid.
Theoretically, we could monitor the CompiledMethodUnload event to track the validity state, creating a constantly expanding set of unloaded jmethodID values or a bloom filter, if one does not care about few potential false positives. This strategy, however, doesn’t address the potential race condition, and it could even exacerbate it due to possible event delays. This delay might mistakenly validate a jmethodID value that has already been unloaded, but for which the event hasn’t been delivered yet.
Honestly, I don’t see a way to use jmethodID safely unless the code using it suspends the entire JVM and doesn’t resume until it’s finished with that jmethodID. Any other approach might lead to JVM crashes, as we’ve observed with J9.
(Concurrent) class unloading, therefore, makes using all profiling APIs inherently unsafe.
jclass ids suffer from the same problems, but ses, we could just process all jmethodIDs and jclass ids, whenever a class is loaded and store all information on all classes, but this would result in a severe performance penalty, as only a subset of all methods actually appears in the observed traces. This approach feels more like a hack.
While jmethodIDs are pretty helpful for other applications like writing debuggers, they are unsuitable for profilers. As I’m currently in the process of developing a new profiling API, I started looking into replacements for jmethodIDs that solve all the problems mentioned before:
Solution
My solution to all these problems is ASGST_Method and ASGST_Class, replacements for jmethodID and jclass, with signal-safe helper methods and a proper notification mechanism for class, unloads, and redefinitions.
The level of indirection that jmethodID offers is excellent, but directly mapping ASGST_Method to method objects removes the problematic dynamic jmethodID allocations. The main disadvantage is that class redefinitions cause a method to have a new ASGST_Method id and a new ASGST_Class id. We solve this the same way JFR solves it:
We use a class local id (idnum) for every method and a JVM internal class idnum, which are both redefinition invariant. The combination of class and method idnum (cmId) is then a unique id for a method. The problem with this approach is that mapping a cmId to an ASGST_Method or a method object is prohibitively expensive as it requires the JVM to check all methods of all classes. Yet this is not a problem in the narrow space of profiling, as a self-maintained mapping from a cmId to collected method information is enough.
The primary method for getting the method information, like name and signature, is ASGST_GetMethodInfo in my proposal:
// Method info
// You have to preallocate the strings yourself
// and store the lengths in the appropriate fields,
// the lengths are set to the respective
// string lengths by the VM,
// be aware that strings are null-terminated
typedef struct {
ASGST_Class klass;
char* method_name;
jint method_name_length;
char* signature;
jint signature_length;
char* generic_signature;
jint generic_signature_length;
jint modifiers;
jint idnum; // class local id, doesn't change with redefinitions
jlong class_idnum; // class id that doesn't change
} ASGST_MethodInfo;
// Obtain the method information for a given ASGST_Method and
// store it in the pre-allocated info struct.
// It stores the actual length in the *_len fields and
// a null-terminated string in the string fields.
// A field is set to null if the information is not available.
//
// Signal safe
void ASGST_GetMethodInfo(ASGST_Method method,
ASGST_MethodInfo* info);
jint ASGST_GetMethodIdNum(ASGST_Method method);
The similar ASGST_Class related is ASGST_GetClassInfo:
// Class info, like the method info
typedef struct {
char* class_name;
jint class_name_length;
char* generic_class_name;
jint generic_class_name_length;
jint modifiers;
jlong idnum; // id, doesn't change with redefinitions
} ASGST_ClassInfo;
// Similar to GetMethodInfo
//
// Signal safe
void ASGST_GetClassInfo(ASGST_Class klass,
ASGST_ClassInfo* info);
jlong ASGST_GetClassIdNum(ASGST_Class klass);
Both methods return a subset of the information available through JVMTI methods. The only information missing that is required for profilers is the mapping from method byte-code index to line number:
typedef struct {
jint start_bci;
jint line_number;
} ASGST_MethodLineNumberEntry;
// Populates the method line number table,
// mapping BCI to line number.
// Returns the number of written elements
//
// Signal safe
int ASGST_GetMethodLineNumberTable(ASGST_Method method,
ASGST_MethodLineNumberEntry* entries, int length);
All the above methods are signal safe so the profiler can process the methods directly. Nonetheless, I propose conversion methods so that the profiler writer can use jmethodIDs and jclass ids whenever needed, albeit with the safety problems mentioned above:
The last part of my proposal deals with invalid class and method ids: I propose a call-back for class unloads, and redefinitions, which is called shortly before the class and the method ids become invalid. In this handler, the profiler can execute its own code, but no JVMTI methods and only the ASGST_* methods that are signal-safe.
Remember that the handler can be executed concurrently, as classes can be unloaded concurrently. Class unload handlers must have the following signature:
These handlers can be registered and deregistered:
// Register a handler to be called when class is unloaded
//
// not signal and safe point safe
void ASGST_RegisterClassUnloadHandler(
ASGST_ClassUnloadHandler handler, void* arg);
// Deregister a handler to be called when a class is unloaded
// @returns true if handler was present
//
// not signal and safe point safe
bool ASGST_DeregisterClassUnloadHandler(
ASGST_ClassUnloadHandler handler, void* arg);
The arg parameter is passed directly to the handler as context information. This is due to the non-existence of proper closures or lambdas in C.
You might wonder we my API would allow multiple handlers. This is because a JVM should support multiple profilers at once.
Conclusion
jmethodIDs are unusable for profiling and cause countless errors, as every profiler will tell you. In this blog post, I offered a solution I want to integrate into the new OpenJDK profiling API (JEP 435). My proposal provides the safety that profiler writers crave. If you have any opinions on this proposal, please let me know. You can find a draft implementation can be found on GitHub.
See you next week with a blog post on safe points and profiling.
This project is part of my work in the SapMachine team at SAP, making profiling easier for everyone.Thanks to Martin Dörr, Andrei Pangin, and especially Jaroslav Bachorik for their invaluable input on my proposal and jmethodIDs.
My goal is to write a blog post every two weeks, it’s great to stick to a schedule and force yourself to publish pieces even if they are not perfect. This doesn’t mean that these blog posts are terrible, just that they could need a bit more polish or could cover a bit more of the topic. But I know many people that have dozens of half-finished blog posts in their pipeline, which aren’t just there and so they don’t publish anything for months. Having a rather strict schedule pushes me to create content early and often, helping me to finalize and write down my ideas on a regular basis.
But sometimes… Well sometimes I’m behind schedule (didn’t write a blog post this week and the week before) and I could force myself to write a blog post, or …
… just climb up a castle and enjoy being around friends, looking into the sunset. A blog post can wait a week, but life can’t:
Life is what happens to us while we are making other plans.
Allen Saunders, John Lennon
So go out, visit the world, have friends, and read my blog post on flame-graph construction mid-next week.
This blog post was not supported by SAP, just by my awesome friends who rented accommodation for 30 people near Falkenstein to have a nice weekend.
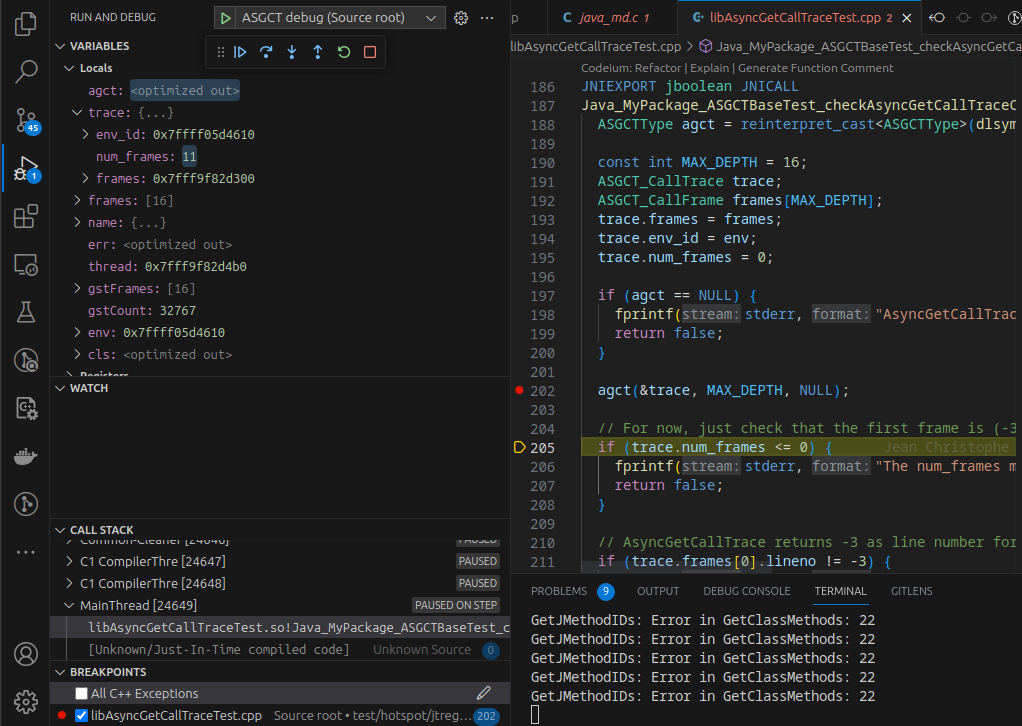
Consider you want to debug a test case of the JDK like serviceability/AsyncGetCallTrace. This test, and many others, are implemented using the Regression Test Harness for the JDK (jtreg):
jtreg is the test harness used by the JDK test framework. This framework is intended primarily for regression tests. It can also be used for unit tests, functional tests, and even simple product tests — in other words, just about any type of test except a conformance test, which belong in a TCK.
As well as API tests, jtreg is designed to be well suited for running both positive and negative compiler tests, simple manual GUI tests, and (when necessary) tests written in shell script. jtreg also takes care of compiling tests as well as executing them, so there is no need to precompile any test classes.
https://openjdk.org/jtreg/
JTREG is quite powerful, allowing you to combine C++ and Java code, but it makes debugging the C++ parts hard. You could, of course, just debug using printf. This works but also requires lots of recompiles during every debugging session. Attaching a debugger like gdb is possible but rather cumbersome, especially if you want to bring this into a launch.json to enable debugging in VSCode.
But worry no more: My new vsreg utility will do this for you 🙂 You can obtain the tool by just cloning its GitHub repository:
git clone https://github.com/parttimenerd/vsreg
Then pass the make test command to it, which you use to run the test that you want to debug:
vsreg/vsreg.py "ASGCT debug" -- make test TEST=jtreg:test/hotspot/jtreg/serviceability/AsyncGetCallTrace JTREG="VERBOSE=all"
Be sure always to pass JTREG="VERBOSE=all": vsreg executes the command, parses the output, and adds a launch config with the label “ASGCT debug” to the .vscode/launch.json file in the current folder.
The utility is MIT licensed and only tested on Linux. Update: Works also on Mac with lldb.
Example Usage
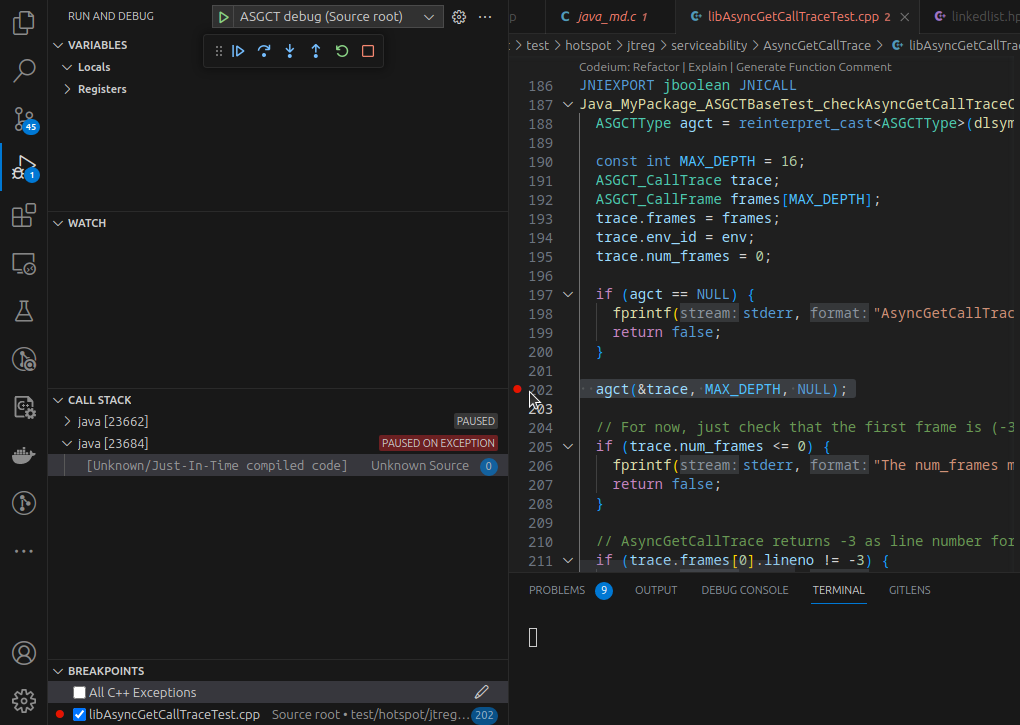
You’re now able to select “ASGCT debug” in “Run and Debug”:
You can choose the launch config and run the jtreg test with a debugger:
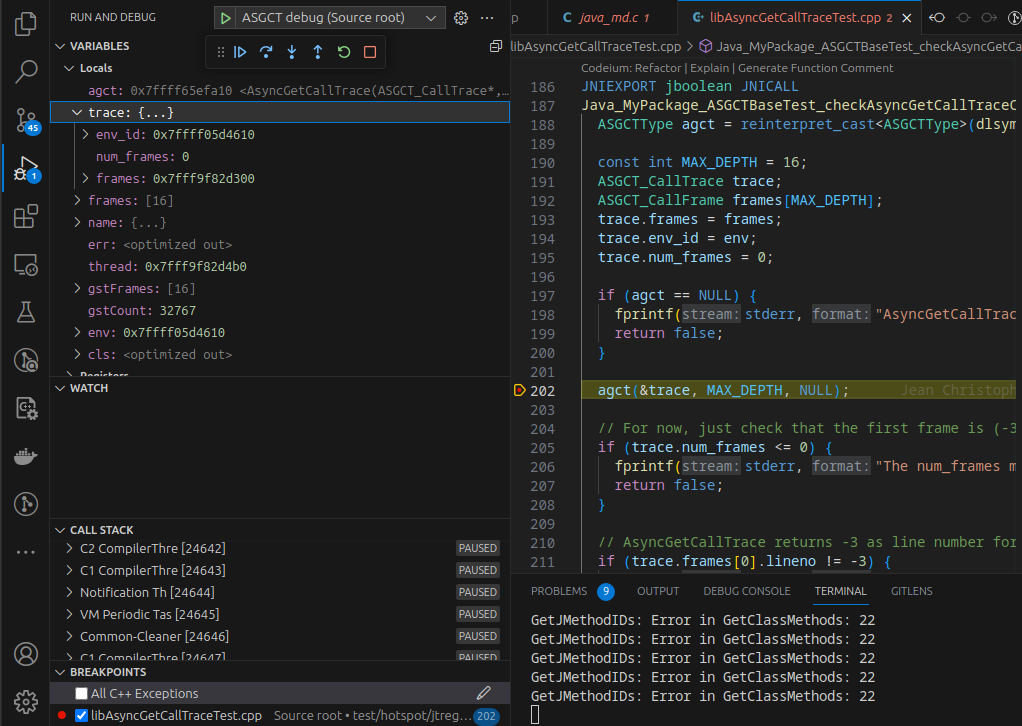
The debugger pauses on a segfault, but there are always a few at the beginning of the execution that can safely be ignored. We can use the program’s pause to add a break-point at an interesting line. After hitting the break-point, we’re able to inspect the local variables…
… and do things like stepping over a line:
Recompilation
If you want to recompile the tests, use make images test-image. You can add a task to your .vscode/tasks.json file and pass the label to the --build-task option:
usage: vsreg.py [-h] [-t TEMPLATE] [-d] [-b TASK] LABEL COMMAND [COMMAND ...]
Create a debug launch config for a JTREG test run
positional arguments:
LABEL Label of the config
COMMAND Command to run
options:
-h, --help show this help message and exit
-t TEMPLATE, --template TEMPLATE
Template to use for the launch config,
or name of file without suffix in
vsreg/template folder
-d, --dry-run Only print the launch config
-b TASK, --build-task TASK
Task to run before the command
An example template looks like this:
{
"name": "$NAME",
"type": "cppdbg",
"request": "launch",
"program": "",
"args": [],
"stopAtEntry": false,
"cwd": "",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"miDebuggerPath": "/usr/bin/gdb",
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
},
{
"description": "The new process is debugged after a fork. The parent process runs unimpeded.",
"text": "-gdb-set follow-fork-mode child",
"ignoreFailures": true
}
],
"preLaunchTask": ""
}
vsreg fills in $NAME (with the label), program (with the used Java binary), args, cwd, environment and preLaunchTask.
Conclusion
vsreg is one of these utilities that solve one specific itch: I hope it also helps others; feel free to contribute to this tool, adding new templates and other improvements on GitHub.
The tool is inspired by bear, “a tool that generates a compilation database for clang tooling.”
If you’re wondering why I have a renewed interest in debugging: I’m working full-time on a new proof-of-concept implementation related to JEP 435.
Update 14th July
vsreg now supports creating debug launch configurations for arbitrary commands, e.g. vsreg/vsreg.py "name" -- command, and supports mac os with LLDB. I use this tool daily at work, so feel free to submit any suggestions, I’m happy to further extend this tool.
This project is part of my work in the SapMachine team at SAP, making profiling easier for everyone.
A visualization of all the cities I visited, but I took the train for all transits (except for the Arnhem to Nieuwegein route, where Ties van de Ven drove me in his Tesla).
It was an exciting trip, and I had the pleasure of visiting friends in Zurich and Augsburg and a grain mill shop in Munich.
Sadly there are only recordings of two of my seven talks, but all talks were excellent:
Being in Milan for the first time was fantastic. I was able to stay with Mario Fusco for a few days to enjoy the beauty of Gorgonzola, the suburb of Milan where he lives, and also visit the famous Museo Nazionale della Scienza e della Tecnologia Leonardo da Vinci:
My last two talks in Karlsruhe were my profiling talk from before and a talk with live coding based on my writing a profiler from scratch series.
Conclusion
Giving so many talks during two weeks was interesting, although it proved more taxing than I had hoped. I’m happy to start working on my JEP and fixing bugs; a significant rewrite of the JEP might be on the horizon. The following blog post will probably be related.
If you want to see me giving a talk, either invite me or come to the following few planned talks:
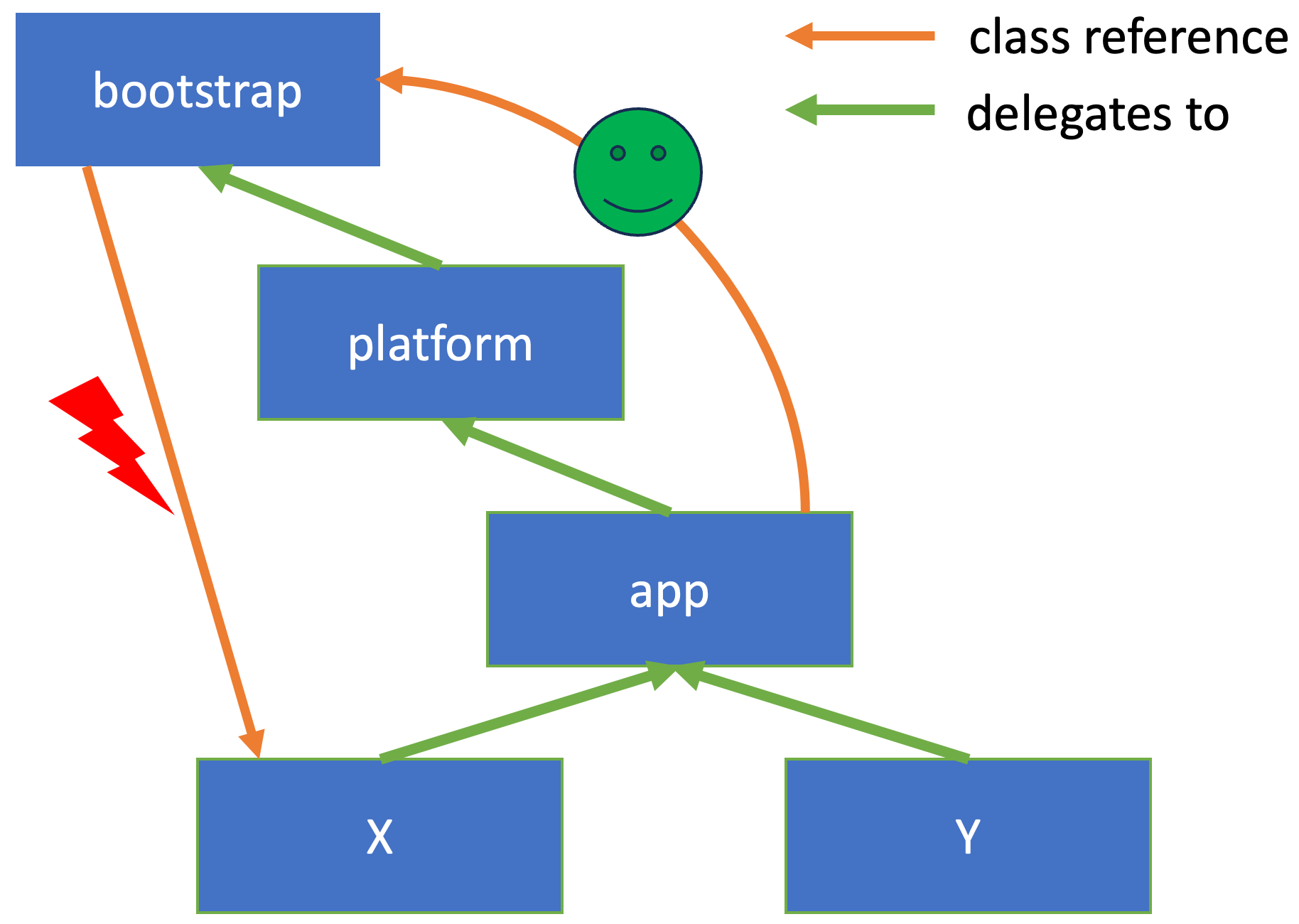
Understanding class loader hierarchies is essential when developing Java agents, especially if these agents are instrumenting code. In my Instrumenting Java Code to Find and Handle Unused Classes post, I instrumented all classes with an agent and used a Store class in this newly added code:
A challenge here is that all instrumented classes will use the Store. We, therefore, have to put the store onto the bootstrap classpath, making it visible to all classes.
Class loaders are responsible for (possibly dynamically) loading classes, and they form a hierarchy:
A class loader is an object that is responsible for loading classes. The class ClassLoader is an abstract class. Given the binary name of a class, a class loader should attempt to locate or generate data that constitutes a definition for the class. A typical strategy is to transform the name into a file name and then read a “class file” of that name from a file system.
[…]
The ClassLoader class uses a delegation model to search for classes and resources. Each instance of ClassLoader has an associated parent class loader. When requested to find a class or resource, a ClassLoader instance will usually delegate the search for the class or resource to its parent class loader before attempting to find the class or resource itself.
A typical Java application has a bootstrap class loader (internal JDK classes and the ClassLoader class itself, implemented in C++ code), a platform classloader (all other JDK classes), and an application/system class loader (application classes):
Bootstrap class loader. It is the virtual machine’s built-in class loader, typically represented as null, and does not have a parent.
Platform class loader. The platform class loader is responsible for loading the platform classes. Platform classes include Java SE platform APIs, their implementation classes and JDK-specific run-time classes that are defined by the platform class loader or its ancestors. The platform class loader can be used as the parent of a ClassLoader instance. […]
System class loader. It is also known as application class loader and is distinct from the platform class loader. The system class loader is typically used to define classes on the application class path, module path, and JDK-specific tools. The platform class loader is the parent or an ancestor of the system class loader, so the system class loader can load platform classes by delegating to its parent.
An application might create more class loaders to load classes, e.g., from JARs or do some access control; these classes typically have the application class loader as their parent.
Classes loaded by the application class loader (or children of it) can reference JDK classes but not vice versa. This leads to the problem mentioned before. We can mitigate this by putting all classes that our instrumentation-generated code uses into a runtime JAR which we then “put” on the bootstrap class path.
But we don’t put it there but instead tell the bootstrap class loader to also look into our runtime JAR when looking for a class. We do this by using the method void appendToBootstrapClassLoaderSearch(JarFile jarfile) of the Instrumentation class:
Specifies a JAR file with instrumentation classes to be defined by the bootstrap class loader.
When the virtual machine’s built-in class loader, known as the “bootstrap class loader”, unsuccessfully searches for a class, the entries in the JAR file will be searched as well.
This method may be used multiple times to add multiple JAR files to be searched in the order that this method was invoked.
But the documentation also tells us that you can create a giant mess when you aren’t careful, including only the minimal number of required classes in the added JAR:
The agent should take care to ensure that the JAR does not contain any classes or resources other than those to be defined by the bootstrap class loader for the purpose of instrumentation. Failure to observe this warning could result in unexpected behavior that is difficult to diagnose. For example, suppose there is a loader L, and L’s parent for delegation is the bootstrap class loader. Furthermore, a method in class C, a class defined by L, makes reference to a non-public accessor class C$1. If the JAR file contains a class C$1 then the delegation to the bootstrap class loader will cause C$1 to be defined by the bootstrap class loader. In this example an IllegalAccessError will be thrown that may cause the application to fail. One approach to avoiding these types of issues, is to use a unique package name for the instrumentation classes.
You have to append the classes to the search path before (!) the first reference of the classes, as a class that cannot be resolved when first referenced will never be adequately resolved.
More information on class loaders can be found in the Baeldung article Class Loaders in Java.
How to get the class loader hierarchy of your project
I wanted to know the class loader hierarchy for my own projects, so of course, I wrote an agent for it: The ClassLoader Hierarchy Agent prints the class loader hierarchy at agent load time, the JVM shutdown, and in regular intervals.
Its usage is quite simple. Just attach it to a JVM or add it at startup:
Usage: java -javaagent:classloader-hierarchy-agent.jar[=maxPackages=10,everyNSeconds=0] <main class>
maxPackages: maximum number of packages to print per classloader
every: print the hierarchy every N seconds (0 to disable)
For the finagle-httprenaissance benchmark, the agent, for example, prints the following when the benchmark is in full swing:
The root node is the bootstrap class loader. For every class loader, it gives us a thread that uses it as its primary class loader, a short list of packages associated with the class loader, and its child class loaders.
Class loaders can have names, but sadly not many class loader creators use this feature, which turns understanding the individual class loader hierarchies into a guessing game. This is especially the case for Spring based applications like the Spring PetClinic:
Feel free to try this agent on your applications; maybe you gain some new insights.
Conclusion
Understanding class loader hierarchies helps to understand subtle problems in writing instrumenting agents. Knowing how to write small agents can empower you to write simple tools to understand the properties of your application.
I hope this blog post helped you to understand class loader hierarchies and agents a little bit better. I’m writing it in a lovely park in Milan:
In my last blog post, I hinted Using Async-Profiler and Jattach Programmatically with AP-Loader, that I’m currently working on a test library for writing better profiling API tests. The library is still work-in-progress, but it already allows you to write profiling API tests in plain Java:
private int innerASGCT2() {
new Tracer().runASGCT().assertTrue(
Frame.hasMethod(0, "innerASGCT2", "()I"),
Frame.hasMethod(1, "testRunASGCT2"));
return 0;
}
@Test
public void testRunASGCT2() {
innerASGCT2();
}
This test case checks that calling AsyncGetCallTrace gives the correct result in this specific example. The test library allows you to write tests comparing the returns of multiple GetStackTrace, AsyncGetCallTrace, and AsyncGetStackTrace invocations in different modes and settings. The library can be found as trace-tester on GitHub; I aim to bring it into the OpenJDK later with my JEP.
Writing small test cases this way is great, but it would be even better if we could force specific methods to be compiled, interpreted, or inlined so that we can test different scenarios. The proposed AsyncGetStackTrace will return the compilation level directly for every frame, so it is necessary to check the correctness of the level too.
Consider reading my Validating Java Profiling APIs post to get a different angle on profiling API testing.
Introduction
Before I start with discussing the ways you can force methods to be compiled, interpreted, or inlined, I’ll have to clarify that:
The following only works with the HotSpot tired JIT compiler and not other JVM’s like OpenJ9 (see issue #11272)
It should only be used for testing. I would refrain from using it anywhere near production, even if you know that specific methods should be compiled. Use a tool like JITWatch by Chris Newland to check whether the JVM doesn’t make the correct decisions automatically: Ask your fellow JVM expert how to deal with this.
I’m not an expert in the APIs I’m showing you, nor in tiered compilation, so be aware that I might be missing something, but I’m happy for any suggestions and corrections.
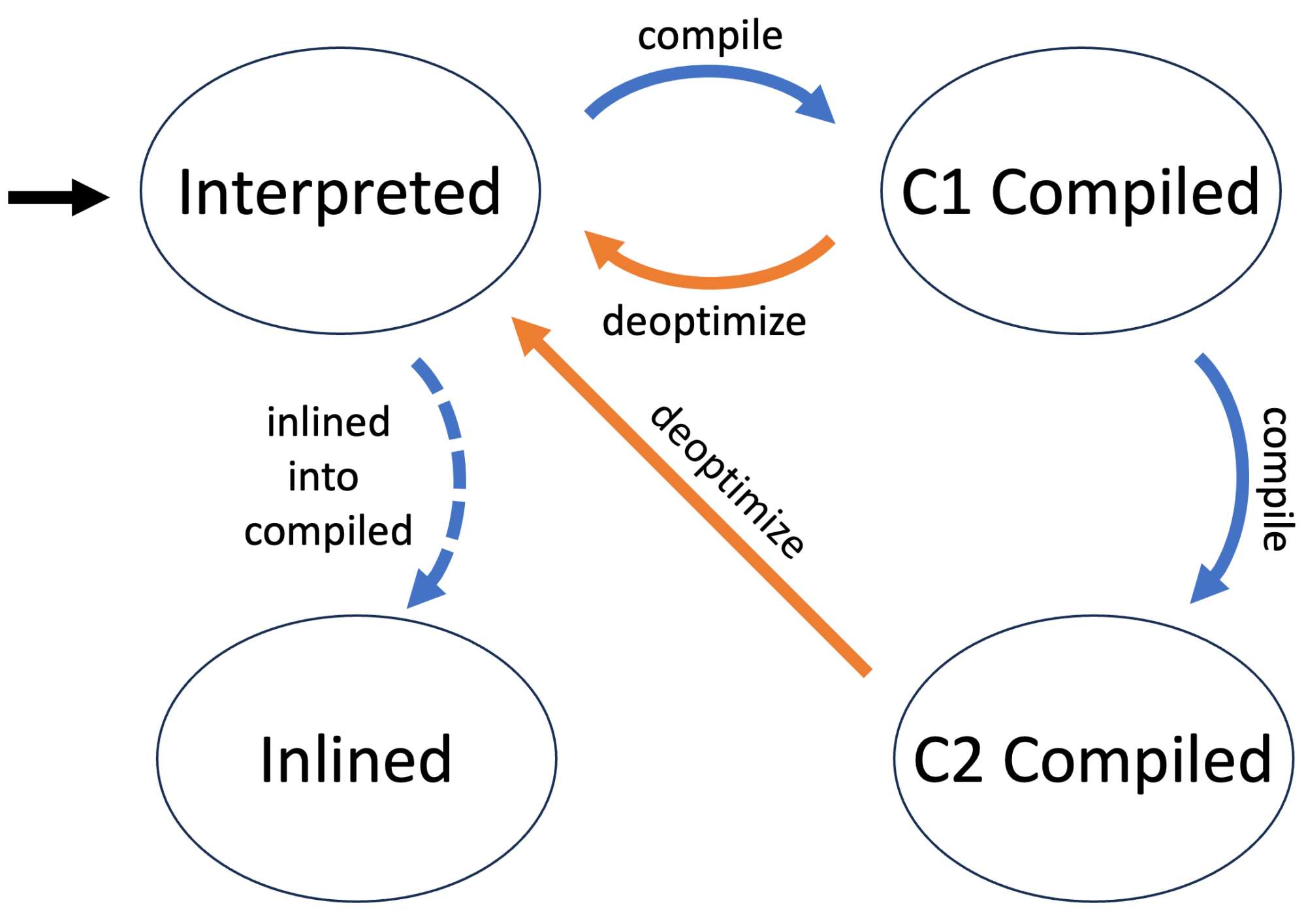
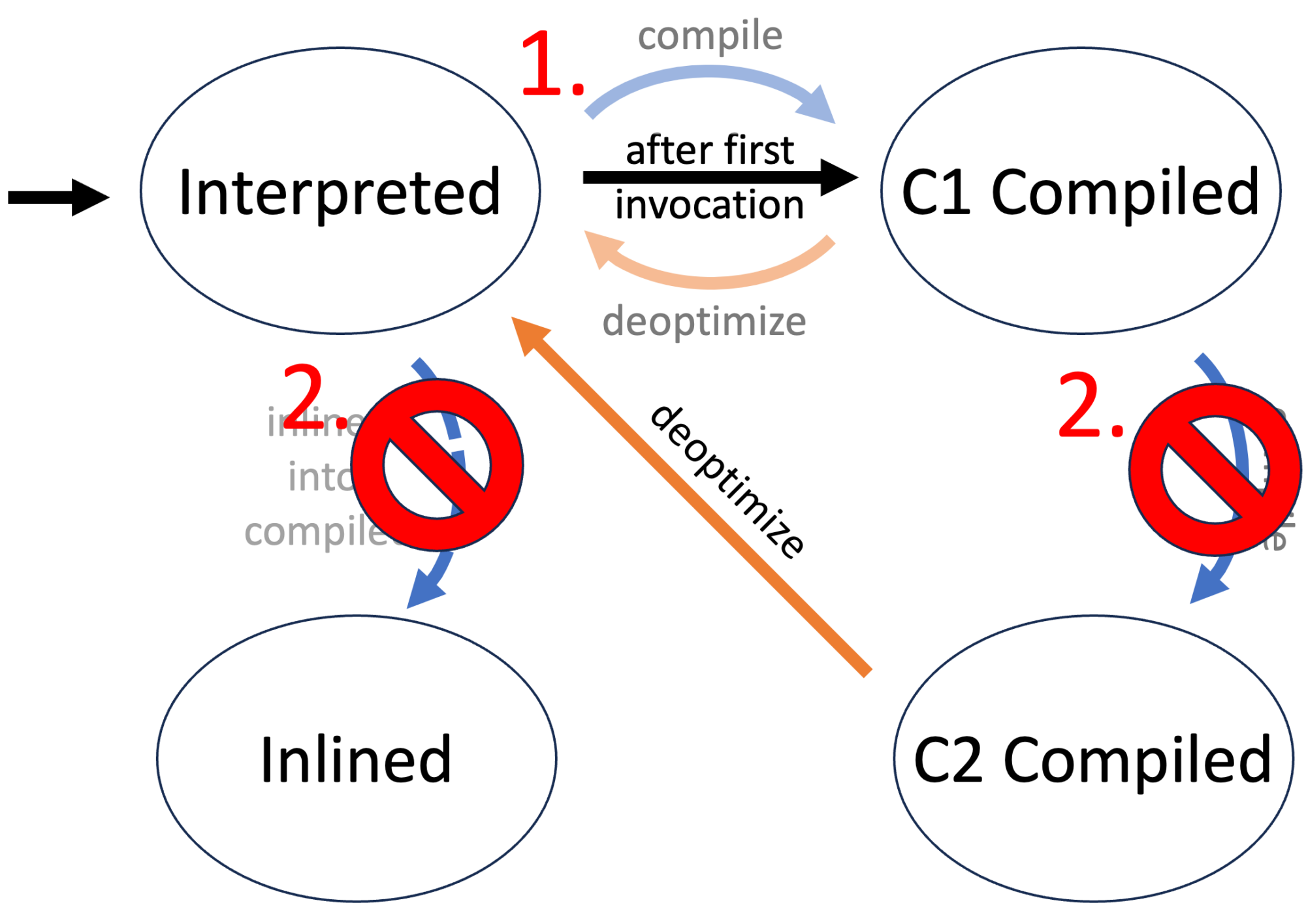
There are four different compilation levels, but I’m subsuming all C1 variants under the C1 label because some of my used techniques only work on the C1/C2/inlined level. You can read more on tiered compilation in articles like Tiered Compilation in JVM on Baeldung.
Now that I finished the obligatory disclaimer: What are the stages in the life of a method with a tiered JIT?
The first time the JVM executes a method, the method’s byte code is interpreted without compilation. This allows the JVM to gather information on the method, as C1 and C2 are profile guided.
The method is then compiled when the JVM deems this to be beneficial, usually after the method has been executed a few times. The next call of the method will then use the compiled version. The method is initially compiled with different levels of the C1 compiler before finally being C2 compiled, which takes the longest but produces the best native instructions.
The JVM might decide at any point to use the interpreted version of a method by deoptimizing it. The compiled versions are kept, depending on the compiler and the reasons for the deoptimization.
Every compiler can decide to inline called methods of a currently compiled method. A compiler uses the initial byte code for this purpose.
What we want and what we get
The ideal would be to tell the JVM to just use a method in its compiled version, e.g.:
But this is not possible, as the JVM does not have any information it needs for compilation before the first execution of a method. We, therefore, have first to execute the method (or the benchmark) and then set the compilation level:
How do we get it?
We can split the task of forcing a method to be compiled (or inlined, for that matter) into two parts:
Force all methods into their respective state (→ WhiteBox API) after the initial execution.
Force the JIT to never compile a method with a different compiler (→ Compiler Control)
The following is the modified state diagram when forcing a method to be C1 compiled:
In the following, I’ll discuss how to use both the WhiteBox API and Compiler Control to facilitate the wanted behavior.
WhiteBox API
Many JVM tests are written in the JTreg framework, allowing developers to write these tests in Java. But these tests often require specific functionality not regularly available to Java developers. This functionality is exported in the WhiteBox API:
One of the not so well-known tools of the HotSpot VM is its WhiteBox testing API. Introduced in Java 7 it has been significantly improved and extended in Java 8 and 9. It can be used to query or change HotSpot internals which are not otherwise exposed to Java-land. While its features make it an indispensable tool for writing good HotSpot regression tests, it can also be used for experiments or for the mere fun of peeking into the VM. This entry will focus on the usage of the WhiteBox API in Java 8 and 9.
The WhiteBox API is implemented as a Java class (called sun.hotspot.WhiteBox) which defines various entry points into the HotSpot VM. Most of the functionality is implemented natively, directly in the HotSpot VM. The API is implemented as a singleton which can be easily retrieved by calling the static method WhiteBox.getWhiteBox().
Unfortunately, currently even a simple JavaDoc documentation of the API doesn’t exist, so in order to make full use of its functionality, you’ll have to peek right into WhiteBox.java.
This API can be used outside of JTreg tests after enabling it by passing -Xbootclasspath/a:wb.jar -XX:+UnlockDiagnosticVMOptions -XX:+WhiteBoxAPI as JVM arguments. To use it, you have to build the WhiteBox JAR from scratch for your specific JVM by calling make build-test-lib (after you set up the build via the configure script).
But please be aware that using this API outside of JVM tests is relatively rare, and the documentation is still non-existent, so using it entails reading a lot of JDK sources and experimentation.
The build target did not work in JDK 21, and when I fixed it, the first question in the PR was by Daniel Jelinski, who asked:
That’s interesting. How did you find this? Is the result of this target used anywhere? As far as I could tell, the build-test-lib target itself is not used anywhere. The classes that fail to compile here are used by tests without any problems – each test specifies the necessary imports individually. Should we remove this make target instead?
So it would be best if you certainly did not depend on it.
The WhiteBox API consists of the singleton class jdk.test.whitebox.WhiteBox which offers many methods: From GC related methods like boolean isObjectInOldGen(Object o) and void fullGC() to NMT-related methods like long NMTMalloc(long size) and JIT-related methods like void deoptimizeAll().
You can even use it to force the compilation of a method and to set JVM flags, as shown in this example by Jean-Philippe Bempel:
This is from his blog post WhiteBox API, the only blog post I could find on this topic.
Back to our goal of forcing the compilation of a method. It is a good idea to reset the state of a method and deoptimize it to start from a blank slate:
// obtain a method reference
Executable m = X.class.getDeclaredMethod("m", null);
// obtain a WhiteBox instance
WhiteBox wb = WhiteBox.getWhiteBox();
// deooptimize the method
wb.deoptimizeMethod(m);
// clear its state, found by experimentation to be neccessary
wb.clearMethodState(m);
We can then either leave the method uncompiled (for compilation level 0) or enqueue for compilation:
I implemented this in the WhiteBoxUtil class in my trace-tester library. This allows us to force all methods in their respective states. But the JVM can still decide to optimize further or inline a method, even when specifying the contrary. So we have to force the JVM using the second the Compiler Control specifications.
Compiler Control
This control mechanism has been introduced in Java 9 with JEP 165 by Nils Eliasson:
Summary
This JEP proposes an improved way to control the JVM compilers. It enables runtime manageable, method dependent compiler flags. (Immutable for the duration of a compilation.)
Goals
Fine-grained and method-context dependent control of the JVM compilers (C1 and C2)
The ability to change the JVM compiler control options in run time
No performance degradation
Motivation
Method-context dependent control of the compilation process is a powerful tool for writing small contained JVM compiler tests that can be run without restarting the entire JVM. It is also very useful for creating workarounds for bugs in the JVM compilers. A good encapsulation of the compiler options is also good hygiene.
This mechanism is properly standardized for the OpenJDK, unlike the WhiteBox APi. The compiler control allows to specify compilation settings by defining them in a JSON file and applying them:
Using jcmd (see JEP): jcmd <pid> Compiler.add_directives <file>
Passing it via JVM arguments: -XX:+UnlockDiagnosticVMOptions -XX:CompilerDirectivesFile=<file>
Using the WhiteBox API: int addCompilerDirective(String compDirect)
The following directives specify as an example that the method m should not be C2 compiled and not be inlined:
[
{
// can also contain patterns
"match": ["X::m()"],
// "-" prefixes not inlined, "+" inlined methods
"inline": ["-X::m()"],
"C1": {},
"C2": {
"Exclude": true
}
}
// multiple directives supported
// first directives have priority
]
This, in theory, allows the method to be deoptimized, but this did not happen during my testing. With forced compilation, one can assume that this method will almost be used in its compiled form.
I recommend this Compiler Control guide for a more in-depth guide with all options. An implementation of the control file generation with a fluent API can be found in the trace-tester project in the CompilerDirectives class. Feel free to adapt this for your own projects.
Conclusion
I’ve shown you in this article how to control the JIT to specify the inlining and compilation of methods using two lesser-known JVM APIs. This allows us to write reproducible profiling APIs and makes it easier to check how a profiling API reacts to different scenarios.
If you have any suggestions, feel free to reach out. I look forward to preparing slides for my upcoming talks in Milan, Munich, Arnhem, and Karlsruhe. Feel free to come to my talks; more information soon on Twitter.
This project is part of my work in the SapMachine team at SAP, making profiling easier for everyone.
Using async-profiler and jattach can be quite a hassle. First, you have to download the proper archive from GitHub for your OS and architecture; then, you have to unpack it and place it somewhere. It gets worse if you want to embed it into your library, agent, or application: Library developers cannot just use maven dependency but have to create wrapper code and build scripts that deal with packaging the binaries themselves, or worse, they depend on a preinstalled version which they do not control.
In November 2022, I started the ap-loader project to remedy this situation: I wrapped async-profiler and jattach in a platform-independent JAR which can be pulled from maven central. I already wrote a blog post on its essential features: AP-Loader: A new way to use and embed async-profiler.
In this blog post, I’m focusing on its programmatic usage: Async-profiler can be used in a library to gather profiling data of the current or a different process, but the profiler distribution contains more: It contains converters to convert from JFR to flamegraphs, and jattach to attach a native agent dynamically to (potentially the current) JVM and send commands to it.
This blog post does assume that you’re familiar with the basic usage of async-profiler. If you are not, consider reading the async-profiler README or the Async-profiler – manual by use cases by Krzysztof Ślusarski.
The ap-loader library allows you to depend on a specific version of async-profiler using gradle or maven:
There are multiple maven artifacts: ap-loader-all which contains the native libraries for all platforms for which async-profiler has pre-built libraries and artifacts that only support a single platform like ap-loader-macos. I recommend using the ap-loader-all if you don’t know what you’re doing, the current release is still tiny, with 825KB.
The version number consists of the async-profiler version and the version (here 2.9) of the ap-loader support libraries (here 5). I’m typically only publishing the newest ap-loader version for the latest async-profiler. The changes in ap-loader are relatively minimal, and I keep the API stable between versions.
The ap-loader library consists of multiple parts:
AsyncProfilerLoader class: Wraps async-profiler and jattach, adding a few helper methods
converter package: Contains all classes from the async-profiler converter JAR and helps to convert between multiple formats
AsyncProfiler class: API for async-profiler itself, wrapping the native library.
All but the AsyncProfilerLoader class is just copied from the underlying async-profiler release. ap-loader contains all Java classes from async-profiler, but I omit the helper classes here for brevity.
AsyncProfilerLoader
This is the main entry point to ap-loader; it lives in the one.profiler package like the AsyncProfiler class. Probably the most essential method is load:
Load
The load method loads the included async-profiler library for the current platform:
It returns the instantiated API wrapper class. The method throws an IllegalStateException if the present ap-loader dependencies do not support the platform and an IOException if loading the library resulted in other problems.
Newer versions of the AsyncProfiler API contain the AsyncProfiler#getInstance() method, which can also load an included library. The main difference is that you have to include the native library for all the different platforms, replicating all the work of the ap-loader build system every time you update async-profiler.
Dealing with multiple platforms is hard, and throwing an exception when not supporting a platform might be inconvenient for your use case. AsyncProfilerLoader has the loadOrNull method which returns null instead and also the isSupported to check whether the current combination of OS and CPU is supported. A typical use case could be:
if (AsyncProfilerLoader.isSupported()) {
AsyncProfilerLoader.load().start(...);
} else {
// use JFR or other fall-backs
}
This might still throw IOExceptions, but they should never happen in normal circumstances and are probably by problems that should be investigated, being either an error in ap-loader or in your application.
If you want to merely get the path to the extracted libAsyncProfiler, then use the getAsyncProfilerPath method which throws the same exceptions as the load method. A similar method exists for jattach (getJattachPath).
Execute Profiler
The async-profiler project contains the profiler.sh script (will be replaced by asprof starting with async-profiler 2.10):
To run the agent and pass commands to it, the helper script profiler.sh is provided. A typical workflow would be to launch your Java application, attach the agent and start profiling, exercise your performance scenario, and then stop profiling. The agent’s output, including the profiling results, will be displayed in the Java application’s standard output.
This helper script is also included in ap-loader and allows you to use the script on the command-line via java -jar ap-loader profiler ..., the API exposes this functionality via ExecutionResult executeProfiler(String... args).
AsyncProfilerLoader.executeProfiler("-e", "wall", "8983")
// is equivalent to
./profiler.sh -e wall -t -i 5ms -f result.html 8983
The executeProfiler method throws an IllegalStateException if the current platform is not supported. The returned instance of ExecutionResult contains the standard and error output:
public static class ExecutionResult {
private final String stdout;
private final String stderr;
// getter and constructor
...
}
executeProfiler throws an IOException if the profiler execution failed.
Execute Converter
You cannot only use the converter by using the classes from the one.profiler.converter, but you can also execute the converter by calling ExecutionResult executeProfiler(String... args), e.g., the following:
AsyncProfilerLoader.executeConverter(
"jfr2flame", "<input.jfr>", "<output.html>")
// is equivalent to
java -cp converter.jar \
jfr2flame <input.jfr> <output.html>
The executeConverter returns the output of the conversion tool on success and throws an IOException on error, as before.
JAttach
There are multiple ways to use the embedded jattach besides using the binary returned by getJattachPath: ExecutionResult executeJattach(String... args) and boolean jattach(Path agentPath[, String arguments]).
executeJattach works similar to executeProfiler, e.g.:
AsyncProfilerLoader.executeJattach(
"<pid>", "load", "instrument", "false", "javaagent.jar=arguments")
// is equivalent to
jattach <pid> load instrument false "javaagent.jar=arguments"
This runs the same as jattach with the only exception that every string that ends with libasyncProfiler.so is mapped to the extracted async-profiler library for the load command. One can, therefore, for example, start the async-profiler on a different JVM via the following:
But this use case can, of course, be accomplished by using the executeProfiler method, which internally uses jattach.
A great use case for jattach is to attach a custom native agent to the currently running JVM. Starting with JVM 9 doing this via VirtualMachine#attachthrows an IOException if you try this without setting -Djdk.attach.allowAttachSelf=true. The boolean jattach(Path agentPath[, String arguments]) methods simplify this, constructing the command line arguments for you and returning true if jattach succeeded, e.g.:
AsyncProfilerLoader.jattach("libjni.so")
This attaches the libjni.so agent to the current JVM. The process id of this JVM can be obtained by using the getProcessId method.
Extracting a Native Library
I happen to write many small projects for testing profilers that often require loading a native library from the resources folder; an example can be found in the trace_validation (blog post) project:
/**
* extract the native library and return its temporary path
*/
public static synchronized Path getNativeLibPath(
ClassLoader loader) {
if (nativeLibPath == null) {
try {
String filename = System.mapLibraryName(NATIVE_LIB);
InputStream in = loader.getResourceAsStream(filename);
// ...
} catch (IOException e) {
throw new RuntimeException(e);
}
}
return nativeLibPath;
}
I, therefore, added the extractCustomLibraryFromResources method:
/**
* Extracts a custom native library from the resources and
* returns the alternative source if the file is not
* in the resources.
*
* If the file is extracted, then it is copied to
* a new temporary folder which is deleted upon JVM exit.
*
* This method is mainly seen as a helper method
* to obtain custom native agents for #jattach(Path) and
* #jattach(Path, String). It is included in ap-loader
* to make it easier to write applications that need
* custom native libraries.
*
* This method works on all architectures.
*
* @param classLoader the class loader to load
* the resources from
* @param fileName the name of the file to copy,
* maps the library name if the fileName
* does not start with "lib", e.g. "jni"
* will be treated as "libjni.so" on Linux
* and as "libjni.dylib" on macOS
* @param alternativeSource the optional resource directory
* to use if the resource is not found in
* the resources, this is typically the case
* when running the application from an IDE,
* an example would be "src/main/resources"
* or "target/classes" for maven projects
* @return the path of the library
* @throws IOException if the extraction fails and
* the alternative source is not present
* for the current architecture
*/
public static Path extractCustomLibraryFromResources(
ClassLoader classLoader, String fileName,
Path alternativeSource) throws IOException
This can be used effectively together with jattach to attach a native agent from the resources to the current JVM:
// extract the agent first from the resources
Path p = one.profiler.AsyncProfilerLoader.
extractCustomLibraryFromResources(
....getClassLoader(), "library name");
// attach the agent to the current JVM
one.profiler.AsyncProfilerLoader.jattach(p, "optional arguments")
// -> returns true if jattach succeeded
This use-case comes from a profiler test helper library on which I hope to write a blog post in the near future.
Conclusion
ap-loader makes it easy to use async-profiler and its included tools programmatically without creating complex build systems. The project is regularly updated to keep pace with the newest stable async-profiler version; updating a version just requires changing a single dependency in your dependencies list.
The ap-loader is mature, so try it and tell me about it. I’m happy to help with any issues you have with this library, so feel free to write to me or create an issue on GitHub.
This project is part of my work in the SapMachine team at SAP, making profiling easier for everyone.
I’m keenly interested in everything related to profiling on the JVM, especially if it is related to AsyncGetCallTrace, this tiny unofficial API that powers most profilers out there, heck I’m even in the process of adding an improved version to the OpenJDK, AsyncGetStackTrace.
During the discussions on the related JDK enhancement proposal and PRs fixing AsyncGetCallTrace bugs, one thing often arises: Why is AsyncGetCallTrace always called in the signal handler on top of the stack that we want to walk (like in my Writing a Profiler from Scratch series)?
Interaction between the wall-clock sampler thread and the different signal handlers, as currently implemented in async-profiler.
Interaction between the sampler thread and the signal handlers, as currently implemented in JFR.
Update after talks on the JEP: The recommended way to use AsyncGetStackTrace will be to call it in a separate thread.
Advantages
Walking the thread in a sampler thread has multiple advantages: Only a few instructions run in the signal handler: the handler is either just busy waiting for the stack walking to finish, or the thread is stopped entirely. Most of the code runs in the sampler thread, walking one thread after another. This makes the code easier to debug and reason about, and the stack-walking code is less likely to mess up the stack of the sampled thread when something goes terribly wrong. These are part of the reasons why the JFR code silently ignores segmentation faults during stack walking:
One important difference to consider is that in JFR, in contrast to AGCT, there is only a single thread, the ThreadSampler thread, that is wrapped in the CrashProtection. Stack walking is different in JFR compared to AGCT, in that it is done by a different thread, during a point where the target is suspended. Originally, this thread sampler thread was not even part of the VM, although now it is a NonJavaThread. It has been trimmed to not involve malloc(), raii, and other hard-to-recover-from constructs, from the moment it has another thread suspended. Over the years, some transitive malloc() calls has snuck in, but it was eventually found due to rare deadlocking. Thomas brings a good point about crashes needing to be recoverable.
I digress here from the main topic of this article, but I think that the next comment of Markus Grönlund on the PR is interesting because it shows how pressures from the outside can lead to band-aid fixes that are never removed:
For additional context, I should add that the CrashProtection mechanism was mainly put in place as a result of having to deliver JFR from JRockit into Hotspot under a deadline, upholding feature-parity. The stack walking code was in really bad shape back then. Over the years, it has been hardened and improved much, and I have not seen any reported issues about JFR crashes in many years (we log when crashing in production).
An important difference is that AGCT allows more thread states compared to JFR, so there can be issues in that area that are not seen in JFR.
Back to the main topic: It is important to note that even when we walk a thread in a separate thread, we still have to make sure that we only use signal-safe methods while the sampled thread is waiting (thanks to Lukas Werling for pointing this out). The sampled thread might, for example, hold locks for malloc, so our sampled thread cannot use malloc without risking a dead-lock.
Disadvantages
There are, of course, disadvantages: Sampling in a signal handler is more straightforward, as we’re running in the context of the sampled thread and get passed the ucontext (with stack pointer, …) directly. It is more accurate, as we can trigger the sampling of the threads precisely at the time that we want (disregarding thread scheduling), and faster, as we do not busy wait in any thread.
We’re running on the same CPU core, which benefits caching, especially on NUMA CPUs (thanks to Francesco Nigro for pointing this out). Although the performance is rarely an issue with the stack-walking as its runtime is in the tens of microseconds, even if we include the whole signal processing.
Another major disadvantage is related to CPU time and perf-event-related profiling: The commonly used itimer (it has major problems, according to Felix Geisendörfer) and perf APIs send signals to threads in certain intervals. When we walk the stack in a separate thread, the triggered signal handlers must trigger the sampler thread to sample the specific thread.
This can be implemented by pushing the current thread id in a queue, and the sampler thread stops the sampled thread when it’s ready and walks the stack as before or by waiting in the signal handler until the sampler thread has finished walking the stack. The former is less performant because it sends an additional signal, and the latter is only significant if the walk requests of all threads are evenly distributed.
This problem can be lessened when we choose a different way of accessing the perf data: We can read the perf events in a loop and then just use the technique from wall-clock profiling. This is a significant modification of the inner workings of the profiler, and it is not possible with itimer-based profiling.
What is the real reason?
Walking in a separate thread has more advantages than disadvantages, especially when wall-clock profiling or valuing stability over slight performance gains. So why don’t tools like async-profiler implement their sampling this way? It’s because AsyncGetCallTrace currently doesn’t support it. This is the starting point of my small experiment: Could I modify the OpenJDK with just a few changes to add support for out-of-thread walking with AsyncGetCallTrace (subsequently proposing this for AsyncGetStackTrace too)?
Modifying AsyncGetCallTrace
Let us first take a look at the API to refresh our knowledge:
void AsyncGetCallTrace(ASGCT_CallTrace *trace, jint depth,
void* ucontext)
// Arguments:
//
// trace - trace data structure to be filled by the VM.
// depth - depth of the call stack trace.
// ucontext - ucontext_t of the LWP
//
// ASGCT_CallTrace:
// typedef struct {
// JNIEnv *env_id;
// jint num_frames;
// ASGCT_CallFrame *frames;
// } ASGCT_CallTrace;
//
// Fields:
// env_id - ID of thread which executed this trace.
// num_frames - number of frames in the trace.
// (< 0 indicates the frame is not walkable).
// frames - the ASGCT_CallFrames that make up this trace.
// Callee followed by callers.
//
// ASGCT_CallFrame:
// typedef struct {
// jint lineno;
// jmethodID method_id;
// } ASGCT_CallFrame;
So we already pass an identifier of the current thread (env_id) to the API, which should point to the walked thread :
// This is safe now as the thread has not terminated
// and so no VM exit check occurs.
assert(thread ==
JavaThread::thread_from_jni_environment(trace->env_id),
"AsyncGetCallTrace must be called by " +
"the current interrupted thread");
This is the only usage of the passed thread identifier, and why I considered removing it in AsyncGetStackTrace altogether. AsyncGetCallTrace uses the current thread instead:
The assertion above is only enabled in debug builds of the OpenJDK, which are rarely profiled. Therefore, the thread identifier is often ignored and is probably a historic relic. We can use this identifier to obtain the thread that the API user wants to profile and only use the current thread when the thread identifier is null (source):
We can thereby support the new feature without modifying the API itself, only changing the behavior if the thread identifier does not reference the current thread.
The implementation can be found in my OpenJDK fork. This is still a prototype, but it works well enough for testing and benchmarking.
Modifying async-profiler
At the beginning of the article, I already told you how JFR walks the stack in a different thread. We are implementing similar code into async-profiler, restricting us to wall-clock profiling, as its implementation requires fewer modifications.
Before our changes, async-profiler would signal selected threads in a loop via
OS::sendSignalToThread(thread_id, SIGVTALRM)
(source) and records the sample directly in the signal handler (source):
The Profiler::recordSample the method does more than just call AsyncGetCallTrace; it also obtains C/C++ frames. However, this is insignificant for our modifications, as the additional stack walking is only related to the ucontext, not the thread.
We now modify this code so that we still send a signal to the sampled thread but only set a global ucontext and thread identifier (struct Data) in the signal handler, blocking till we finished walking the stack in the sampler thread, walking the stack in the latter (source):
struct Data {
void* ucontext;
JNIEnv* jni;
};
std::atomic<int> _thread_id;
std::atomic<Data*> _thread_data;
bool WallClock::walkStack(int thread_id) {
// set the current thread
_thread_id = thread_id;
_thread_data = nullptr;
// send the signal to the sampled thread
if (!OS::sendSignalToThread(thread_id, SIGVTALRM)) {
_thread_id = -1;
return false;
}
// wait till the signal handler has set the ucontext and jni
if (!waitWhile([&](){ return _thread_data == nullptr;},
10 * 1000 * 1000)) {
_thread_id = -1;
return false;
}
Data *data = _thread_data.load();
// walk the stack
ExecutionEvent event;
event._thread_state = _sample_idle_threads ?
getThreadState(data->ucontext) : THREAD_UNKNOWN;
u64 ret = Profiler::instance()->recordSample(data->ucontext,
_interval, EXECUTION_SAMPLE, &event, data->jni);
// reset the thread_data, triggering the signal handler
_thread_data = nullptr;
return ret != 0;
}
void WallClock::signalHandler(
int signo,
siginfo_t* siginfo,
void* ucontext) {
// check that we are in the thread we are supposed to be
if (OS::threadId() != _thread_id) {
return;
}
Data data{
ucontext,
// Get a JNIEnv if it is deamed to be safe
VMThread::current() == nullptr ? nullptr : VM::jni()
};
Data* expected = nullptr;
if (!_thread_data.compare_exchange_strong(expected, &data)) {
// another signal handler invocation
// is already in progress
return;
}
// wait for the stack to be walked, and block the thread
// from executing
// we do not timeout here, as this leads to difficult bugs
waitWhile([&](){ return _thread_data != nullptr;});
}
The signal handler only stores the ucontext and thread identifier if it is run in the thread currently walked and uses compare_exchange_strong to ensure that the _thread_data is only set once. This prevents stalled signal handlers from concurrently modifying the global variables.
_thread_data.compare_exchange_strong(expected, &data) is equivalent to atomically executing:
This ensures that the _thread_data is only set if it is null. Such operations are the base of many lock-free data structures; you can find more on this topic in the Wikipedia article on Compare-and-Swap (a synonym for compare-and-exchange).
Coming back to the signal handler implementation: The waitWhile method is a helper method that busy waits until the passed predicate does return false or the optional timeout is exhausted, ensuring that the profiler does not hang if something goes wrong.
The implementation uses the _thread_data variable to implement its synchronization protocol:
Interaction between the sampler thread and the signal handler.
You can find the implementation in my async-profiler fork, but as with my OpenJDK fork: It’s only a rough implementation.
The implemented approach works fine with async-profiler, but it has a minor flaw: We depend on an implementation detail of the current iteration of OpenJDK. It is only safe to get the JNIEnv in a signal handler if the JVM has allocated a thread-local Thread object for the signaled thread:
JDK-8132510: it’s not safe to call GetEnv() inside a signal handler since JDK 9, so we do it only for threads already registered in ThreadLocalStorage
For a deeper dive, consider reading the comment of David Holmes to the references JDK issue:
The code underpinning __thread use is not async-signal-safe, which is not really a surprise as pthread_get/setspecific are not designated async-signal-safe either.
The problem, in glibc, is that first access of a TLS variable can trigger allocation [1]. This contrasts with using pthread_getspecific which is benign and so effectively async-signal-safe.
So if a thread is executing in malloc and it takes a signal, and the signal handler tries to use TLS (it shouldn’t but it does and has gotten away with it with pthread_getspecific), then we can crash or get a deadlock.
This implementation detail is not an issue for async-profiler as it might make assumptions. Still, it is undoubtedly a problem for the general approach I want to propose for my new AsyncGetStackTrace API.
Modifying AsyncGetCallTrace (2nd approach)
We want to identify the thread using something different from JNIEnv. The OS thread id seems to be a good fit. It has three significant advantages:
It can be obtained independently from the JVM, depending on the OS rather than the JVM.
Our walkStack method already gets passed the thread id, so we don’t have to pass it from the signal handler to the sampler thread.
The mapping from thread id to Thread happens outside the signal handler in the AsyncGetCallTrace call, and the API sets the env_id field to the appropriate JNIEnv.
We have to add a new parameter os_thread_id to the API to facilitate this change (source):
// ...
// os_thread_id - OS thread id of the thread which executed
// this trace, or -1 if the current thread
// should be used.
// ...
// Fields:
// env_id - ID of thread which executed this trace,
// the API sets this field if it is NULL.
// ...
void AsyncGetCallTrace(ASGCT_CallTrace *trace, jint depth,
void* ucontext, jlong os_thread_id)
The implementation can be found in my OpenJDK fork, but be aware that it is not yet optimized for performance as it iterates over the whole thread list for every call to find the Thread which matches the passed OS thread id.
Modifying async-profiler (2nd approach)
The modification to async-profiler is quite similar to the first approach. The only difference is that we’re not dealing with JNIEnv anymore. This makes the signal handler implementation slightly simpler (source):
void WallClock::signalHandler(
int signo,
siginfo_t* siginfo,
void* ucontext) {
// check that we are in the thread we are supposed to be
if (OS::threadId() != _thread_id) {
return;
}
void* expected = nullptr;
if (!_ucontext.compare_exchange_strong(expected, ucontext)) {
// another signal handler invocation
// is already in progress
return;
}
// wait for the stack to be walked, and block the thread
// from executing
// we do not timeout here, as this leads to difficult bugs
waitWhile([&](){ return _ucontext != nullptr;});
}
Now to the fun part (the experiment): Two drawbacks of the two previously discussed approaches are that one thread waits busily, and the other cannot execute all non-signal-safe code during that period. So the obvious next question is:
Could we walk a thread without stopping it?
In other words: Could we omit the busy waiting? An unnamed person suggested this.
The short answer is: It’s a terrible idea. The sampled thread modifies the stack while we’re walking its stack. It might even terminate while we’re in the middle of its previously valid stack. So this is a terrible idea when you don’t take many precautions.
The only advantage is that we can use non-signal-safe methods during stack walking. The performance of the profiling will not be significantly improved, as the signal sending and handling overhead is a magnitude larger than the stack walking itself for small traces. Performance-wise, it could only make sense for huge (1000 and more frames) traces.
Our central assumption is: The profiler takes some time to transition out of the signal handler of the sampled thread. Possibly longer than it takes to walk the topmost frames, which are most likely to change during the execution, in AsyncGetCallTrace.
But: Timing with signals is hard to predict (see this answer on StackExchange), and if the assumption fails, the resulting trace is either bogus or the stack walking leads to “interesting” segmentation faults. I accidentally tested this when I initially implemented the signal handler in my async-profiler and made an error. I saw error messages in places that I had not seen before.
So the results could be imprecise / sometimes incorrect. But we’re already sampling, so approximations are good enough.
The JVM might crash during the stack walking because the ucontext might be invalid and the thread stack changes (so that the stack pointer in the ucontext points to an invalid value and more), but we should be able to reduce the crashes by using enough precautions in AsyncGetCallTrace and testing it properly (I already implemented tests with random ucontexts in the draft for AsyncGetStackTrace).
The other option is to catch any segmentation faults that occur inside AsyncGetCallTrace. We can do this because we walk the stack in a separate thread (and JFR does it as well, as I’ve written at the beginning of this post). We can implement this by leveraging the ThreadCrashProtection clas,s which has, quite rightfully, some disclaimers:
/*
* Crash protection for the JfrSampler thread. Wrap the callback
* with a sigsetjmp and in case of a SIGSEGV/SIGBUS we siglongjmp
* back.
* To be able to use this - don't take locks, don't rely on
* destructors, don't make OS library calls, don't allocate
* memory, don't print, don't call code that could leave
* the heap / memory in an inconsistent state, or anything
* else where we are not in control if we suddenly jump out.
*/
class ThreadCrashProtection : public StackObj {
public:
// ...
bool call(CrashProtectionCallback& cb);
// ...
};
We wrap the call to the actual AsyncGetCallTrace implementation of our second approach in this handler (source):
This prevents all crashes related to walking the stack from crashing the JVM, which is also helpful for the AsyncGetCallTrace usage of the previous part of this article. The only difference is that crashes in the stack walking are considered a bug in a normal use case but are expected in this use case where we don’t stop the sampled thread.
Back to this peculiar case: The implementation in async-profiler is slightly more complex than just removing the busy waiting at the end. First, we must copy the ucontext in the signal handler because the ucontext pointer only points to a valid ucontext while the thread is stopped. Furthermore, we have to disable the native stack walking in the async-profiler, as it isn’t wrapped in code that catches crashes. We also have, for unknown reasons, to set the safemode option of async-profiler to 0.
The implementation of the signal handler is simple (just remove the wait from the previous version). It results in the following sequence diagram:
Interaction between the sampler thread and the signal handlers when not blocking the sampled thread during the stack walking.
You can find the implementation on GitHub, albeit with known concurrency problems, but these are out-of-scope for this blog post and related to copying the ucontext atomically.
And now to the important question: How often did AsyncGetCallTrace crash? In the renaissance finagle-http benchmark (with a sampling interval of 10ms), it crashed in 592 of around 808000 calls, a crash rate of 0.07% and far better than expected.
The main problem can be seen when we look at the flame graphs (set the environment variable SKIP_WAIT to enable the modification):
Which looks not too dissimilar to the flame graph with busy waiting:
Many traces (the left part of the graph) are broken and do not appear in the second flame graph. Many of these traces seem to be aborted:
But this was an interesting experiment, and the implementation seems to be possible, albeit creating a safe and accurate profiler would be hard and probably not worthwhile: Catching the segmentation faults seems to be quite expensive: The runtime for the renaissance finagle-http benchmark is 83 seconds for the version with busy waiting and 84 seconds without, despite producing worse results.
Evaluation
We can now compare the performance of the original with the two prototypical implementations and the experimental implementation in a preliminary evaluation. I like using the benchmarks of the renaissance suite (version 0.14.2). For this example, I used the primarily single core, dotty benchmark with an interval of 1ms and 10ms:
The shorter interval will make the performance impact of changes to the profiling more impactful. I’m profiling with my Threadripper 3995WX on Ubuntu using hyperfine (one warm-up run and ten measured runs each). The standard deviation is less than 0.4% in the following diagram, which shows the wall-clock time:
The number of obtained samples is roughly the same overall profiler runs, except for the experimental implementation, which produces around 12% fewer samples. All approaches seem to have a comparable overhead when considering wall-clock time. It’s different considering the user-time:
This shows that there is a significant user-time performance penalty when not using the original approach. This is expected, as we’re engaging two threads into one during the sampling of a specific threadTherefore, the wall-clock timings might.
The wall-clock timings might therefore be affected by my CPU having enough cores so that the sampler and all other threads run fully concurrently.
I tried to evaluate all approaches with a benchmark that utilizes all CPU (finagle-http), but my two new approaches have apparently severe shortcomings, as they produced only around a quarter of the samples compared to the original async-profiler and OpenJDK combination. This is worth fixing, but out-of-scope for this blog post, which already took more than a week to write.
Conclusion
This was the serious part of the experiment: Using AsyncGetCallTrace in a separate thread is possible with minor modifications and offers many advantages (as discussed before). It especially provides a more secure approach to profiling while not affecting performance if you’re system is not yet saturated: A typical trade-off between security and performance. I think that it should be up to the experienced performance engineer two decide and profilers should offer both when my JEP eventually makes the out-of-thread walking available on stock OpenJDKs.
The implementations in both the OpenJDK and async-profiler also show how to quickly implement, test and evaluate different approaches with widely used benchmarks.
Conclusion
The initial question, “Couldn’t we just use AsyncGetCallTrace in a separate thread?” can be answered with a resounding “Yes!”. Sampling in separate threads has advantages, but we have to block the sampled thread during stack walking; omitting this leads to broken traces.
If you have anything to add or found a flaw in my approaches or my implementations, or any other suggestions, please let me know 🙂
I hope this article gave you a glimpse into my current work and the future of low-level Java profiling APis.
This blog post is part of my work in the SapMachine team at SAP, making profiling easier for everyone.
This blog post is about writing a Java agent and instrumentation code to find unused classes and dependencies in your project. Knowing which classes and dependencies are not used in your application can save you from considering the bugs and problems in these dependencies and classes if you remove them.
There a multiple tools out there, for gradle and maven (thanks, Marit), that do this statically or dynamically (like the one described in the paper Coverage-Based Debloating for Java Bytecode, thanks, Wolfram). Statical tools are based on static program analysis and are usually safer, as they only remove classes that can statically be proven never to be used. But these tools generally struggle with reflection and code generation which frameworks like Spring use heavily. Dynamic tools typically instrument the bytecode of the Java application and run it to see which parts of the application are used in practice. These tools can deal with recursion and are more precise, removing larger portions of the code.
The currently available tools maybe suffice for your use case, but they are complex software, hard to reason about, and hard to understand. Therefore, this post aims to write a prototypical dynamic tool to detect unused classes. This is like the profiler of my Writing a Profiler in 240 Lines of Pure Java blog post, done mainly for educational purposes, albeit the tool might be helpful in certain real-world use cases. As always, you can find the final MIT-licensed code on GitHub in my dead-code-agent repository.
Main Idea
I make one simplification compared to many of the more academic tools: I only deal with code with class-level granularity. This makes it far more straightforward, as it suffices to automatically instrument the static initializers of every class (and interface), turning
class A {
private int field;
public void method() {...}
}
into
class A {
static {
Store.getInstance().processClassUsage("A");
}
private int field;
public void method() {...}
}
to record the first usage of the class A in a global store. Another advantage is that there is minimal overhead when recording the class usage information, as only the first usage of every class has the recording overhead.
Static initializers are called whenever a class is initialized, which happens in the following circumstances:
A class or interface T will be initialized immediately before the first occurrence of any one of the following:
T is a class and an instance of T is created.
A static method declared by T is invoked.
A static field declared by T is assigned.
A static field declared by T is used and the field is not a constant variable (§4.12.4).
When a class is initialized, its superclasses are initialized (if they have not been previously initialized), as well as any superinterfaces (§8.1.5) that declare any default methods (§9.4.3) (if they have not been previously initialized). Initialization of an interface does not, of itself, cause initialization of any of its superinterfaces.
Adding code at the beginning of every class’s static initializers lets us obtain knowledge on all used classes and interfaces. Interfaces don’t have static initializers in Java source code, but the bytecode supports this nonetheless, and we’re only working with bytecode here.
We can then use this information to either remove all classes that are not used from the application’s JAR or log an error message whenever such a class is instantiated:
class UnusedClass {
static {
System.err.println("Class UnusedClass is used " +
"which is not allowed");
}
private int field;
public void method() {...}
}
This has the advantage that we still log when our assumption on class usage is broken, but the program doesn’t crash, making it more suitable in production settings.
Structure
The tool consists of two main parts:
Instrumenter: Instruments the JAR and removes classes, used both for modifying the JAR to obtain the used classes and to remove unused classes or add error messages (as shown above)
Instrumenting Agent: This agent is similar to the Instrumenter but is implemented as an instrumenting Java agent. Both instrumentation methods have advantages and disadvantages, which I will explain later.
This leads us to the following workflow:
Workflow of the dead-code analyzer
Usage
Before I dive into the actual code, I’ll present you with how to use the tool. Skip this section if you’re only here to see how to implement an instrumenting agent 🙂
You first have to download and build the tool:
git clone https://github.com/parttimenerd/dead-code-agent
cd dead-code-agent
mvn package
# and as demo application the spring petclinic
git clone https://github.com/spring-projects/spring-petclinic
cd spring-petclinic
mvn package
# make the following examples more concise
cp spring-petclinic/target/spring-petclinic-3.0.0-SNAPSHOT.jar \
petclinic.jar
The tool is written in Java 17 (you should be using this version anyways), which is the only system requirement.
Using the Instrumenting Agent to Obtain the Used Classes
The instrumenting agent can be started at JVM startup:
This will record all loaded and used classes in the classes.txt file, which includes lines like:
u ch.qos.logback.classic.encoder.PatternLayoutEncoder
l ch.qos.logback.classic.joran.JoranConfigurator
u ch.qos.logback.classic.jul.JULHelper
u ch.qos.logback.classic.jul.LevelChangePropagator
Telling you that the PatternLayoutEncoder class has been used and has only been loaded but not used. Loaded means, in our context, that the instrumenting agent instrumented this class.
Not all classes can be instrumented. It is impossible to, for example, add static initializers to the class that we loaded before the instrumentation agent started; this is not a problem, as we can start the agent just after all JDK classes have been loaded. Removing JDK classes is possible with jlink, but instrumenting these classes is out-of-scope for this article, as they are far harder to instrument and most people don’t consider these classes.
The instrumentation agent is not called for some Spring Boot classes for reasons unknown to me. This makes the agent approach unsuitable for Spring Boot applications and led me to the development of the main instrumenter:
Using the Instrumenter to Obtain the Used Classes
The instrumenter lets you create an instrumented JAR that records all used classes:
This will throw a few errors, but remember; it’s still a prototype.
You can then run the resulting JAR to obtain the list of used classes (like above). Just use the instrumented.jar like your application JAR:
java -jar instrumented.jar
The resulting classes.txt is similar to the file produced by the instrumenting agent. The two differences are that we cannot observe only loaded but not used classes and don’t miss any Spring-related classes. Hopefully, I will find time to investigate the issue related to Spring’s classloaders.
Using the Instrumenter to Log Usages of Unused Classes
The list of used classes can be used to log the usage of classes not used in the recording runs:
This will log the usage of all classes not marked as used in classes.txt on standard error, or exit the program if you pass the --exit option to the instrumenter.
If you, for example, recorded the used classes of a run where you did not access the petclinic on localhost:8080, then executing the modified logging.jar and accessing the petclinic results in output like:
Class org.apache.tomcat.util.net.SocketBufferHandler is used which is not allowed
Class org.apache.tomcat.util.net.SocketBufferHandler$1 is used which is not allowed
Class org.apache.tomcat.util.net.NioChannel is used which is not allowed
Class org.apache.tomcat.util.net.NioChannel$1 is used which is not allowed
...
An exciting feature of the instrumenter is that the file format of the used classes file is not restricted to what the instrumented JARs produce. It also supports wild cards:
u org.apache.tomcat.*
Tells the instrumenter that all classes which have a fully-qualified name starting with org.apache.tomcat. should be considered used.
r org.apache.* used apache
This tells the instrumenter to instrument the JAR to report all usages of Apache classes, adding the (optional) message “used apache.”
These two additions make the tool quite versatile.
Writing the Instrumentation Agent
We start with the instrumentation agent and later go into the details of the Instrumenter.
The agent itself consists of three major parts:
Main class: Entry point for the agent, registers the ClassTransformer as a transformer
ClassTransformer class: Instruments all classes as described before
Store class: Deals with handling and storing the information on used and stored classes
A challenge here is that all instrumented classes will use the Store. We, therefore, have to put the store onto the bootstrap classpath, making it visible to all classes. There are multiple ways to do this:
It is building a runtime JAR directly in the agent using the JarFile API, including the bytecode of the Store and its inner classes.
Building an additional dead-code-runtime.jar using a second maven configuration, including this JAR as a resource in our agent JAR, and copying it into a temporary file in the agent.
Both approaches are valid, but the second approach seems more widely used, and the build system includes all required classes and warns of missing ones.
We build the runtime JAR by creating a new maven configuration that only includes the me.bechberger.runtime package where the Store resides:
The main class consists mainly of the premain method which deletes the used classes file, loads the runtime JAR, and registers the ClassTransformer:
public class Main {
public static void premain(String agentArgs,
Instrumentation inst) {
AgentOptions options = new AgentOptions(agentArgs);
// clear the file
options.getOutput().ifPresent(out -> {
try {
Files.deleteIfExists(out);
Files.createFile(out);
} catch (IOException e) {
throw new RuntimeException(e);
}
});
try {
inst.appendToBootstrapClassLoaderSearch(
new JarFile(getExtractedJARPath().toFile()));
} catch (IOException e) {
throw new RuntimeException(e);
}
inst.addTransformer(new ClassTransformer(options), true);
}
// ...
}
I’m omitting the AgentOptions class, which parses the options passed to the agent (like the output file).
The premain method uses the getExtractedJARPath method to extract the runtime JAR. This extracts the JAR from the resources:
private static Path getExtractedJARPath() throws IOException {
try (InputStream in = Main.class.getClassLoader()
.getResourceAsStream("dead-code-runtime.jar")){
if (in == null) {
throw new RuntimeException("Could not find " +
"dead-code-runtime.jar");
}
File file = File.createTempFile("runtime", ".jar");
file.deleteOnExit();
Files.copy(in, file.toPath(),
StandardCopyOption.REPLACE_EXISTING);
return file.toPath().toAbsolutePath();
}
}
ClassTransformer Class
This transformer implements the ClassFileTransformer to transform all loaded classes.
A transformer of class files. An agent registers an implementation of this interface using the addTransformer method so that the transformer’s transform method is invoked when classes are loaded, redefined, or retransformed. The implementation should override one of the transform methods defined here. Transformers are invoked before the class is defined by the Java virtual machine.
We could do all the bytecode modification ourselves. This is error-prone and complex, so we use the Javassist library, which provides a neat API to insert code into various class parts.
Our ClassTransformer has to implement the transform method:
Transforms the given class file and returns a new replacement class file.
Parameters:
module – the module of the class to be transformed
loader – the defining loader of the class to be transformed, may be null if the bootstrap loader
className – the name of the class in the internal form of fully qualified class and interface names as defined in The Java Virtual Machine Specification. For example, "java/util/List".
classBeingRedefined – if this is triggered by a redefine or retransform, the class being redefined or retransformed; if this is a class load, null
protectionDomain – the protection domain of the class being defined or redefined
classfileBuffer – the input byte buffer in class file format – must not be modified
This prevents instrumentation problems and keeps the list of used classes clean. We then use a statically defined ScopedClassPoolFactory to create a class pool for the given class loader, parse the bytecode using javassist and transform it using our transform(String className, CtClass cc) method:
try {
ClassPool cp = scopedClassPoolFactory
.create(loader, ClassPool.getDefault(),
ScopedClassPoolRepositoryImpl
.getInstance());
CtClass cc = cp.makeClass(
new ByteArrayInputStream(classfileBuffer));
if (cc.isFrozen()) {
// frozen classes cannot be modified
return classfileBuffer;
}
// classBeingRedefined is null in our case
transform(className, cc);
return cc.toBytecode();
} catch (CannotCompileException | IOException |
RuntimeException | NotFoundException e) {
e.printStackTrace();
return classfileBuffer;
}
The actual instrumentation is now done with the javassist API:
private void transform(String className, CtClass cc)
throws CannotCompileException, NotFoundException {
// replace "/" with "." in the className
String cn = formatClassName(className);
// handle the class load
Store.getInstance().processClassLoad(cn,
cc.getClassFile().getInterfaces());
// insert the call to processClassUsage at the beginning
// of the static initializer
cc.makeClassInitializer().insertBefore(
String.format("me.bechberger.runtime.Store" +
".getInstance().processClassUsage(\"%s\");",
cn));
}
You might wonder why we’re also recording the interfaces of every class. This is because the static initializers of interfaces are not called when the first static initializer of an implemented class is called. We, therefore, have to walk the interface tree ourselves. Static initializers of parent classes are called; therefore, we don’t have to handle parent classes ourselves.
Instrumenter
The main difference is that the instrumenter also transforms the bytecode, transforming all files in the JAR and writing a new JAR back. This new JAR is then executed, which has the advantage that we can instrument all classes in the JAR (even with Spring’s classloader magic). The central part of the Instrumenter is the ClassAndLibraryTransformer which can be targeted to a specific class transformation use case by setting its different fields:
public class ClassAndLibraryTransformer {
/** Source JAR */
private final Path sourceFile;
/**
* Include a library in the output JAR.
* A library is JAR inside this JAR and
* its name is the file name without version identifier
* and suffix.
*/
private Predicate<String> isLibraryIncluded;
/** Include a class in the output JAR */
private Predicate<String> isClassIncluded;
/**
* Transforms the class file, might be null.
* Implemented using the javassist library as shown before.
*/
private BiConsumer<ClassPool, CtClass> classTransformer;
record JarEntryPair(String name, InputStream data) {
static JarEntryPair of(Class<?> klass, String path)
throws IOException {
// obtain the bytecode from the dead-code JAR
return new JarEntryPair(path,
klass.getClassLoader().getResourceAsStream(path));
}
}
/**
* Supplies a list of class files that should
* be added to the JAR, like the Store related classes
*/
private Supplier<List<JarEntryPair>> miscFilesSupplier =
List::of;
/** Output JAR */
private final OutputStream target;
// ...
}
This class is used for instrumentation and removing classes and nested JARs/libraries, sharing most of the code between both.
The central entry point of this class is the process method, which iterates over all entries of the sourceFile JAR using the JarFile and JarOutputStream APIs:
void process(boolean outer) throws IOException {
try (JarOutputStream jarOutputStream =
new JarOutputStream(target);
JarFile jarFile = new JarFile(sourceFile.toFile())) {
jarFile.stream().forEach(jarEntry -> {
try {
String name = jarEntry.getName();
if (name.endsWith(".class")) {
processClassEntry(jarOutputStream,
jarFile, jarEntry);
} else if (name.endsWith(".jar")) {
processJAREntry(jarOutputStream,
jarFile, jarEntry);
} else {
processMiscEntry(jarOutputStream,
jarFile, jarEntry);
}
} catch (IOException e) {
// .forEach forces us to wrap exceptions
throw new RuntimeException(e);
}
});
if (outer) { // add miscellaneous class files
for (JarEntryPair miscFile :
miscFilesSupplier.get()) {
// create a new entry
JarEntry jarEntry =
new JarEntry(miscFile.name);
jarOutputStream.putNextEntry(jarEntry);
// add the file contents
miscFile.data.transferTo(jarOutputStream);
}
}
}
}
Processing entries of the JAR file that are neither class files nor JARs consist only of copying the entry directly to the new file:
Such files are typically resources like XML configuration files.
Transforming class file entries is slightly more involved: We check whether we should include the class defined in the class file and transform it if necessary:
private void processClassEntry(
JarOutputStream jarOutputStream,
JarFile jarFile, JarEntry jarEntry) throws IOException {
String className = classNameForJarEntry(jarEntry);
if (isClassIncluded.test(className) ||
isIgnoredClassName(className)) {
jarOutputStream.putNextEntry(jarEntry);
InputStream classStream =
jarFile.getInputStream(jarEntry);
if (classTransformer != null &&
!isIgnoredClassName(className)) {
// transform if possible and required
classStream = transform(classStream);
}
classStream.transferTo(jarOutputStream);
} else {
System.out.println("Skipping class " + className);
}
}
We ignore here class files related to package-info or module-info, as they don’t contain valid classes. This is encapsulated in the isIgnoredClassName method. The implementation of the transform method is similar to the transform method of the instrumenting agent, using the classTransformer consumer for the actual class modification.
A transforming consumer to log the usage of every unused class looks as follows, assuming that isClassUsed it is a predicate that returns true if the passed class is used and that messageSupplier supplies specific messages that are output additionally:
(ClassPool cp, CtClass cc) -> {
String className = cc.getName();
if (isClassUsed.test(className)) {
return;
}
try {
String message = messageSupplier.apply(className);
cc.makeClassInitializer().insertBefore(
String.format("System.err.println(\"Class %s " +
"is used which is not allowed%s\");" +
"if (%s) { System.exit(1); }",
className,
message.isBlank() ? "" : (": " + message),
exit));
} catch (CannotCompileException e) {
throw new RuntimeException(e);
}
};
The last thing that I want to cover is the handling of nested JARs in the processJAREntry(JarOutputStream jarOutputStream, JarFile jarFile, JarEntry jarEntry) method. Nested JARs are pretty standard with Spring and bundle libraries with your application. To quote the Spring documentation:
Java does not provide any standard way to load nested jar files (that is, jar files that are themselves contained within a jar). This can be problematic if you need to distribute a self-contained application that can be run from the command line without unpacking.
To solve this problem, many developers use “shaded” jars. A shaded jar packages all classes, from all jars, into a single “uber jar”. The problem with shaded jars is that it becomes hard to see which libraries are actually in your application. It can also be problematic if the same filename is used (but with different content) in multiple jars. Spring Boot takes a different approach and lets you actually nest jars directly.
Our method first checks that we should include the nested JAR and, if so, extract it into a temporary file. We extract the JAR because the JarFile API can only work with files. We then use the ClassAndLibraryTransformer recursively:
private void processJAREntry(JarOutputStream jarOutputStream,
JarFile jarFile, JarEntry jarEntry) throws IOException {
String name = jarEntry.getName();
String libraryName = Util.libraryNameForPath(name);
if (!isLibraryIncluded.test(libraryName)) {
System.out.println("Skipping library " + libraryName);
return;
}
Path tempFile = Files.createTempFile("nested-jar", ".jar");
tempFile.toFile().deleteOnExit();
// copy entry over
InputStream in = jarFile.getInputStream(jarEntry);
Files.copy(in, tempFile,
StandardCopyOption.REPLACE_EXISTING);
ClassAndLibraryTransformer nestedJarProcessor;
// create new JAR file
Path newJarFile = Files.createTempFile("new-jar",
".jar");
newJarFile.toFile().deleteOnExit();
try (OutputStream newOutputStream =
Files.newOutputStream(newJarFile)) {
nestedJarProcessor =
new ClassAndLibraryTransformer(tempFile,
isLibraryIncluded, isClassIncluded,
classTransformer,
newOutputStream);
nestedJarProcessor.process(false);
}
// create an uncompressed entry
JarEntry newJarEntry = new JarEntry(jarEntry.getName());
newJarEntry.setMethod(JarEntry.STORED);
newJarEntry.setCompressedSize(Files.size(newJarFile));
CRC32 crc32 = new CRC32();
crc32.update(Files.readAllBytes(newJarFile));
newJarEntry.setCrc(crc32.getValue());
jarOutputStream.putNextEntry(newJarEntry);
Files.copy(newJarFile, jarOutputStream);
}
Nesting JAR files come with a few restrictions, but most notable is the limitation of ZIP compression:
The ZipEntry for a nested jar must be saved by using the ZipEntry.STORED method. This is required so that we can seek directly to individual content within the nested jar. The content of the nested jar file itself can still be compressed, as can any other entries in the outer jar.
Therefore, the code creates a JarEntry that is just stored and not compressed. But this requires us to compute and set the CRC and file size ourselves; this is done automatically for compressed entries.
All other code can be found in the GitHub repository of the project. Feel free to adapt the code and use it in your own projects.
Conclusion
Dynamic dead-code analyses are great for finding unused code and classes, helping to reduce the attack surface. Implementing such tools in a few lines of Java code is possible, creating an understandable tool that offers less potential of surprise for users. The tool developed in this blog post is a prototype of a dead-code analysis that could be run in production to find all used classes in a real-world setting.
Writing instrumentation agents using the JDK instrumentation APIs combined with the javassist library allows us to write a somewhat functioning agent in hours.
I hope this blog post helped you to understand the basics of finding unused classes dynamically and implementing your own instrumentation agent.
Thanks to Wolfram Fischer from SAP Security Research Germanyfor nerd-sniping me, leading me to write the tool and this blog post. This blog post is part of my work in the SapMachine team at SAP, making profiling easier for everyone.
A few months back, I started writing a profiler from scratch, and the code since became the base of my profiler validation tools. The only problem with this project: I wanted to write a proper non-safepoint-biased profiler from scratch. This is a noble effort, but it requires lots C/C++/Unix programming which is finicky, and not everyone can read C/C++ code.
For people unfamiliar with safepoint bias: A safepoint is a point in time where the JVM has a known defined state, and all threads have stopped. The JVM itself needs safepoints to do major garbage collections, Class definitions, method deoptimizations, and more. Threads are regularly checking whether they should get into a safepoint, for example, at method entry, exit, or loop backjumps. A profiler that only profiles at a safepoint have an inherent bias because it only includes frames from the locations inside methods where Threads check for a safepoint. The only advantage is that the stack-walking at safepoints is slightly less error-prone, as there are fewer mutations of heap and stack.For more information, consider reading the excellent article Java Safepoint and Async Profiling by Seetha Wenner, the more technical one by JP Bempel, or the classic article Safepoints: Meaning, Side Effects and Overheads by Nitsan Wakart. To conclude: Safepoint-biased profilers don’t give you a holistic view of your application, but can still be helpful to analyze major performance issues where you look at the bigger picture.
People on the hackernews thread on this blog post pointed out that the code has potentially some concurrency and publication issues. I’ll fixed the code in the GitHub repository, but kept the old code here. The modifications are minor.
This blog post aims to develop a tiny Java profiler in pure Java code that everyone can understand. Profilers are not rocket science, and ignoring safepoint-bias, we can write a usable profiler that outputs a flame graph in just 240 lines of code.
You can find the whole project on GitHub. Feel free to use it as a base for your adventures (and if you do, feel free to write me on Twitter, where I regularly post on profiling-related topics).
We implement the profiler in a daemon thread started by a Java agent. This allows us to start and run the profiler alongside the Java program we want to profile. The main parts of the profiler are:
Main: Entry point of the Java agent and starter of the profiling thread
Options: Parses and stores the agent options
Profiler: Contains the profiling loop
Store: Stores and outputs the collected results
Main Class
We start by implementing the agent entry points:
public class Main {
public static void agentmain(String agentArgs) {
premain(agentArgs);
}
public static void premain(String agentArgs) {
Main main = new Main();
main.run(new Options(agentArgs));
}
private void run(Options options) {
Thread t = new Thread(new Profiler(options));
t.setDaemon(true);
t.setName("Profiler");
t.start();
}
}
The premain is called when the agent is attached to the JVM at the start. This is typical because the user passed the -javagent to the JVM. In our example, this means that the user runs Java with
But there is also the possibility that the user attaches the agent at runtime. In this case, the JVM calls the method agentmain. To learn more about Java agent, visit the JDK documentation.
Please be aware that we have to set the Premain-Class and the Agent-Class attributes in the MANIFEST file of our resulting JAR file.
Our Java agent parses the agent arguments to get the options. The options are modeled and parsed by the Options class:
The exciting part of the Main class is its run method: The Profiler class implements the Runnable interface so that we can create a thread directly:
Thread t = new Thread(new Profiler(options));
We then mark the profiler thread as a daemon thread; this means that the JVM does terminate at the end of the profiled application even when the profiler thread is running:
t.setDaemon(true);
No, we’re almost finished; we only have to start the thread. Before we do this, we name the thread, this is not required, but it makes debugging easier.
t.setName("Profiler");
t.start();
Profiler Class
The actual sampling takes place in the Profiler class:
public class Profiler implements Runnable {
private final Options options;
private final Store store;
public Profiler(Options options) {
this.options = options;
this.store = new Store(options.getFlamePath());
Runtime.getRuntime().addShutdownHook(new Thread(this::onEnd));
}
private static void sleep(Duration duration) {
// ...
}
@Override
public void run() {
while (true) {
Duration start = Duration.ofNanos(System.nanoTime());
sample();
Duration duration = Duration.ofNanos(System.nanoTime())
.minus(start);
Duration sleep = options.getInterval().minus(duration);
sleep(sleep);
}
}
private void sample() {
Thread.getAllStackTraces().forEach(
(thread, stackTraceElements) -> {
if (!thread.isDaemon()) {
// exclude daemon threads
store.addSample(stackTraceElements);
}
});
}
private void onEnd() {
if (options.printMethodTable()) {
store.printMethodTable();
}
store.storeFlameGraphIfNeeded();
}
We start by looking at the constructor. The interesting part is
which causes the JVM to call the Profiler::onEnd when it shuts down. This is important as the profiler thread is silently aborted, and we still want to print the captured results. You can read more on shutdown hooks in the Java documentation.
After this, we take a look at the profiling loop in the run method:
We use here the Thread::getAllStackTraces method to obtain the stack traces of all threads. This triggers a safepoint and is why this profiler is safepoint-biased. Taking the stack traces of a subset of threads would not make sense, as there is no method in the JDK for this. Calling Thread::getStackTrace on a subset of threads would trigger many safepoints, not just one, resulting in a more significant performance penalty than obtaining the traces for all threads.
The result of Thread::getAllStackTraces is filtered so that we don’t include daemon threads (like the Profiler thread or unused Fork-Join-Pool threads). We pass the appropriate traces to the Store, which deals with the post-processing.
Store Class
This is the last class of this profiler and also the by far most significant, post-processing, storing, and outputting of the collected information:
package me.bechberger;
import java.io.BufferedOutputStream;
import java.io.OutputStream;
import java.io.PrintStream;
import java.nio.file.Path;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Optional;
import java.util.stream.Stream;
/**
* store of the traces
*/
public class Store {
/** too large and browsers can't display it anymore */
private final int MAX_FLAMEGRAPH_DEPTH = 100;
private static class Node {
// ...
}
private final Optional<Path> flamePath;
private final Map<String, Long> methodOnTopSampleCount =
new HashMap<>();
private final Map<String, Long> methodSampleCount =
new HashMap<>();
private long totalSampleCount = 0;
/**
* trace tree node, only populated if flamePath is present
*/
private final Node rootNode = new Node("root");
public Store(Optional<Path> flamePath) {
this.flamePath = flamePath;
}
private String flattenStackTraceElement(
StackTraceElement stackTraceElement) {
// call intern to safe some memory
return (stackTraceElement.getClassName() + "." +
stackTraceElement.getMethodName()).intern();
}
private void updateMethodTables(String method, boolean onTop) {
methodSampleCount.put(method,
methodSampleCount.getOrDefault(method, 0L) + 1);
if (onTop) {
methodOnTopSampleCount.put(method,
methodOnTopSampleCount.getOrDefault(method, 0L) + 1);
}
}
private void updateMethodTables(List<String> trace) {
for (int i = 0; i < trace.size(); i++) {
String method = trace.get(i);
updateMethodTables(method, i == 0);
}
}
public void addSample(StackTraceElement[] stackTraceElements) {
List<String> trace =
Stream.of(stackTraceElements)
.map(this::flattenStackTraceElement)
.toList();
updateMethodTables(trace);
if (flamePath.isPresent()) {
rootNode.addTrace(trace);
}
totalSampleCount++;
}
// the only reason this requires Java 17 :P
private record MethodTableEntry(
String method,
long sampleCount,
long onTopSampleCount) {
}
private void printMethodTable(PrintStream s,
List<MethodTableEntry> sortedEntries) {
// ...
}
public void printMethodTable() {
// sort methods by sample count
// the print a table
// ...
}
public void storeFlameGraphIfNeeded() {
// ...
}
}
The Profiler calls the addSample method which flattens the stack trace elements and stores them in the trace tree (for the flame graph) and counts the traces that any method is part of.
The interesting part is the trace tree modeled by the Node class. The idea is that every trace A -> B -> C (A calls B, B calls C, [C, B, A]) when returned by the JVM) can be represented as a root node with a child node A with child B with child C, so that every captured trace is a path from the root node to a leaf. We count how many times a node is part of the trace. This can then be used to output the tree data structure for d3-flame-graph which we use to create nice flamegraphs like:
Flame graph produced by the profiler for the renaissance dotty benchmark
Keep in my mind that the actual Node class is as follows:
private static class Node {
private final String method;
private final Map<String, Node> children = new HashMap<>();
private long samples = 0;
public Node(String method) {
this.method = method;
}
private Node getChild(String method) {
return children.computeIfAbsent(method, Node::new);
}
private void addTrace(List<String> trace, int end) {
samples++;
if (end > 0) {
getChild(trace.get(end)).addTrace(trace, end - 1);
}
}
public void addTrace(List<String> trace) {
addTrace(trace, trace.size() - 1);
}
/**
* Write in d3-flamegraph format
*/
private void writeAsJson(PrintStream s, int maxDepth) {
s.printf("{ \"name\": \"%s\", \"value\": %d, \"children\": [",
method, samples);
if (maxDepth > 1) {
for (Node child : children.values()) {
child.writeAsJson(s, maxDepth - 1);
s.print(",");
}
}
s.print("]}");
}
public void writeAsHTML(PrintStream s, int maxDepth) {
s.print("""
<head>
<link rel="stylesheet"
type="text/css"
href="https://cdn.jsdelivr.net/npm/d3-flame-graph@4.1.3/dist/d3-flamegraph.css">
</head>
<body>
<div id="chart"></div>
<script type="text/javascript"
src="https://d3js.org/d3.v7.js"></script>
<script type="text/javascript"
src="https://cdn.jsdelivr.net/npm/d3-flame-graph@4.1.3/dist/d3-flamegraph.min.js"></script>
<script type="text/javascript">
var chart = flamegraph().width(window.innerWidth);
d3.select("#chart").datum(""");
writeAsJson(s, maxDepth);
s.print("""
).call(chart);
window.onresize =
() => chart.width(window.innerWidth);
</script>
</body>
""");
}
}
Tiny-Profiler
I named the final profiler tiny-profiler and its sources are on GitHub (MIT licensed). The profiler should work on any platform with a JDK 17 or newer. The usage is fairly simple:
# build it
mvn package
# run your program and print the table of methods sorted by their sample count
# and the flame graph, taking a sample every 10ms
java -javaagent:target/tiny-profiler.jar=flamegraph=flame.html ...
You can easily run it on the renaissance benchmark and create the flame graph shown earlier:
The overhead for this example is around 2% on my MacBook Pro 13″ for a 10ms interval, which makes the profiler usable when you ignore the safepoint-bias.
Conclusion
Writing a Java profiler in 240 lines of pure Java is possible and the resulting profiler could even be used to analyze performance problems. This profiler is not designed to replace real profilers like async-profiler, but it demystifies the inner workings of simple profilers.
I hope you enjoyed this code-heavy blog post. As always I’m happy for any feedback, issue, or PR. Come back next week for my next blog post on profiling.
This blog post is part of my work in the SapMachine team at SAP, making profiling easier for everyone.Significant parts of this post have been written below the English channel…
In my last post, I covered a correctness bug in the fundamental Java profiling API AsyncGetCallTrace that I found just by chance. Now the question is: Could we find such bugs automatically? Potentially uncovering more bugs or being more confident in the absence of errors. I already wrote code to test the stability of the profiling APIs, testing for the absence of fatal errors, in my jdk-profiling-tester project. Such tools are invaluable when modifying the API implementation or adding a new API. This post will cover a new prototypical tool called trace_validation and its foundational concepts. I focus here on the AsyncGetCallTrace and GetStackTrace API, but due to the similarity in the code, JFR should have similar correctness properties.
The tool took far longer to bring to a usable(ish) state, this is why I didn’t write a blog post last week. I hope to be on schedule again next week.
AsyncGetCallTrace and GetStackTrace
A short recap from my blog series “Writing a Profiler from Scratch”: Both APIs return the stack trace for a given thread at a given point in time (A called B, which in turn called C, …):
AsyncGetCallTrace
The only difference is that AsyncGetCallTrace (ASGCT) returns the stack trace at any point in the execution of the program and GetStackTrace (GST) only at specific safe points, where the state of the JVM is defined. GetStackTrace is the only official API to obtain stack traces but has precision problems. Both don’t have more than a few basic tests in the OpenJDK.
Correctness
But when is the result of a profiling API deemed to be correct? If it matches the execution of the program.
This is hard to check if we don’t modify the JVM itself in general. But it is relatively simple to check for small test cases, where the most run-time is spent in a single method. We can then just check directly in the source code whether the stack trace makes sense. We come back to this answer soon.
The basic idea for automation is to compare the returns of the profiling API automatically to the returns of an oracle. But we sadly don’t have an oracle for the asynchronous AsyncGetCallTrace yet, but we can create one by weakening our correctness definition and building up our oracle in multiple stages.
Weakening the correctness definition
In practice, we don’t need the profiling APIs to return the correct result in 100% of all cases and for all frames in the trace. Typical profilers are sampling profilers and therefore approximate the result anyway. This makes the correctness definition easier to test, as it let’s us make the trade-off between feasibility and precision.
Layered oracle
The idea is now to build our oracle in different layers. Starting with basic assumptions and writing tests to verify that the layer above is probably correct too. Leading us to our combined test of asynchronous AsyncGetCallTrace. This has the advantage that every check is relatively simple, which is important, because the whole oracle depends on how much we trust the basic assumptions and the tests that verify that a layer is correct. I describe the layers and checks in the following:
Different layers of trace_validation
Ground layer
We start with the most basic assumption as our ground layer: An approximation of the stack traces can be obtained by instrumenting the byte code at runtime. The idea is to push at every entry of a method the method and its class (the frame) onto a stack and to pop it at every exit:
class A {
void methodB() {
// ...
}
}
Is transformed into:
class A {
void methodB() {
trace.push("A", "methodB");
// ...
trace.pop();
}
}
The instrumentation agent modifies the bytecode at runtime, so every exit of the method is recorded. I used the great Javassist library for the heavy lifting. We record all of this information in thread-local stacks.
This does not capture all methods, because we cannot modify native methods which are implemented in C++, but it covers most of the methods. This is what I meant by an approximation before. A problem with this is the cost of the instrumentation. We can make a trade-off between precision and usefulness by only instrumenting a portion of methods.
We can ask the stack data structure for an approximation of the current stack trace in the middle of every method. These traces are by construction correct, especially when we implement the stack data structure in native code, only exposing the Trace::push and Trace::pop methods. This limits the code reordering by the JVM.
GetStackTrace layer
This API is, as I described above, the official API to get the stack traces and it is not limited to basic stack walking, as it walks only when the JVM state is defined. One could therefore assume that it returns the correct frames. This is what I did in my previous blog post. But we should test this assumption: We can create a native Trace::check which calls GetStackTrace and checks that all frames from Trace are present and in the correct order. Calls to this method are inserted after the call to Trace::push at the beginning of methods.
There are usually more frames present in the return of GetStackTrace, but it is safe to assume that the correctness attributes approximately hold true for the whole GetStackTrace too. One could of course check the correctness of GetStackTrace at different parts of the methods. I think that this is probably unnecessary, as common Java programs call methods every few bytecode instructions.
This layer gives us now the ability to get the frames consisting of method id and location at safe points.
Safe point AsyncGetCallTrace layer
We can now use the previous layer and the fact that the result of both APIs has almost the same format, to check that AsyncGetCallTrace returns the correct result at safe points. Both APIs should yield the same results there. The check here is as simple as calling both APIs in the Trace::check method and comparing their results (omitting the location info as this is less stable). This has of course the same caveats as in the previous layer, but this is acceptable in my opinion.
If you’re curious: The main difference between the frames of both APIs is the magic number that ASGCT and GST use to denote native methods in the location field.
Async AsyncGetCallTrace layer
Our goal is to convince ourselves that AsyncGetCallTrace is safe at non safepoints under the assumption that AsyncGetCallTrace is safe at safe points (here the beginning of methods). The solution consists of two parts: The trace stack which contains the current stack trace and the sample loop which calls AsyncGetCallTrace asynchronously and compares the returns with the trace stack.
The trace stack datastructure allows to push and pop stack traces on method entry and exit. It consists of a large frames array which contains the current frames: index 0 has the bottom frame and index top contains the top most frame (the reverse order compared to AsyncGetCallTrace). The array is large enough, here 1024 entries, to be able to store stack traces of all relevant sizes. It is augmented by a previous array which contains the index of the top frame of most recent transitive caller frame of the current top frame.
Trace stack data structure used to store the stack of stack traces
We assume here that the caller trace is a sub trace of the current trace, with only the caller frame differing in the location (lineno here). This is due to the caller frame location being the beginning of the method where we obtained the trace. The calls to other methods have different locations. We mark the top frame location therefore with a magic number to state that this information changes during the execution of the method.
This allows us to store the stack of stack traces in a compact manner. We create such a data structure per thread in thread local storage. This allows us to obtain a possibly full sub trace at every point of the execution, with only the top frame location of the sub trace differing. We can use this to check the correctness of AsyncGetCallTrace at arbitrary points in time:
We create a loop in a separate thread which sends a signal to a randomly chosen running Java thread and use the signal handler to call AsyncGetCallTrace for the Java thread and to obtain a copy of the current trace stack. We then check that the result is as expected. Be aware of the synchronization.
With this we can be reasonably certain that AsyncGetCallTrace is correct enough, when all layer tests run successfully on a representative benchmark like renaissance. An prototypical implementation of all of this is my trace_validation project: It runs with the current head of the OpenJDK without any problems, except for an error rate of 0.003% percent for the last check (depending on the settings, but also with two caveats: the last check still has the problem of sometimes hanging, but I’ll hope to fix it in the next few weeks and I only tested it on Linux x86.
There is another possible way to implement the last check which I didn’t implement (yet), but which is still interesting to explore:
Variant of the Async AsyncGetCallTrace check
We can base this layer on top of the GetStackTrace layer too by exploiting the fact that GetStackTrace blocks at non safe points until a safe point is reached and then obtain the stack trace (see JBS). Like with the other variant of the check, we create a sample loop in a separate thread, pick a random Java thread, send it a signal, and then call AsyncGetCallTrace in the signal handler. But directly after sending the signal, we call GetStackTrace, to obtain a stack trace at the next safe point. The stack trace should be roughly the same as the AsyncGetCallTrace trace, as the time delay between their calls is minimal. We can compare both traces and thereby make an approximate check.
The advantage is that we don’t do any instrumentation with this approach and only record the stack traces that we really need. The main disadvantage is that it is more approximate as the time between timing of AsyncGetCallTrace and GetStackTrace is not obvious and certainly implementation and load specific. I did not yet test it, but might do so in the future because the setup should be simple enough to add it to the OpenJDK as a test case.
Update 20th March: I implemented this variant (and it will be soon the basis of a JTREG test) and found an error related to custom class loaders.
Update 21st March: I implemented the reduced version in a stand-alone agent that can be found on GitHub.
Conclusion
I’ve shown you in this article how we can test the correctness of AsyncGetCallTrace automatically using a multi level oracle. The implementation differs slightly and is more complicated then expected, because of the percularities of writing an instrumentation agent with a native agent and a native library.
I’m now fairly certain that AsyncGetCallTrace is correct enough and hope you’re too. Please try out the underlying project and come forward with any issues or suggestions.
This blog post is part of my work in the SapMachine team at SAP, making profiling easier for everyone.
Profilers are great tools in your toolbox, like debuggers, when solving problems with your Java application (I’ve been on a podcast on this topic recently). I’ll tell you some of their problems and a technique to cope with them in this blog post.
There are many open-source profilers, most notably JFR/JMC, and async-profiler, that help you to find and fix performance problems. But they are just software themself, interwoven with a reasonably large project, the OpenJDK (or OpenJ9, for that matter), and thus suffer from the same problems as the typical problems of application they are used to profile:
Tests could be better
Performance and accuracy could be better
Tests could be more plentiful, especially for the underlying API, which could be tested well
Changes in seemingly unrelated parts of the enclosing project can adversely affect them
Therefore you take the profiles generated by profilers with a grain of salt. There are several blog posts and talks covering the accuracy problems of profilers:
I would highly recommend you to read my Writing a profiler from scratch series If you want to know more about how the foundational AsyncGetCallTrace is used in profilers. Just to list a few.
A sample AsyncGetCallTraceTrace bug
A problem that has been less discussed is the lacking test coverage of the underlying APIs. The AsyncGetCallTrace API, used by async-profiler and others, has just one test case in the OpenJDK (as I discussed before). This test case can be boiled down to the following:
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class Main {
static { /** load native library */ }
public static void main(String[] args) throws Exception {
Class<?> klass = Main.class;
Method mainMethod = klass.getMethod("test");
mainMethod.invoke(null);
}
public static void test() {
if (!checkAsyncGetCallTraceCall()) {
throw ...;
}
}
public static native boolean checkAsyncGetCallTraceCall();
}
This is the simplest test case that can be written in the OpenJDK JTREG test framework for OpenJDK. The problem with this test case? The implementation of checkAsyncGetCallTraceCall only checks for the topmost frame. To test AsyncGetCallTrace correctly here, one should compare the trace returned by this call with the trace of an oracle. We can use GetStackTrace (the safepoint-biased predecessor of ASGCT) here as it seems to return the correct trace.
GetStackTrace returns something like the following:
This problem can be observed with a modified test case with JFR and async-profiler too:
public class Main {
public static void main(String[] args) throws Exception {
Class<?> klass = Main.class;
Method mainMethod = klass.getMethod("test");
mainMethod.invoke(null);
}
public static void test() {
javaLoop();
}
public static void javaLoop() {
long start = System.currentTimeMillis();
while (start + 3000 > System.currentTimeMillis());
}
}
The expected flame graph is on the left (obtained after fixing the bug), and the actual flame graph is on the right.
So the only test case on AsyncGetCallTrace in the OpenJDK did not properly test the whole trace. This was not a problem when the test case was written. One can expect that its author checked the entire stack trace manually once and then created a small check test case to test the first frame, which is not implementation specific. But this is a problem for regression testing:
The Implementation of JEP 416: Reimplement Core Reflection with Method Handle in JDK 18+23 in mid-2021 modified the inner workings of reflection and triggered this bug. The lack of proper regression tests meant the bug had only been discovered a week ago. The actual cause of the bug is more complicated and related to a broken invariant regarding stack pointers in the stack walking. You can read more on this in the comments by Jorn Vernee and Richard Reingruber to my PR.
My PR improves the test by checking the result of AsyncGetCallTrace against GetStackTrace, as explained before, and fixing the bug by slightly loosening the invariant.
My main problem with finding this bug is that it shows how the lack of test coverage for the underlying profiling APIs might cause problems even for profiling simple Java code. I only found the bug because I’m writing many tests for my new AsyncGetStackTrace API. It’s hard work, but I’m convinced this is the only way to create a reliable foundation for profilers.
Profilers in a loop
Profilers have many problems but are still helpful if you know what they can and cannot do. They should be used with care, without trusting everything they tell you. Profilers are only as good as the person interpreting the profiler results and the person’s technique.
I have a background in computer science, and every semester I give students in a paper writing lab an hour-long lecture on doing experiments. I started this a few years back and continue to do it pro-bono because it is an important skill to teach. One of the most important things that I teach the students is that doing experiments is essentially a loop:
You start with an abstract model of the experiment and its environment (like the tool or algorithm you’re testing). Then you formulate a hypothesis in this model (e.g., “Algorithm X is faster as Y because of Z”). You might find problems in your model during this step and go back to the modeling step, or you don’t and start evaluating, checking whether the hypothesis holds. During this evaluation, you might find problems with your hypothesis (e.g., it isn’t valid) or even your model and go back to the respective step. Besides problems, you usually find new information that lets you refine your model and hypothesis. Evaluating without a mental model or a hypothesis makes it impossible to interpret the evaluation results correctly. But remember that a mismatch between hypothesis and evaluation might also be due to a broken evaluation.
The same loop can be applied to profiling: Before investigating any issue with a program, you should acquire at least a rough mental model of the code. This means understanding the basic architecture, performance-critical components, and the issues of the underlying libraries. Then you formulate a hypothesis based on the problem you’re investigating embedded in your mental model (e.g., “Task X is slow because Y is probably slow …”). You can then evaluate the hypothesis using actual tests and a profiler. But as before, remember that your evaluation might also contain bugs. You can only discover these with a mental model and a reasonably refined hypothesis.
This technique lets you use profilers without fearing that spurious errors will lead you to wrong conclusions.
I hope you found this article helpful and educational. It is an ongoing effort to add proper tests and educate users of profilers. See you in the next post when I cover the next step in writing a profiler from scratch.
This blog post is part of my work in the SapMachine team at SAP, making profiling easier for everyone.
Did you ever wonder whether JFR timestamps use the same time source as System.nanoTime? This is important when you have miscellaneous logging besides JFR events; otherwise, you could not match JFR events and your logging properly. We assume here that you use System.nanoTime and not less-suited timing information from System.currentTimeMillis.
The journey into this started with a question on the JDK Mission Control slack channel, which led me into a rabbit hole:
Could I have a question regarding JFR timestamps? (working with Linux) Is there any difference between JFR timestamp implementation and System#nanoTime (any optimization)?
Petr Bouda
This question essentially boils down to comparing both methods’ OS time sources. We’re only considering Unix systems in the following.
Source of JFR timestamps
The JFR event time stamps are set in the JFR event constructor, which is defined in jfrEvent.hpp (and not in the Java code, as one might expect):
The RDTSC instruction reads the time stamp counter on x86 processors:
The time stamp counter (TSC) is a hardware counter found in all contemporary x86 processors. The counter is implemented as a 64-bit model-specific register (MSR) that is incremented at every clock cycle. The RDTSC (“read time stamp counter”) register has been present since the original Pentium.
Already because of the access method, TSC provides a low-overhead and high-resolution way to obtain CPU timing information. This traditional premise was violated when such factors as system sleep states, CPU “hotplugging”, “hibernation”, and CPU frequency scaling were introduced to the x86 lineage. This was however mainly a short abruption: in many new x86 CPUs the time stamp counter is again invariant with respect to the stability of the clock frequency. Care should be however taken in implementations that rely on this assumption.
Returns current value of a clock that increments monotonically in tick units (starting at an arbitrary point), this clock does not increment while the system is asleep.
Information on the implementation of this method is scarce, but source code from 2007 suggests that mach_absolute_time is RDTSC based. So there is (probably) no difference between JFR timestamps and System.nanoTime on Mac OS, regardless of the CPU architecture.
Now on Linux: Here, the used os::javaTimeNanosis implemented using clock_gettime(CLOCK_MONOTONIC, ...):
CLOCK_MONOTONIC Clock that cannot be set and represents monotonic time since some unspecified starting point.
I tried to find something in the Linux Kernel sources, but they are slightly too complicated to find the solution quickly, so I had to look elsewhere. Someone asked a question on clock_gettime on StackOverflow. The answers essentially answer our question too: clock_gettime(CLOCK_MONOTONIC, ...) seems to use RDTSC.
Conclusion
JFR timestamps and System.nanoTime seem to use the same time source on all Unix systems on all platforms, as far as I understand it.
You can stop the JVM from using RDTSC by using the -XX:+UnlockExperimentalVMOptions -XX:-UseFastUnorderedTimeStamps JVM flags (thanks to Richard Startin for pointing this out). You can read Markus Grönlunds Mail on Timing Differences Between JFR and GC Logs for another take on JFR timestamps (or skip ahead):
JFR performance as it relates to event generation, which is also functional for JFR, reduce to a large extent to how quickly a timestamp can be acquired. Since everything in JFR is an event, and an event will have at least one timestamp, and two timestamps for events that represent durations, the event generation leans heavily on the clock source. Clock access latencies is therefore of central importance for JFR, maybe even more so than correctness. And historically, operating systems have varied quite a bit when it comes to access latency and resolution for the performance timers they expose.
What you see in your example is that os::elapsed_counter() (which on Windows maps to QueryPerformanceCounter() with a JVM relative epoch offset) and the rdtsc() counter are disjoint epochs, and they are treated as such in Hotspot. Therefore, attempting to compare the raw counter values is not semantically valid.
Relying on and using rdtsc() come with disclaimers and problems and is generally not recommended. Apart from the historical and performance related aspects already detailed, here is a short description of how it is treated in JFR:
JFR will only attempt to use this source if it has the InvariantTSC property, with timestamp values only treated relative to some other, more stable, clock source. Each “chunk” (file) in JFR reifies a relative epoch, with the chunk start time anchored to a stable timestamp (on Windows this is UTC nanoseconds). rdtsc() timestamps for events generated during that epoch are only treated relative to this start time during post-processing, which gives very high resolution to JFR events. As JFR runs, new “chunks”, and therefore new time epochs, are constructed, continuously, each anchored anew to a stable timestamp.
The nature of rdtsc() querying different cores / sockets with no guarantee of them having been synchronized is of course a problem using this mechanism. However, over the years, possible skews have proven not as problematic as one might think in JFR. In general, the relative relations between the recorded JFR events give enough information to understand a situation and to solve a problem. Of course, there are exceptions, for example, when analyzing low-level aspects expecting high accuracy, usually involving some correlation to some other non-JFR related component. For these situations, an alternative is to turn off rdtsc() usages in JFR using the flags: -XX:+UnlockExperimentalVMOptions -XX:-UseFastUnorderedTimeStamps. JFR will now use os::elapsed_counter() as the time source. This comes with higher overhead, but if this overhead is not deemed problematic in an environment, then this is of course a better solution.
As other have already pointed out, there have been evolution in recent years in how operating systems provide performance counter information to user mode. It might very well be that now the access latencies are within acceptable overhead, combined with high timer resolution. If that is the case, the rdtsc() usages should be phased out due to its inherent problems. This requires a systematic investigation and some policy on how to handle older HW/SW combinations – if there needs to be a fallback to continue to use rdtsc(), it follows it is not feasible to phase it out completely.
Difference between System.currentTimeMillis and System.nanoTime
This is not directly related to the original question, but nonetheless interesting. System.currentTimeMillis is implemented using clock_gettime(CLOCK_REALTIME, ...) on all CPU architectures:
CLOCK_REALTIME System-wide realtime clock. Setting this clock requires appropriate privileges.
CLOCK_REALTIME represents the machine’s best-guess as to the current wall-clock, time-of-day time. […] this means that CLOCK_REALTIME can jump forwards and backwards as the system time-of-day clock is changed, including by NTP.
CLOCK_MONOTONIC represents the absolute elapsed wall-clock time since some arbitrary, fixed point in the past. It isn’t affected by changes in the system time-of-day clock.
So does it make a difference? Probably only slightly, especially if you’re running shorter profiling runs. For longer runs, consider using System.nanoTime.
I hope you enjoyed coming down this rabbit hole with me and learned something about JFR internals along the way.
This blog post is part of my work in the SapMachine team at SAP, making profiling easier for everyone.
I detailed in my last blog post how the Firefox Profiler can be used to view Java profiling data:
But I’m of course not the only one who uses Firefox Profiler beyond the web, because using it has many advantages: You’re essentially getting a prototypical visualization for your data in an afternoon.
Other tools that use Firefox Profiler
There are other tools that output use Firefox Profiler for their front end. A great example is the Rust profiler samply by Markus Stange, the initial developer of Firefox Profiler:
samply is a command line CPU profiler which uses the Firefox profiler as its UI.
At the moment it runs on macOS and Linux. Windows support is planned. samply is still under development and far from finished, but works quite well already.
Give it a try:
% cargo install samply
% samply record ./your-command your-arguments
Another example is the python profiler FunctionTrace:
A graphical Python profiler that provides a clear view of your application’s execution while being both low-overhead and easy to use.
FunctionTrace supports all of the useful profiling views you’re familiar with, including Stack Charts, Flame Graphs, and Call Trees, thanks to its integration with the Firefox Profiler.
There are also non-open source uses of Firefox Profiler, Luís Oliveira, for example, works on integration with Lisp:
We’re using the Firefox Profiler to debug performance issues at the Dutch Railways dispatching center.
Basic Structure
I hope I convinced you that the Firefox Profiler is really great for visualizing profiling data, even if this data comes from the world beyond web UIs. If not, please read my previous article. The main part of adapting to Firefox Profiler is to convert your data into the profiler format. The data is stored as JSON in a (optionally zipped) file and can be loaded into Firefox Profiler. See Loading in profiles from various sources for more information.
The basic structure of a tool using Firefox Profiler can be as follows, using my plugin as an example:
You have a converter from your profile format to the Firefox Profiler format. The converted file is then passed to the Firefox Profiler, either from profiler.firefox.com or a custom fork. You typically then wrap your UI and the converter, hosting both on a small webserver. This web server runs then on e.g. localhost. Hosting your own Firefox Profiler instance has two main advantages: First, you have always a tested combination of Firefox Profiler and Converter. Second, it works offline. The web server can then be embedded into a larger application, showing the UI using an embedded browser.
You can find the type definitions in the types folder of the Firefox Profiler repository. All of the following will be based on this. This part of the article will not focus on all the details, like markers, but more on a bird’s eye view of the format, so it will probably still apply with future revisions. I’ll also omit parts that are not that useful for non-web use cases. If you have any questions on the file format, feel free to ask them in the matrix channel.
The type definitions are written with flow. It is helpful to read its documentation if you want to understand the intricacies. But for now, it should suffice to know that x?: type means that the property x is optional and that | denotes either types.
Layout
A short interlude: The layout of Firefox Profiler consists basically of a timeline view and a methods and timing view:
The timeline allows you to select specific threads and a time slice to view the details in the detail section below the timeline.
Overview
The following shows the main components of the profile format, omitting and summarizing many properties. This diagram should give a rough overview of what comes next:
Profile
The topmost level of a profile is the Profile type:
type Profile = {|
meta: ProfileMeta, // meta information, like application name
libs: Lib[], // used shared native libraries
...
counters?: Counter[], // CPU and memory counters
...
threads: Thread[], // samples per thread
...
|};
A profile consists of the metadata, shared libraries, CPU and memory counters, and the rest of the data per thread.
ProfileMeta
A profile can have lots of metadata shown in the UI. The ProfileMeta type specifies this:
type ProfileMeta = {|
// The interval at which the threads are sampled.
interval: Milliseconds,
// The number of milliseconds since midnight January 1, 1970 GMT.
startTime: Milliseconds,
// The number of milliseconds since midnight January 1, 1970 GMT.
endTime?: Milliseconds,
...
// The list of categories as provided by the platform. The categories are present for
// all Firefox profiles, but imported profiles may not include any category support.
// The front-end will provide a default list of categories, but the saved profile
// will not include them.
categories?: CategoryList,
// The name of the product, most likely "Firefox".
product: 'Firefox' | string,
...
// Arguments to the program (currently only used for imported profiles)
arguments?: string,
...
// The amount of logically available CPU cores for the program.
logicalCPUs?: number,
...
symbolicated?: boolean, // usually false for imported profiles
symbolicationNotSupported?: boolean, // usually true for imported profiles
// symbolication is usually not important for imported and converted profiles
...
// Profile importers can optionally add information about where they are imported from.
// They also use the "product" field in the meta information, but this is somewhat
// ambiguous. This field, if present, is unambiguous that it was imported.
importedFrom?: string,
// The following are settings that are used to configure the views for
// imported profiles, as some features do not make sense for them
// Do not distinguish between different stack types?
usesOnlyOneStackType?: boolean, // true in our use case
// Hide the "implementation" information in the UI (see #3709)?
doesNotUseFrameImplementation?: boolean, // true in our use case
// Hide the "Look up the function name on Searchfox" menu entry?
sourceCodeIsNotOnSearchfox?: boolean, // true in our use case
// Indexes of the threads that are initially visible in the UI.
// This is useful for imported profiles for which the internal visibility score
// ranking does not make sense.
initialVisibleThreads?: ThreadIndex[],
// Indexes of the threads that are initially selected in the UI.
// This is also most useful for imported profiles where just using the first thread
// of each process might not make sense.
initialSelectedThreads?: ThreadIndex[],
// Keep the defined thread order
keepProfileThreadOrder?: boolean,
|};
And there is more. It might feel overwhelming, but this data structure also allows you to tailor the profiler UI slightly to your needs.
Category
Many parts of the profile are associated with a Category and a subcategory. A category is defined as:
Categories are referenced by their index in the category list of the ProfileMeta data structure and subcategories by their index in the field of their parent category.
The categories are used to assign a color to the squares in front of the method names and give more information on every call tree node in the sidebar:
Now to the individual threads:
Thread
The thread data structure combines all information related to a single thread. There can be multiple threads per process Id. The thread with the name GeckoMain is handled differently than the others. It is the main thread that is shown in the process timeline.
type Thread = {|
...
processStartupTime: Milliseconds,
processShutdownTime: Milliseconds | null,
registerTime: Milliseconds,
unregisterTime: Milliseconds | null,
...
name: string,
...
pid: Pid,
tid: Tid,
...
// Strings for profiles are collected into a single table, and are referred to by
// their index by other tables.
stringTable: UniqueStringArray,
...
samples: SamplesTable,
...
stackTable: StackTable,
frameTable: FrameTable,
funcTable: FuncTable,
resourceTable: ResourceTable,
...
|};
The file format stores all stack traces in a space-efficient format which the front end can handle fast. It uses an array of strings (stringTable) to store all strings that appear in the stack traces (like function names), the other data structures only refer to strings by their index in this array.
SampleS Table
This data structure associates a captured stack with a capture time and an optional weight:
/**
* The Gecko Profiler records samples of what function was currently being executed, and
* the callstack that is associated with it. This is done at a fixed but configurable
* rate, e.g. every 1 millisecond. This table represents the minimal amount of
* information that is needed to represent that sampled function. Most of the entries
* are indices into other tables.
*/
type SamplesTable = {|
...
stack: Array<IndexIntoStackTable | null>,
time: Milliseconds[],
// An optional weight array. If not present, then the weight is assumed to be 1.
// See the WeightType type for more information.
weight: null | number[],
weightType: WeightType, // 'samples' or 'tracing-ms'
// CPU usage value of the current thread. Its values are null only if the back-end
// fails to get the CPU usage from operating system.
threadCPUDelta?: Array<number | null>,
length: number,
|};
Filling this with data from a sampling profiler is easy, just add references to the stacks and their occurrence time. For example consider you sampled the stack A-B at 0 and A-B-C at 2, then the samples table is:
Filling the threadCPUDelta property allows you to specify the CPU time a thread has used since the last sample. The Firefox Profiler uses this property to show the CPU usage curves in the timeline:
Stack Table
All stacks are stored in the stack table using a prefix array:
type StackTable = {|
frame: IndexIntoFrameTable[],
// Imported profiles may not have categories. In this case fill the array with 0s.
category: IndexIntoCategoryList[],
subcategory: IndexIntoSubcategoryListForCategory[],
prefix: Array<IndexIntoStackTable | null>,
length: number,
|};
Category and subcategory of a stack n gives information on the whole stack, the frame just on its topmost frame. The prefix denotes the stack related to the second-top-most frame or that this stack only has one frame if null. This allows the efficient storage of stacks.
Now consider our example from before. We could store the stack A-B-C as follows:
StackTable = {
frame: [A, B, C], // references into the frame table
prefix: [1, 2, 0],
...
}
Frame Table
The frames themselves are stored in the frame table:
/**
* Frames contain the context information about the function execution at the moment in
* time. The caller/callee relationship between frames is defined by the StackTable.
*/
type FrameTable = {|
// If this is a frame for native code, the address is the address of the frame's
// assembly instruction, relative to the native library that contains it.
address: Array<Address | -1>,
// The inline depth for this frame. If there is an inline stack at an address,
// we create multiple frames with the same address, one for each depth.
// The outermost frame always has depth 0.
inlineDepth: number[],
category: (IndexIntoCategoryList | null)[],
subcategory: (IndexIntoSubcategoryListForCategory | null)[],
func: IndexIntoFuncTable[],
...
line: (number | null)[],
column: (number | null)[],
length: number,
|};
Each frame is related to a function, which is in turn stored in the FuncTable.
Func Table
The function table stores all functions with some metadata:
type FuncTable = {|
// The function name.
name: Array<IndexIntoStringTable>,
// isJS and relevantForJS describe the function type. Non-JavaScript functions
// can be marked as "relevant for JS" so that for example DOM API label functions
// will show up in any JavaScript stack views.
// It may be worth combining these two fields into one:
// https://github.com/firefox-devtools/profiler/issues/2543
isJS: Array<boolean>,
relevantForJS: Array<boolean>,
// The resource describes "Which bag of code did this function come from?".
// For JS functions, the resource is of type addon, webhost, otherhost, or url.
// For native functions, the resource is of type library.
// For labels and for other unidentified functions, we set the resource to -1.
resource: Array<IndexIntoResourceTable | -1>,
// These are non-null for JS functions only. The line and column describe the
// location of the *start* of the JS function. As for the information about which
// which lines / columns inside the function were actually hit during execution,
// that information is stored in the frameTable, not in the funcTable.
fileName: Array<IndexIntoStringTable | null>,
lineNumber: Array<number | null>,
columnNumber: Array<number | null>,
length: number,
|};
Resource Table
The last table I’ll show in this article is the resource table. It depends on you and what you map to it:
/**
* The ResourceTable holds additional information about functions. It tends to contain
* sparse arrays. Multiple functions can point to the same resource.
*/
type ResourceTable = {|
length: number,
...
name: Array<IndexIntoStringTable>,
...
// 0: unknown, library: 1, addon: 2, webhost: 3, otherhost: 4, url: 5
type: resourceTypeEnum[],
|};
This was quite a technical article, so thanks for reading till the end. I hope it helps you when you try to target the Firefox Profiler, and see you for the next blog post.
This blog post is part of my work in the SapMachine team at SAP, making profiling easier for everyone.